Codex app reportedly leaks GPT-5.6 Sol, Terra, and Luna model names
Codex app code now references GPT-5.6 Sol, Terra, and Luna, while posts claim Sol Ultra reaches 91.9% on TerminalBench at lower cost. Treat release timing, limits, and benchmark claims as unofficial until OpenAI publishes details.
TL;DR
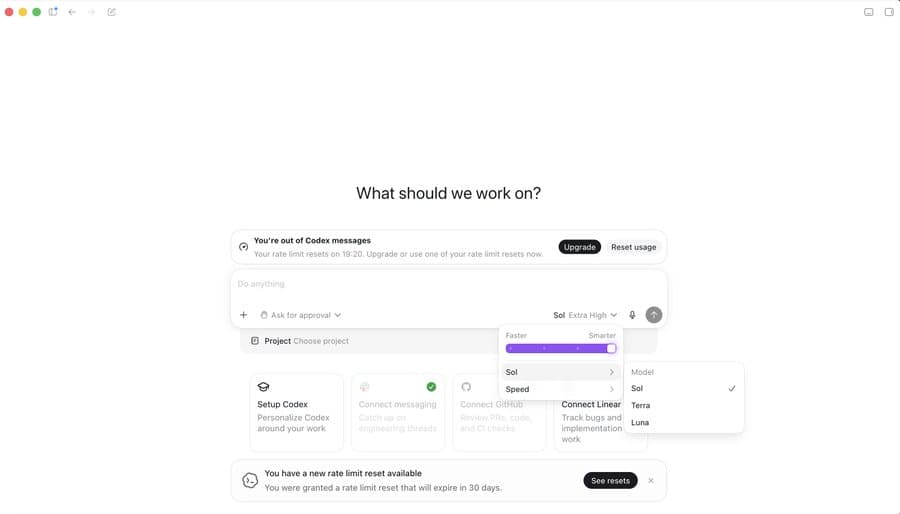
- testingcatalog's Codex screenshot and kimmonismus's Codex screenshot show Sol, Terra, and Luna inside Codex, with the models visible but unavailable to the posters.
- the OpenAI preview link matches the names: OpenAI says GPT-5.6 starts as a limited API and Codex preview before broader ChatGPT, Codex, and API availability.
- bridgemindai's TerminalBench chart puts GPT-5.6 Sol Ultra at 91.9% on TerminalBench 2.1, while bridgemindai's benchmark reply says there is no SWE-Bench result yet.
- haider1's tier graphic lays out the three-tier pricing: Sol at $5 input and $30 output per 1M tokens, Terra at $2.50 and $15, Luna at $1 and $6.
- daniel_mac8's timing post points to Tuesday, July 7, while the July 8 claim gives a different date; release timing remains rumor-level until OpenAI posts the switch-flip.
OpenAI already published a June 26 limited-preview page for Sol, Terra, and Luna, plus a system card that labels the family High in cyber and bio/chem risk. The Codex screenshot adds the product plumbing the announcement did not show: a model picker, a faster-to-smarter control, and rate-limit reset UI. The spicy part is the chart: Sol Ultra at 91.9% on TerminalBench 2.1, ahead of Fable 5 at 84.3%, with no independent SWE-Bench number in the evidence yet.
Codex model selector
The app-level evidence is a selector state. testingcatalog's post says GPT-5.6 Sol, Terra, and Luna are already referenced in Codex code, while kimmonismus's screenshot shows the same names inside a Codex task modal.
Two UI details are worth separating from the model names:
- A faster-to-smarter control appears next to Sol.
- A rate-limit reset banner appears below the task box.
- The Codex landing cards include GitHub, Linear, and messaging connections.
OpenAI's preview page says GPT-5.6 models initially ship through the API and Codex to selected trusted partners and organizations. koltregaskes's code-reference post repeats the same hidden model-name finding and says the models are still hidden.
