Tongyi Lab opened Fun-CineForge with multi-speaker dubbing, temporal modality for off-screen or blocked faces, and a full dataset-building pipeline. It matters for dialogue and localization workflows that break on hard cuts, overlapping speech, or missing lip cues.
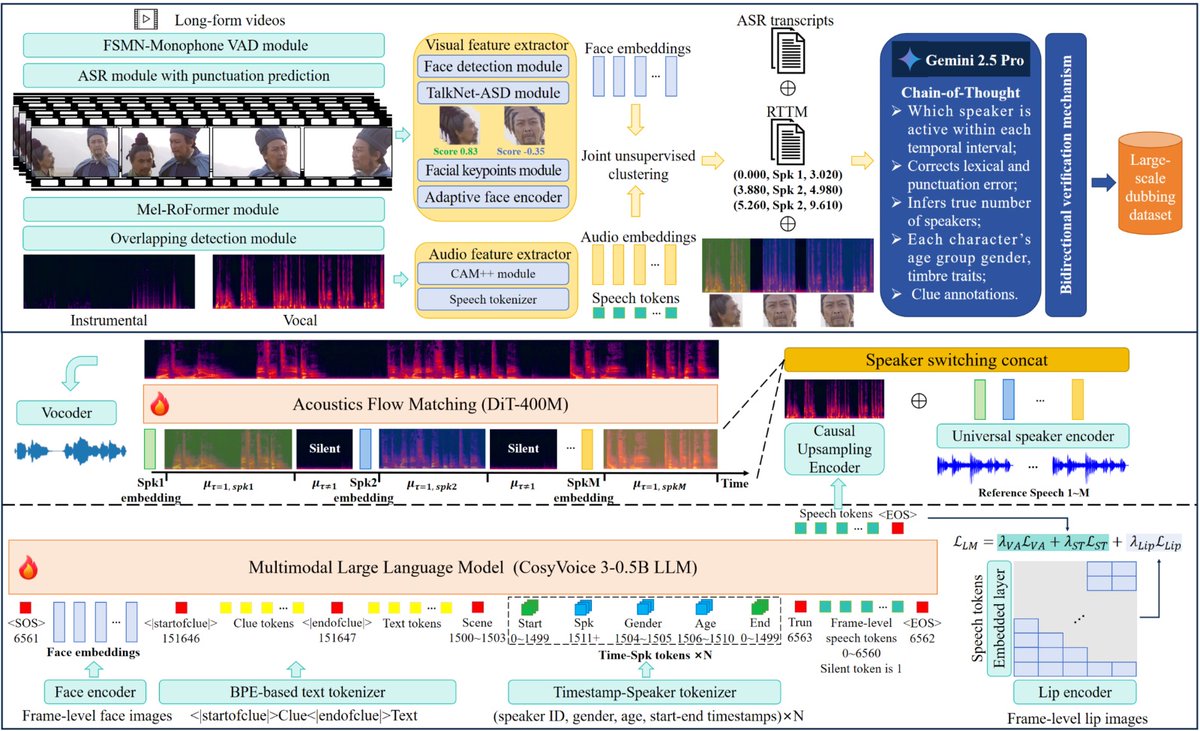
Fun-CineForge is more than a dubbing checkpoint. The project thread points to both a GitHub repo and a project page, and says the release includes an end-to-end production pipeline for building dubbing datasets from raw video. That matters because the same thread says existing dubbing data is often small, error-prone, expensive to label, and skewed toward monologues rather than conversations.
On the modeling side, the release centers on “temporal modality.” In Tongyi Lab’s framing, the model is meant to infer speaker identity, timing, and rhythm even when faces are missing, which is the gap that usually breaks lip-driven dubbing systems temporal modality. The launch materials position it for narration, monologues, and multi-speaker dialogue rather than a single narrow use case.
The creative use case is not basic voice swap. The launch demo argues that multi-speaker dubbing gets hard when a character is off-screen, the camera cuts fast, faces are blocked or blurred, or several people talk in the same scene launch thread. Those are common conditions in film scenes, trailers, interviews, and localized social video, where editors cannot depend on clean frontal lip cues.
The second practical angle is data creation. Tongyi Lab says the pipeline automates raw-video-to-annotation prep, so teams can assemble their own multimodal dubbing datasets instead of waiting for a clean public corpus dataset pipeline. For creators working on dialogue localization, that makes this release look as much like infrastructure as a model drop.
Ready to try it? GitHub: github.com/FunAudioLLM/Fu… Fun-CineForge Homepage: funcineforge.github.io The future of cinematic AI dubbing is HERE. And it's OPEN SOURCE. #TongyiLab #AI #OpenSource #Dubbing #MachineLearning #Cinematic
Here's the breakthrough: TEMPORAL MODALITY Fun-CineForge is the FIRST OPEN-SOURCE AI dubbing model to introduce this. Instead of just looking at lips, it understands: ✅ WHO is speaking ✅ WHEN they're speaking ✅ HOW the rhythm changes Even when faces are MISSING. That's the Show more
"AI dubbing? That's easy, right? Just match the voice to the lips." That's what most people think. But here's the thing: multi-speaker dubbing is actually ONE OF THE HARDEST problems in AI video. And Tongyi Lab just solved it. World's FIRST OPEN-SOURCE AI dubbing model that Show more
But wait, there's MORE. They're also open-sourcing the complete END-TO-END pipeline. Why? Because quality datasets are: 📉 Limited in scale 📉 Full of errors 📉 Expensive to label 📉 Restricted to monologues This pipeline automates dataset creation from raw video → Show more
