Microsoft opened VibeVoice with 60-minute ASR, speaker-timed transcripts and 300ms streaming TTS across 50+ languages. HN discussion around Kitten TTS shows the same push toward lighter voice stacks, while latency and dependency bloat still matter on edge hardware.
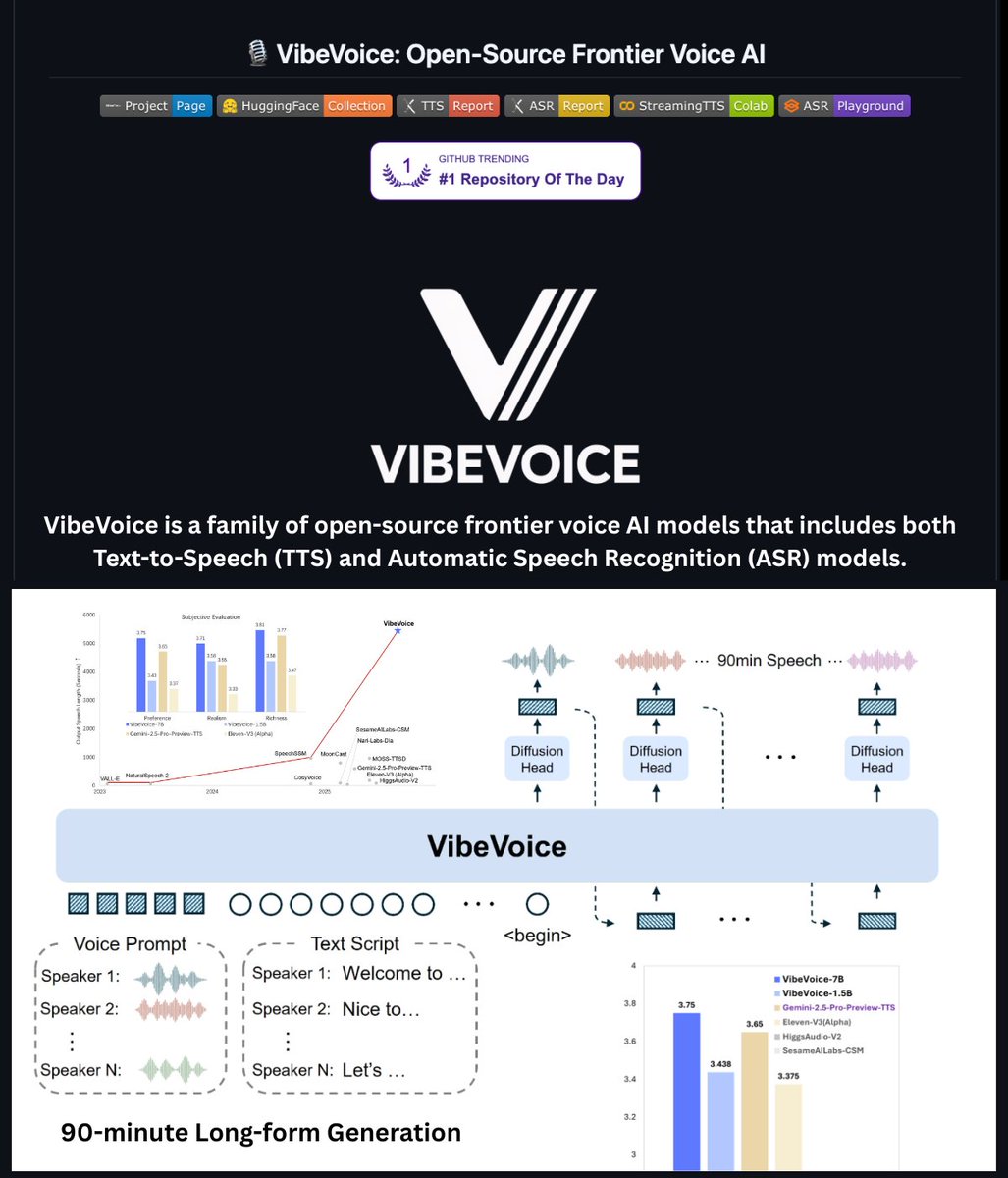
Microsoft's VibeVoice release is two products in one family: long-context speech recognition and low-latency text-to-speech. In the launch thread, Hasan Toor summarizes the headline numbers as 60-minute single-pass ASR, speaker identification, word timestamps, and roughly 300ms first-audio latency for streaming TTS. The linked GitHub repo adds that the ASR side can output structured transcriptions with timestamps and speaker attribution, and that the stack supports fine-tuning, vLLM-based inference, and 50-plus languages.
For creators, the practical shift is less cleanup between recording and edit. A single recording can be turned into a speaker-separated transcript for rough cuts, while the TTS side is aimed at fast voice generation instead of offline batch export. The [img:0|project graphic] also shows Microsoft framing VibeVoice as a broader open-source voice platform rather than a single demo model.
Posted by rohan_joshi
This is a compact TTS release focused on expressive voice output at very small sizes, which matters for narration, voice apps, and interactive audio workflows. The discussion centers on whether prosody, pronunciation, and expressive control are good enough to make tiny models usable in real voice production scenarios.
VibeVoice lands into a voice market that is splitting in two directions: bigger open models that cover more of the workflow, and tiny models that can run closer to the device. The Kitten TTS page describes Kitten TTS as an ONNX library with 15M to 80M parameter models, CPU inference, eight built-in voices, adjustable speed, and 24 kHz output, with the smallest model under 25MB.
That contrast sharpens the real question for creatives: not just output quality, but where the model can run and how fast it starts talking. In the HN thread, one user reports using Kitten in a Discord bot workflow at about 1.5x realtime on an Intel 9700 CPU, while the HN discussion highlights the recurring blockers on lightweight stacks: installation pulling heavy dependencies, unclear first-chunk latency, and streaming limitations on low-power hardware.
Posted by rohan_joshi
Thread discussion highlights: - tredre3 on packaging and dependencies: Feedback that installing the Python package pulls in a heavy chain of dependencies, including spaCy, and may drag in torch and NVIDIA CUDA packages that are unnecessary for running the model. - baibai008989 on edge deployment and latency: A Raspberry Pi user says 25MB is exciting for home automation, but asks about first-chunk latency, streaming support, and pronunciation consistency for technical terms. - bobokaytop on edge performance tradeoffs: Notes that model size is impressive, but the practical bottleneck is inference latency and audio streaming architecture on low-power hardware, not just file size.
Posted by rohan_joshi
Kitten TTS is an open-source, lightweight text-to-speech library built on ONNX with models from 15M to 80M parameters (25-80 MB). It supports CPU inference without GPU, features 8 built-in voices, adjustable speed, text preprocessing, and 24 kHz output. Latest release v0.8.1 (Feb 2026) includes nano, micro, and mini models. Installation via pip, simple Python API for generation. 13k+ stars, Apache 2.0 license.
🚨 BREAKING: Microsoft just open-sourced a frontier Voice AI that handles 60-minute audio in a single pass. You drop in a recording. It identifies every speaker, timestamps every word, and outputs a full structured transcript with who said what and when. It also does real-time Show more
