Cursor published its internal benchmarking approach and reported wider separation between coding models than SWE-bench-style leaderboards show. Use it as a reference for production routing decisions, but validate results against your own online traffic and task mix.
Cursor's methodology post says CursorBench is drawn from real sessions from its own engineering team, with tasks meant to reflect multi-file, multi-step development work instead of isolated puzzle-style prompts. The company says scoring is not limited to binary correctness; it also tracks code quality, efficiency, and interaction behavior, then checks online traffic for regressions so offline wins still match actual developer experience. The launch thread summarizes that as a mix of "offline benchmarks and online evals."
That matters because Cursor is arguing public benchmarks are getting less decision-useful for routing and model selection. In Katz's post, he says the team had been "coy for a while about the actual scores" and is now publishing more of the underlying evaluation logic and results.
The first charts make two claims. First, the benchmark comparison shows much larger separation than SWE-bench Verified: Opus 4.6, GPT-5.2, and Gemini 3.1 all sit within about a point of each other on SWE-bench, but spread more clearly on CursorBench, where Opus 4.6 leads at 58.2 and Haiku 4.5 lands at 29.4. That supports Cursor's case that benchmark saturation can hide practical differences between coding models.
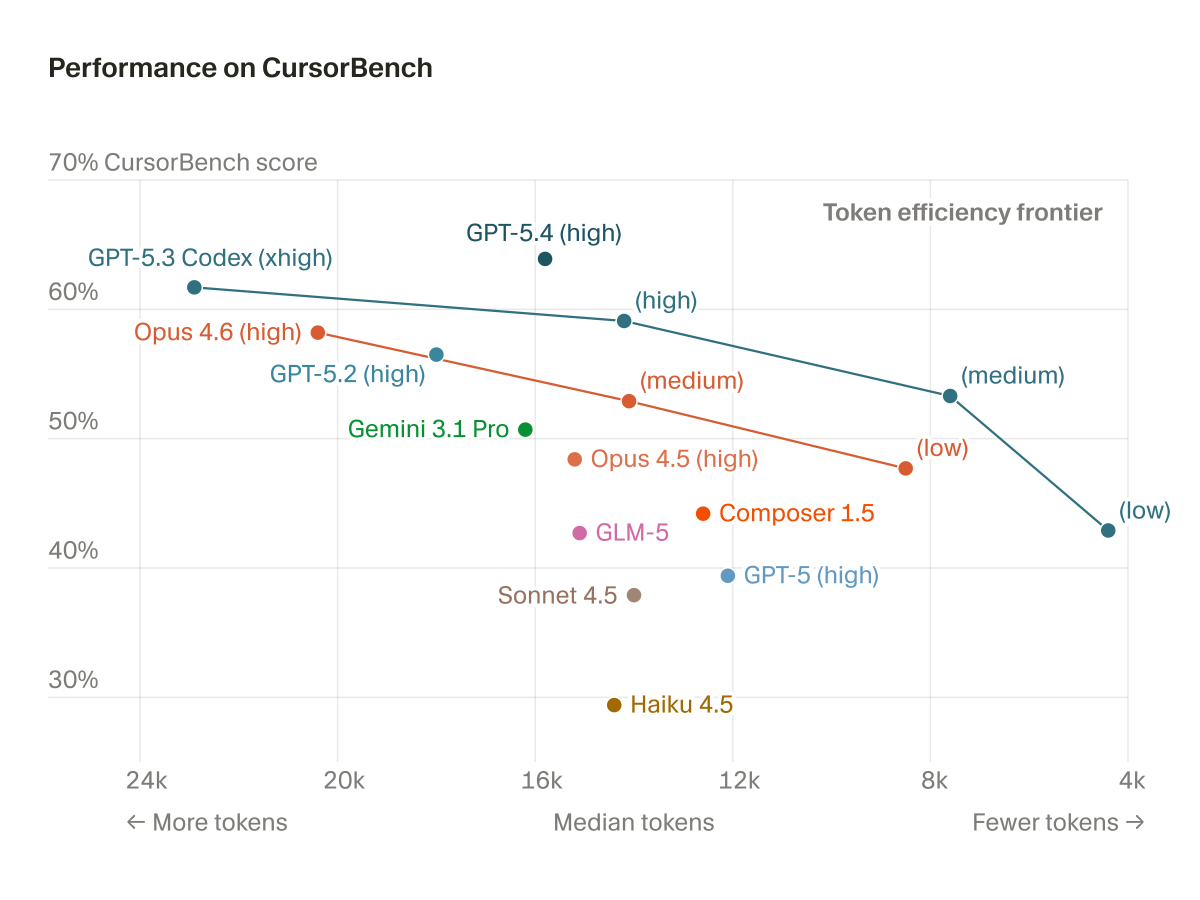
Second, the token-efficiency chart makes cost-performance tradeoffs visible instead of reporting one score per model. GPT-5.3 Codex xhigh sits near the top score band but at roughly 24k tokens, while GPT-5.4 high lands slightly lower on score at about 16k tokens and is presented as part of the efficiency frontier. A brief OpenAI developer account reaction distilled that as "leads CursorBench on correctness with efficient token usage", though the underlying chart is more specific: it highlights frontier placement, not a single universal winner across every operating point.
Learn more: cursor.com/blog/cursorben…
This post about our evals at Cursor has been a long time coming (and much more to share in future). We've been coy for a while about the actual scores, here is much more transparency. Thanks @StringChaos for great work on evals and the blog!
We're sharing a new method for scoring models on agentic coding tasks. Here's how models in Cursor compare on intelligence and efficiency:

We're sharing a new method for scoring models on agentic coding tasks. Here's how models in Cursor compare on intelligence and efficiency:
Insane!

We're sharing a new method for scoring models on agentic coding tasks. Here's how models in Cursor compare on intelligence and efficiency:
