OpenAI says Responses API requests can reuse warm containers for skills, shell, and code interpreter, cutting startup times by about 10x. Faster execution matters more now that Codex is spreading to free users, students, and subagent-heavy workflows.
OpenAI says it "added a container pool to the Responses API," which lets requests reuse warm infrastructure instead of paying full container creation cost on every session. In the same post, OpenAI says container startup for skills, shell, and code interpreter is now "about 10x faster" launch details.
That is an infrastructure change, not a new agent primitive. The practical shift is lower cold-start overhead for tool-using agents that need an execution environment before they can run code or shell steps, and OpenAI framed it as making "agent workflows" faster rather than changing model behavior repost.
The timing lines up with broader Codex distribution. A developer post says "You can use Codex in your free ChatGPT account" free-tier note, and a separate OpenAI promotion for students, surfaced in the repost, offers college students in the U.S. and Canada $100 in Codex credits.
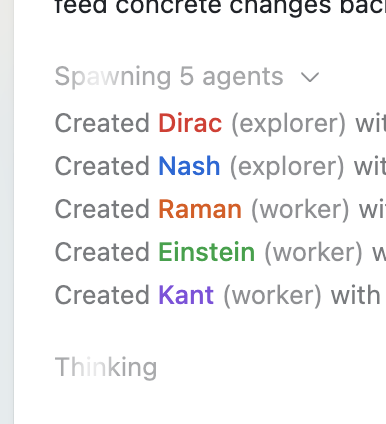
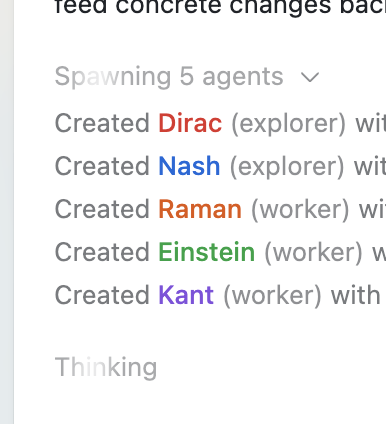
That wider access increases the odds that more users will hit execution latency in real workflows, especially when one request fans out into several workers. The shared screenshot shows a concrete example: one run starts by "Spawning 5 agents" and then creates two "explorer" agents and three "worker" agents, which is exactly the kind of subagent-heavy pattern where warm container reuse can shave visible setup time.
Agent workflows got even faster. You can spin up containers for skills, shell and code interpreter about 10x faster. We added a container pool to the Responses API, so requests can reuse warm infrastructure instead of creating a full container creation each session. Show more
Codex subagents game changer