Perceptron released an MCP server that routes OCR, grounding, object detection, and visual question answering through its Isaac model family. The release lets agents offload structured visual perception instead of using a general multimodal model for every image step.
Perceptron’s release is an MCP server that lets an agent call specialized vision tools instead of treating an image as “just another prompt” to a large multimodal model. In Perceptron’s launch thread, the core claim is cost and fit: general multimodal models are “expensive for every visual task,” while Isaac is positioned as a separate perception layer for image-heavy steps.
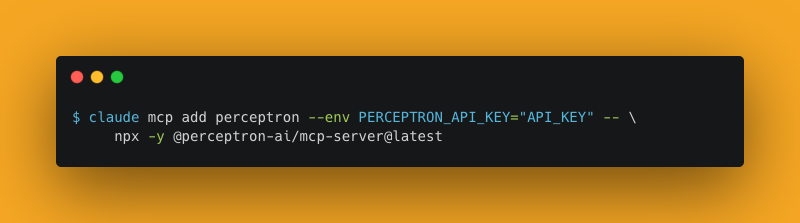
The technical payload is narrow but useful. Perceptron’s capabilities post says Isaac exposes VQA, OCR, object detection, and grounding, with vision “returned as structured output,” which matters for agent handoffs where the next step needs fields, labels, or coordinates instead of prose. The docs linked in the MCP guide describe four tools — caption, detect, ocr, and question — and the install path in the setup post targets Claude Code via a single claude mcp add command.
The clearest use cases are workflow primitives, not open-ended chat. Perceptron’s own examples in the examples post are file sorting, best-shot selection, and receipt extraction. A supporting practitioner thread argued that this split matters because OCR, grounding, and detection are “perception problems that need precise outputs,” not just text generation with pixels attached architecture take.
Despite having vision, most AI agents still struggle to see. General-purpose multimodal models are powerful, but they’re expensive for every visual task. We built something better: Perceptron's MCP gives any agent stronger vision capabilities through Isaac with far lower cost.
Install in one line for Claude Code: `claude mcp add perceptron -e PERCEPTRON_API_KEY=YOUR_API_KEY -- npx -y @perceptron-ai/mcp-server@latest` Docs → docs.perceptron.inc/guides/mcp API Keys → platform.perceptron.inc
