Mistral's Voxtral TTS splits speech into semantic and acoustic tokens, uses a low-bitrate codec, and claims a 68.4% win rate over ElevenLabs Flash v2.5 on voice cloning with about 3-25 seconds of reference audio. The architecture targets multilingual cloning and higher-quality speech without a fully autoregressive audio stack, so voice teams should compare it against current TTS pipelines.
Mistral is positioning Voxtral TTS as an open-weights voice model rather than a closed API-only release. The thread points to both the research paper and model weights, and describes the model as expressive, multilingual, and optimized for short-reference voice cloning rather than long enrollment clips paper and weights.
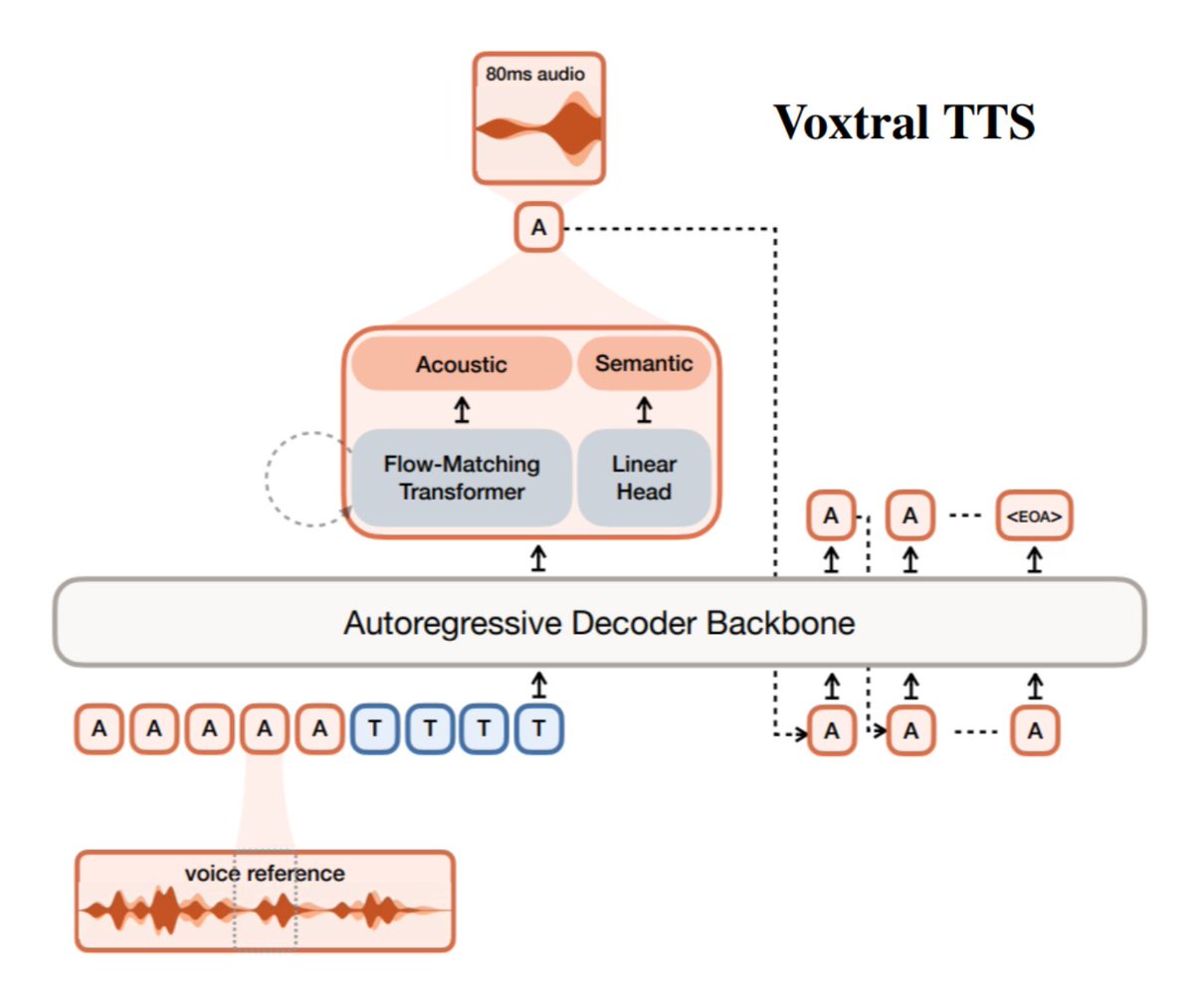
The headline product claim is that Voxtral separates "what you say" from "how you sound" launch thread. That matters for teams building voice agents because it turns cloning and speech generation into partially independent problems: text content is modeled as semantic tokens, while speaker identity, tone, and prosody are modeled as acoustic tokens architecture post. The same launch thread says this setup supports 9 languages and beat ElevenLabs Flash v2.5 with a 68.4% win rate on voice cloning launch thread.
Voxtral avoids a fully autoregressive audio stack. In The Turing Post's summary, the semantic side uses a decoder-only autoregressive transformer for long-range linguistic coherence, while the acoustic side uses flow matching to recover richer speech detail architecture post. That split is backed by Voxtral Codec, which compresses speech into a very small token budget: 1 semantic token, 36 acoustic tokens, a 12.5 Hz frame rate, and about 2.14 kbps total codec details.
The training recipe is split the same way. The training note says semantic tokens are trained with ASR distillation to match linguistic structure, while acoustic tokens are modeled continuously with flow matching and can produce high-quality audio in roughly 8 steps. A follow-up post adds that preference optimization was extended across both halves, using a discrete objective for semantic tokens and a continuous one for acoustic tokens DPO detail. For engineering teams, the practical change is clear: Voxtral is not just another speaker-cloning front end, but a modular TTS stack that tries to improve controllability and synthesis quality by decomposing content and voice generation.
.@MistralAI's new Voxtral TTS generates expressive, multilingual speech from just ~3 seconds of reference audio It solves one of the hardest problems in speech, separating what you say from how you sound ➡️ Voxtral factorizes speech into two parts: • semantic tokens → the Show more

1. The key design choice Voxtral doesn't model everything autoregressively, it splits the problem: - A decoder-only autoregressive transformer generates semantic tokens - A flow-matching model generates acoustic tokens. This combines long-range coherence with rich acoustic Show more
