NVIDIA published Nemotron-Cascade 2, a 30B MoE with 3B active parameters, claiming IMO gold-level math and Kimi K2.5-class code scores, then pushed it to Hugging Face and Ollama. It is worth testing if you want an open agent model with immediate local and hosted paths.
Nemotron-Cascade 2 is a new open model release centered on a 30B MoE architecture with 3B active parameters. The Hugging Face post links both the paper and model collection, while the paper page and model collection make this more than a benchmark teaser: there are public assets engineers can inspect and pull into existing workflows.
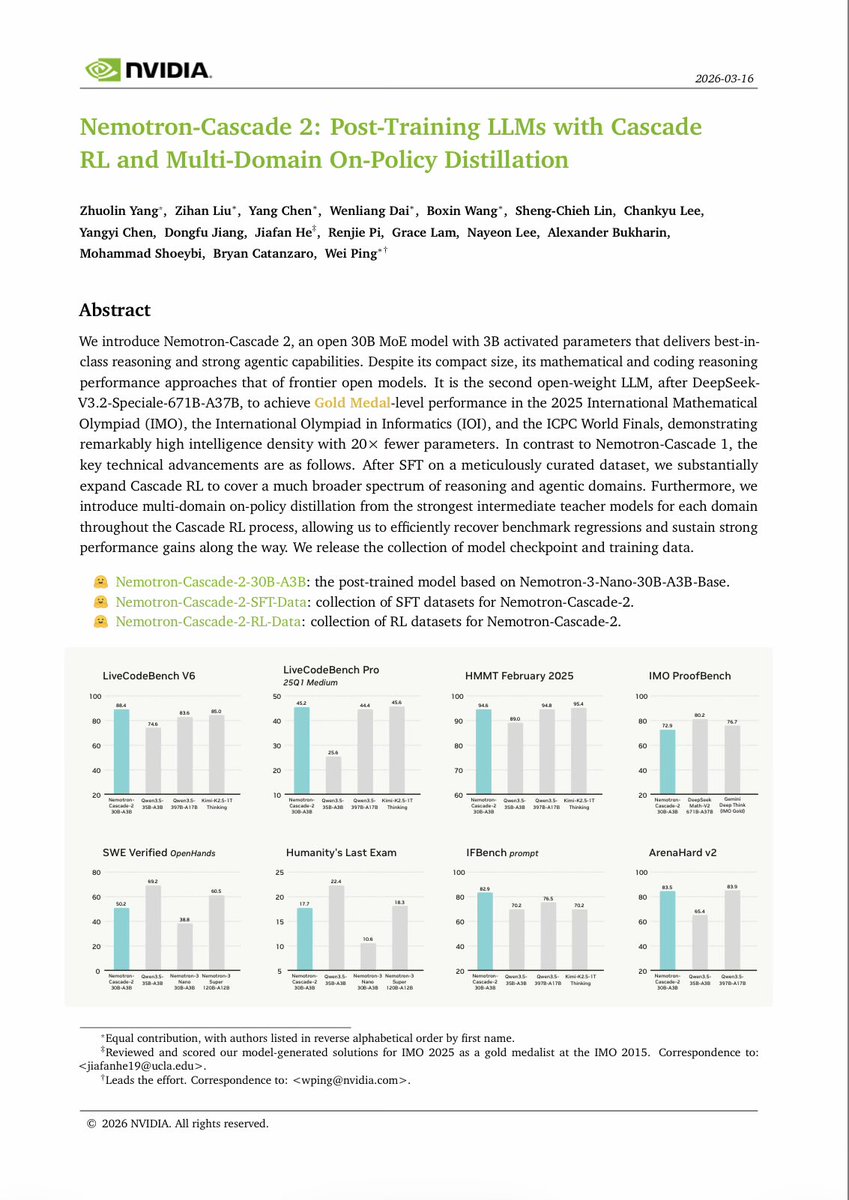
The headline claims are aggressive. NVIDIA’s paper card says the model achieves “Gold Medal-level performance” on the 2025 IMO and shows comparisons against DeepSeek-V3.5-35B-A3B and Kimi-K2.5-17-Thinking across LiveCodeBench, SWE Verified OpenHands, Humanity’s Last Exam, and ArenaHard v2. That same card describes the release as “Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation,” which is the main technical framing for how NVIDIA says it got there.
The practical part of this launch is that it already has local runtime paths. Ollama’s announcement says you can run it with ollama run nemotron-cascade-2, and its model page positions the model for “reasoning and agentic capabilities” rather than as a generic chat checkpoint.
Ollama’s follow-up model page thread adds a few deployment details that matter: the page describes thinking and instruct modes, mentions use in tools like OpenClaw, and highlights a 24GB variant with a 256K context window. Separately, the quantization post shows the community is already adapting the model for constrained hardware, with MLX 5-bit and GGUF Q5 variants on Hugging Face via the MLX build and the GGUF build. The GGUF summary says the quantized runtime footprint is about 26 GB, which puts local testing within reach on a single high-memory workstation rather than only server GPUs.
Nvidia just released Nemotron-Cascade 2 on Hugging Face paper: huggingface.co/papers/2603.19… model: huggingface.co/collections/nv…
Nvidia released Nemotron-Cascade 2. A 30B-A3 MoE open model on par with Kimi K2.5 on LiveCodeBench. It achieved IMO gold level!

🚀 Introducing Nemotron-Cascade 2 🚀 Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities. 🥇 Gold Medal-level performance on IMO 2025, IOI

Nemotron-Cascade-2 is now available to run with Ollama. ollama run nemotron-cascade-2 To run it locally with OpenClaw: ollama launch openclaw --model nemotron-cascade-2 This model from NVIDIA delivers strong reasoning and agentic capabilities on par with models with up to 20x Show more
Couldn't find any quants so I made some: MLX 5-bit: huggingface.co/AdrienBrault/N… GGUF Q5_K_M: huggingface.co/AdrienBrault/N… GGUF Q5_1: huggingface.co/AdrienBrault/N…
🚀 Introducing Nemotron-Cascade 2 🚀 Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities. 🥇 Gold Medal-level performance on IMO 2025, IOI