Model tiers
OpenAI's naming system splits generation from tier. The number marks GPT-5.6; Sol, Terra, and Luna are durable capability tiers that can advance separately, according to OpenAI's preview page.
The tier map in haider1's graphic matches the official pricing:
- Sol: flagship model for ambitious agentic work, $5 input, $0.50 cached input, $30 output per 1M tokens.
- Terra: balanced model for everyday work, $2.50 input, $0.25 cached input, $15 output per 1M tokens.
- Luna: fast model for high-volume work, $1 input, $0.10 cached input, $6 output per 1M tokens.
OpenAI also says Terra has competitive performance to GPT-5.5 at half the cost, and Luna is the lowest-cost option in the family. haider1's follow-up thread frames Luna and Terra as the interesting models for most tasks, with Sol Ultra reserved for the hardest slice.
TerminalBench chart
OpenAI's preview page says Terminal-Bench 2.1 tests command-line workflows requiring planning, iteration, and tool coordination. The chart circulating in bridgemindai's post gives the score table people are arguing over:
- GPT-5.6 Sol Ultra: 91.9%
- GPT-5.6 Sol: 88.8%
- Claude Mythos 5: 88.0%
- GPT-5.6 Terra: 84.3%
- Claude Fable 5: 84.3%
- GPT-5.5: 83.4%
- GPT-5.6 Luna: 82.5%
- Claude Opus 4.8: 78.9%
- Gemini 3.1 Pro Preview: 70.7%
The gap that matters for coding-agent nerds is Sol Ultra over Fable 5, 91.9% versus 84.3%. bridgemindai's workflow reply adds the caveat: TerminalBench is one signal, and the open question is how the model holds up inside a real workflow.
Cost per task
The pricing discussion quickly moved from model quality to cost per task. daniel_mac8's cost thread frames Sol as $30 per 1M output tokens versus $50 for Fable, and says ChatGPT subscription access would make availability part of the competitive story.
cedric_chee's cost-per-task thread makes the sharper claim: Terra matches GPT-5.5 at 2x lower cost, Luna pushes efficiency further, and Sol claims comparable or better results with roughly one-third of the output tokens.
koltregaskes's follow-up pulls the same pressure into infrastructure economics: fine-tuning is cheap, inference and ops are the gotcha, and rising token bills plus access risk push businesses toward custom models on their own data. daniel_mac8's reply gives the compact version of the pro-OpenAI bet: reliability.
Release-date rumors
The timing rumor has two clusters. daniel_mac8's post says OpenAI plans a Tuesday, July 7 release tied to Fable access leaving Claude subscriptions, while the July 8 post claims a July 8 release.
haider1's Polymarket screenshot highlights prediction-market odds around July 8, July 9, and July 10. the DM calendar screenshot claims a July 8 internal launch brief, but the evidence is a screenshot of a private message and calendar invite, not an OpenAI publication.
The Fable angle is access, not just benchmarks. daniel_mac8's timing post argues Anthropic could respond by extending Fable subscription access, and omarsar0's UX post says GPT-5.6's opening depends partly on guardrails and user experience.
A few rumor artifacts added heat without adding much detail. zeeg's link-only post is one of those, useful mostly as a marker of how fast the leak cycle moved.
Safety stack
The quietest part of the rollout is the safety machinery. The GPT-5.6 system card says OpenAI treats Sol, Terra, and Luna as High capability in both Cybersecurity and Biological and Chemical risk, while none reaches the High threshold for AI Self-Improvement.
OpenAI lists the preview safeguards as a stack:
- Model-level refusal training for prohibited cyber assistance.
- Real-time cyber and biology misuse classifiers during generation.
- Larger-model review when a higher-risk output is flagged.
- Account-level review across conversations and risk signals.
- Differentiated access for sensitive capabilities.
- Continuous red-teaming during deployment.
The compute number is the tell. OpenAI says it spent more than 700,000 A100-equivalent GPU hours on automated red-teaming for universal jailbreaks, plus external human red-teaming that continues during the preview period.