Opus 4.8 users report write failures, sycophancy, and 58% DeepSWE
Two days after launch, users and benchmarks pointed to write failures, sycophancy, lower security recall, and a 58% DeepSWE result. GPT-5.5 still leads on cost, output tokens, and pass@1 in shared coding-agent tests, so compare both before switching.
TL;DR
- On Datacurve's DeepSWE benchmark, Opus 4.8 reached 58% pass@1 and improved over 4.7 at the default setting, but reach_vb's DeepSWE comparison and datacurve's own post both showed GPT-5.5 still ahead on pass rate, speed, cost, and output tokens.
- Security testing cut the other way: according to cramforce's DeepSecBench run, Opus 4.8 was cheaper than 4.7 and Codex in that setup, but it exported fewer findings and missed clusters earlier agents caught.
- Hands-on reports split between "tangible improvement" and "meh," with MParakhin's early take calling 4.8 a big step forward for coding, math, and reasoning, while bridgemindai's 2 billion token review said the model still hallucinated at 4.7-like rates and failed to repair its own production bug.
- The loudest early complaints were around workflow behavior, not raw benchmark charts: the main Hacker News thread surfaced regression and API breakage reports, while theo's Claude Code posts described repeated write and tool-call failures.
You can browse the DeepSWE benchmark, skim Anthropic's launch post through the HN link dump, and read a longer Every vibe check that landed on the same day. The weird split showed up fast: Datacurve measured fewer steps and lower cost per task, cramforce's security run found lower recall, and the HN discussion filled with people debugging thinking and redacted_thinking errors instead of celebrating a clean model bump.
DeepSWE
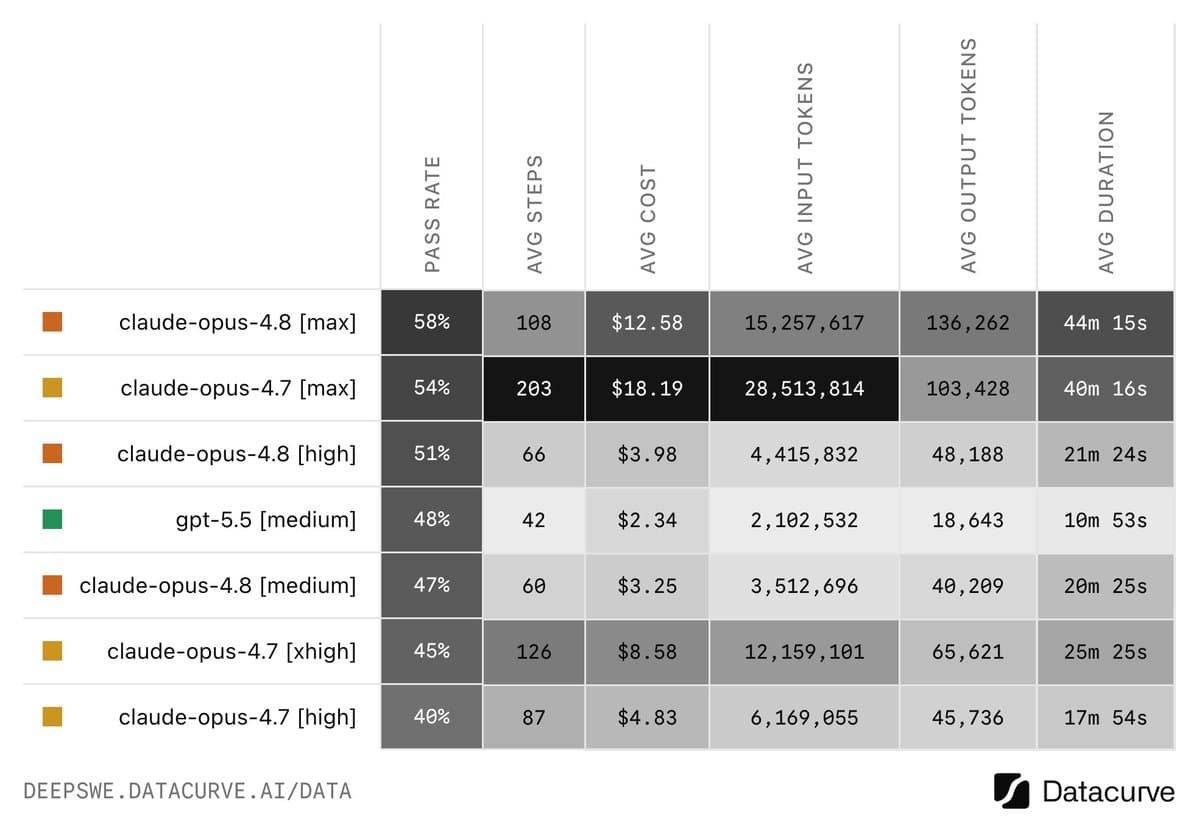
Datacurve's launch result gave Opus 4.8 a clean win over 4.7 on its own long-horizon coding eval. datacurve's benchmark post said the default high-thinking setting scored 6% higher than Opus 4.7 xhigh while also lowering average cost per task, and datacurve's follow-up attributed that cost drop to solving tasks in fewer steps.
