Stanford's `jai` package launches casual, strict, and bare Linux containment modes for AI agents, and users pair the idea with Claude Code and OpenClaw hardening tips. The workflow narrows write scope and reduces persistent exploit paths such as hooks, `.venv` files, and startup artifacts.
. while denying ~/ and /.Posted by mazieres
jai is a super-lightweight Linux sandbox developed by Stanford Secure Computer Systems research group for safely running AI agents. It provides effortless containment with one command, offering modes like casual (copy-on-write home overlay), strict (unprivileged user, empty home), and bare (hidden home). Protects filesystem integrity by limiting writes outside working directory, uses private PID namespace and tmp dirs. Free software, not a full container replacement.
Jai packages a tighter default boundary around local coding agents with a one-command Linux sandbox aimed at filesystem containment rather than full VM- or container-level replacement. The launch page says “casual” keeps your home available through a copy-on-write overlay, “strict” runs as an unprivileged user with an empty home, and “bare” hides home entirely. Across modes, the design centers on limiting writes outside the current working directory and giving the process private PID and temp space.
That maps closely to how developers are already hardening agent runs. In the HN discussion, one practitioner shared a Claude Code sandbox policy that sets allowRead and allowWrite to . while denying ~/ and /, which is the same narrow-scope pattern in tool-specific form. Another commenter said there are “all kinds of files” an agent could write and later get executed, including “.pyc,” “.venv,” and Git hooks risk thread, which explains why simple write restrictions matter even when an agent is only supposed to touch a repo.
Posted by mazieres
Thread discussion highlights: - AnotherGoodName on Claude Code sandbox config: Add this to .claude/settings.json ... "sandbox": { "enabled": true, "filesystem": { "allowRead": ["."], "denyRead": ["~/"], "allowWrite": ["."], "denyWrite": ["/"] } } - rsyring on persistent exploit risk: There are all kinds of files that the agent could write to that I'd end up executing ... Every .pyc file for instance, files in .venv, .git hook files. - kstenerud on diff-based workflow: The agent runs inside a Docker container ... When it's done, `yoloai diff` gives you a unified diff ... `yoloai apply` lands it. `yoloai reset` throws it away.
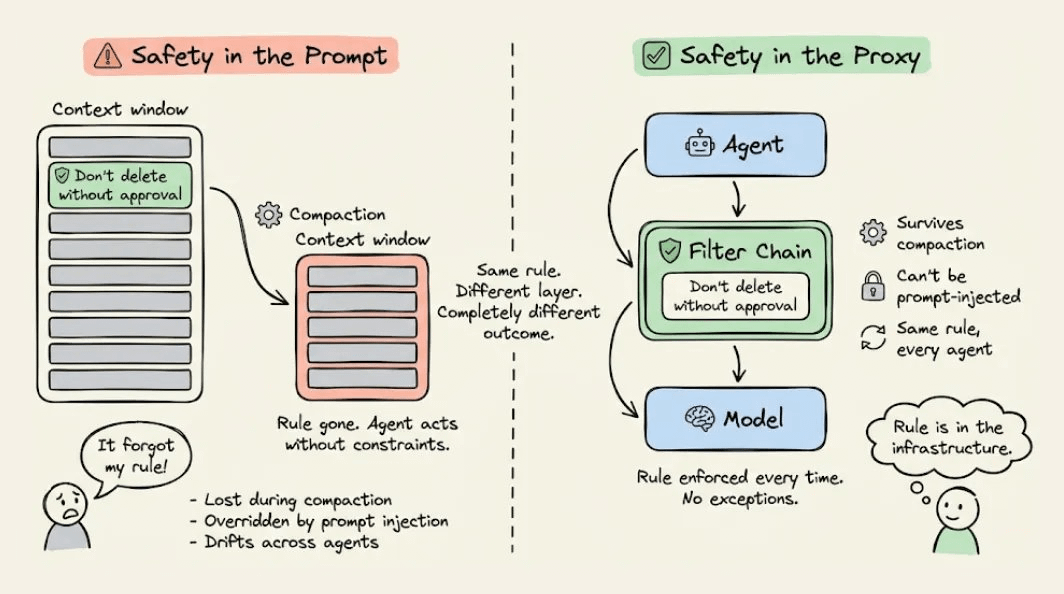
The thread also showed where teams may go further than jai's built-in model. One workflow runs the agent in Docker, then surfaces a unified diff for review before apply, with reset to discard the session diff workflow. A separate supporting post argued safety rules should live in a proxy layer the agent “can't touch,” not only in the prompt context proxy-layer tip. Together, the early reaction frames jai less as a brand-new security model than as a simpler entry point into the containment patterns operators were already piecing together by hand.
Posted by mazieres
Relevant as a practical security/workflow thread for running coding agents: it compares filesystem sandboxes, separate-user setups, containers/VMs, and diff-based apply/reset workflows, with specific concern for persistent exploit paths like hooks and virtualenv artifacts.