Cognition benchmarks FrontierCode: top model scores 13% with mergeability grading
Cognition introduced FrontierCode, a coding benchmark that grades mergeability and review quality instead of only unit-test passes, and the top model scored 13%. The result matters because it differs from SWE-Bench-style pass rates, and outside researchers are already questioning score variance and reproducibility.
TL;DR
- Cognition's new official launch post says FrontierCode grades whether a maintainer would merge a PR, not just whether the patch passes tests, and ScottWu46's launch thread framed the result bluntly: the best model scored only 13% on the hardest slice.
- According to the official methodology, FrontierCode mixes blockers and weighted rubric items across correctness, regression safety, scope, test quality, style, and code quality, which is a much broader target than SWE-Bench-style unit-test passing; imjaredz's summary captured the gap as "everyone 50+%" on older coding benches versus nobody above 13.4% here.
- Cognition says in its launch post that FrontierCode cuts false positives by 81% versus SWE-Bench Pro, while ScottWu46 described the benchmark as grading like a tech lead rather than a CI system.
- Early reaction focused less on the headline number than on variance: theo's chart questions flagged that Opus 4.8 looked 2.5x better than Opus 4.7 and that some lower effort settings outscored higher ones.
You can read Cognition's full methodology post, skim the emerging leaderboard view, and see theo's question list push on language mix, repo disclosure, run counts, and reproducibility. eliebakouch's post also points directly at the official writeup and calls out that simple test-time scaling looks noisy on this benchmark.
Mergeability grading
FrontierCode's central move is to treat mergeability as the target. In Cognition's launch post, a solution only passes if it clears every blocker a maintainer would treat as a hard stop, then gets a weighted score across the rest of the rubric.
The rubric spans six axes from the official post:
- Behavioral correctness
- Regression safety
- Mechanical cleanliness
- Test correctness
- Scope discipline
- Code quality
The mechanics matter because FrontierCode adds three grading methods that older coding benches usually skip:
- Reverse-classical tests: the agent's own tests must fail on the original broken code.
- Scope checks: file boundaries, diff size, and sometimes semantic locality are enforced.
- Adaptive classical grading: Cognition says its
mutagenttool uses an LLM to patch the test environment around valid implementation differences.
That is the benchmark's strongest claim. The official post argues that existing benchmarks over-reward patches that work but would not survive review, and says FrontierCode produces 81% fewer false positives than SWE-Bench Pro.
Diamond scores
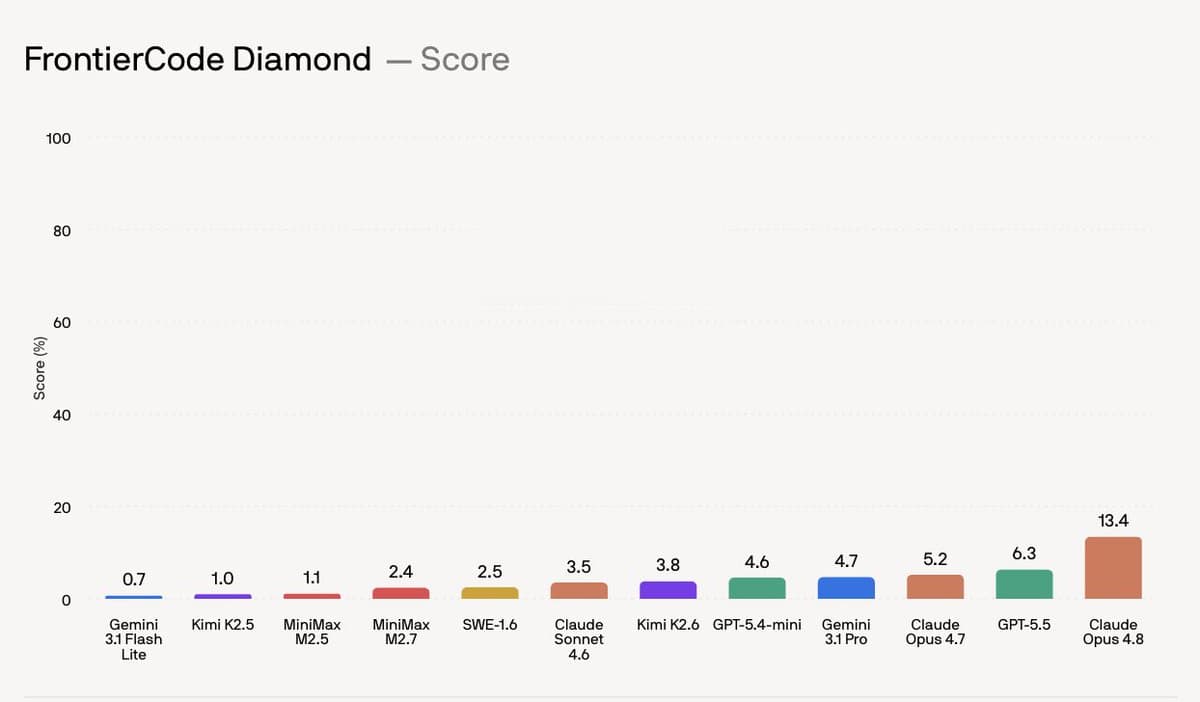
The most quoted number comes from Diamond, FrontierCode's 50-task hardest subset. Cognition's launch post reports Claude Opus 4.8 at 13.4% score there, with GPT-5.5 at 6.3%, Gemini 3.1 Pro at 4.7%, and Kimi K2.6 at 3.8%.
The same post splits the benchmark into three nested sets:
- Diamond: 50 hardest tasks
- Main: 100 hardest tasks, including Diamond
- Extended: full 150-task set
On those broader sets, the official post puts Opus 4.8 at 34.3% on Main and 51.8% on Extended. The separate BenchmarkList leaderboard shows FrontierCode as a multi-metric table, with score and pass-rate views broken out by effort level.
The bench also produces a more awkward chart than the usual "more reasoning, better score" story. theo's chart questions notes that Opus low beat medium, Opus x-high beat max, and GPT-5.5-medium was OpenAI's highest-scoring setting in the posted results.
Reproducibility questions
That variance turned the launch into a methodology story almost immediately. theo's first reaction praised the mergeability idea, then said the chart was "scary" because lower effort settings sometimes beat higher ones.
In a follow-up list, theo's open questions asked for five specifics:
- The language split between Diamond and Extended
- Which repos are inside Diamond
- How many runs were done per model per task
- Why Opus 4.8 outperformed 4.7 so sharply
- How reproducible the scores are on rerun
Cognition's official post does answer one of those questions: each model is run five times at every available reasoning effort, averaged within effort level, then reported at its best-performing setting. It does not, in the material surfaced here, publish the Diamond repo list or explain the effort-level inversions.
Task construction
The benchmark's other big reveal is how expensive it is to build. Cognition says in the launch post that 20-plus open-source maintainers from 36 repositories spent more than 40 hours per task, with every task manually reviewed by a Cognition researcher.
That construction detail explains why FrontierCode can be both smaller and harsher than patch-size-driven benches. The official post says its prompts are about one-third the length of SWE-Bench Pro's, because the maintainers are judging whether the agent can infer intent from a concise human-style request plus repo guidelines, not whether it can follow an over-specified ticket.
The result is a benchmark built to reward restraint as much as patching ability. According to the official post, FrontierCode scales difficulty through quality rubrics rather than larger diffs, which is a different bet on what "coding ability" should mean in production repos.