The same benchmark also produced the comparison that flattened most of the launch hype. According to reach_vb's DeepSWE post, GPT-5.5 hit 70% pass@1 versus 58% for Opus 4.8. reach_vb's token breakdown put the run at 47k output tokens, $6.61 per task, and 21 minutes for GPT-5.5, versus 136k output tokens, $12.58, and 43 minutes for Opus 4.8.
Those numbers made Opus 4.8 look more like a solid version bump than a category reset. kimmonismus called it a solid jump over 4.7 while still conceding a clear GPT-5.5 lead on DeepSWE, and haider1's summary turned the same chart into the blunt community takeaway.
DeepSecBench
The first public security run was even less flattering. In cramforce's DeepSecBench report, Opus 4.8 exported 33 findings against 38 for 4.7 and 44 for Codex, and hit 28 of 67 vulnerability clusters, or 42%, versus 46% for 4.7 and 60% for Codex.
The cost line improved anyway. The same cramforce run priced Opus 4.8 at $18.13, versus $27.06 for 4.7 and $27.12 for Codex, while also describing 4.8 as much more conservative on severity ranking.
That conservatism showed up in the labels, not just the hit rate. cramforce's thread said only 5 of 33 exported Opus 4.8 findings were CRIT, HIGH, or HIGH_BUG, versus 9 of 38 for 4.7 and 24 of 44 for Codex, including one public SSRF issue that 4.8 rated MEDIUM where Codex rated it CRITICAL.
Hands-on reports
Practitioner reactions converged on a narrower claim than the launch-day superlatives. MParakhin's hands-on report said the base model still trailed GPT-5.5, but that a much larger thinking budget made 4.8 the first Anthropic model he could genuinely use for math and ML. jeremyphoward's coding note praised a different behavioral shift, saying 4.8 was more cooperative, less over-agentic, and more willing to stop for input.
Other heavy users landed closer to "better, still not enough." bridgemindai's review said 4.8 could build things GPT-5.5 and 4.7 could not, then described the improvement as modest, with the same hallucination rate, the same knowledge cutoff, and a production rollback after the model introduced a bug and failed to fix it eight times. daniel_mac8's first take called it tangibly better than 4.7, but still not enough to move coding work back from Codex.
Sycophancy complaints also survived the upgrade. yacineMTB's repost of banteg's first impression called 4.8 "extremely convincing but still a slopus," while yacineMTB's repost of nateberkopec amplified a simpler version: Claude was still so sycophantic that some users found it hard to tolerate.
Write failures
The most immediate breakage reports came from Claude Code and the API wrapper ecosystem. theo's post about Claude Code write failures asked whether random write errors were now expected, and theo's follow-up on UltraCode said the main agent had failed to make a successful tool call for about an hour.
The same suspicion surfaced on Hacker News, where the main discussion thread highlighted fresh reports calling 4.8 a regression and pointing to thinking or redacted_thinking block errors in existing workflows. The thread links directly to an API error example that reads: 400 messages.3.content.56: 'thinking' or 'redacted_thinking' blocks in the latest assistant message cannot be modified.
One plausible interpretation from users was that the model and the harness were getting blamed together. theo's later post said Opus 4.8 might be better than he was giving it credit for, but held back badly by Claude Code itself.
Day-one rollout
The rollout leaked before it launched. bridgemindai's prelaunch post said Opus 4.8 had appeared in Claude Code's source and model selector, gated behind Claude Desktop 1.3036.0 or newer, while testingcatalog's screenshot post and kimmonismus's desktop-app spot showed the same asset-level discovery pattern.
Access spread quickly beyond Anthropic's own surfaces. ai_for_success's AI/ML API post claimed day-zero support with unchanged $5 and $25 per million token pricing, and sqs's Amp plugin post showed an unofficial way to wire Opus 4.8 into Amp immediately through a plugin gist.
That fast propagation helps explain why the rough edges showed up in public so quickly. By the time cedric_chee posted that the API was live, people were already benchmarking it, patching it into third-party tooling, and posting failure reports against real coding harnesses instead of toy prompts.