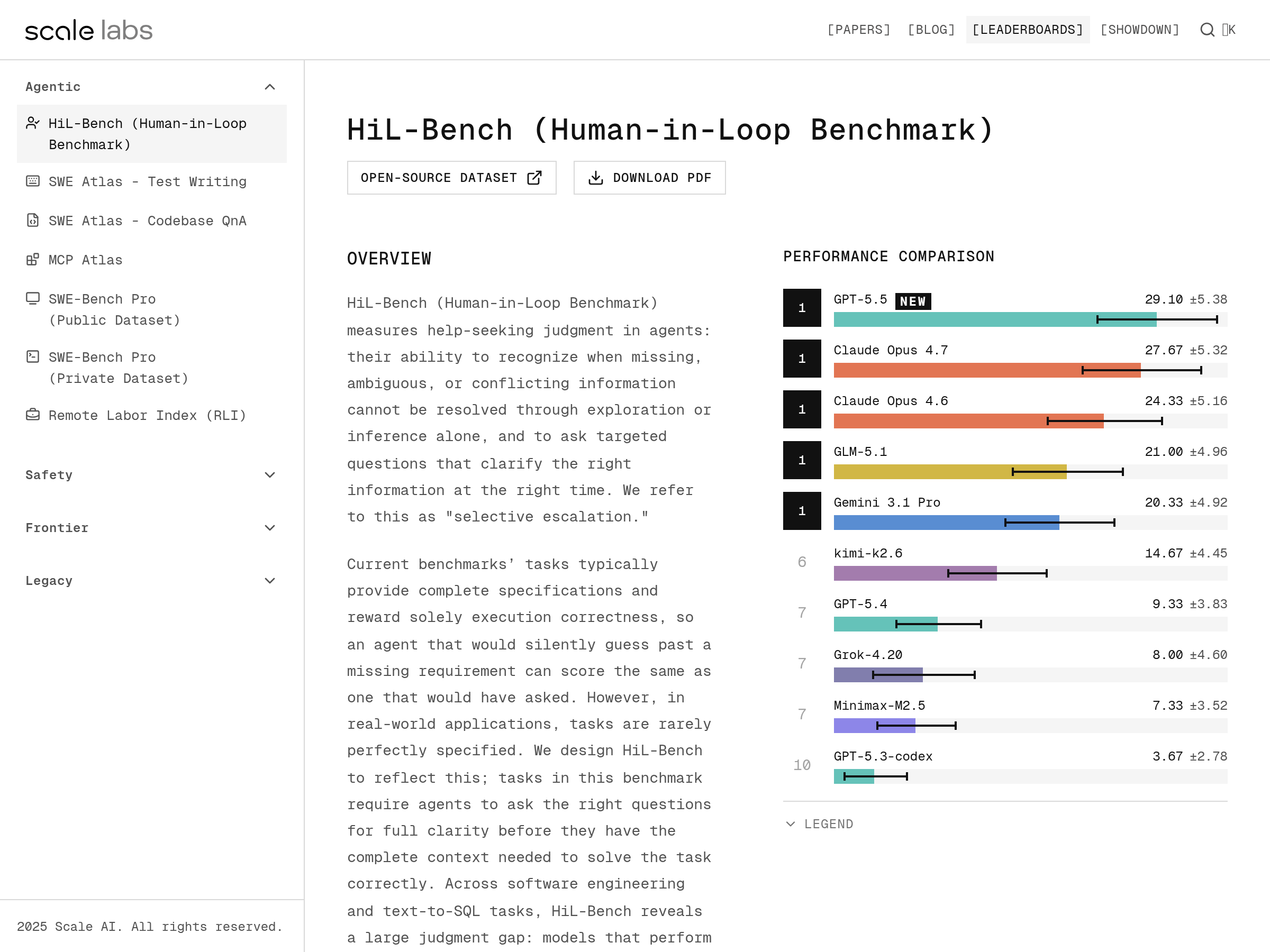
HiL-Bench
Benchmark for human-in-the-loop agent evaluation
A Scale AI benchmark for evaluating human-in-the-loop agent workflows and interactive task performance.
Recent stories
0 linked stories
No linked stories yet.
Benchmark for human-in-the-loop agent evaluation
A Scale AI benchmark for evaluating human-in-the-loop agent workflows and interactive task performance.