Turbopuffer, Archil, TigerFS, and LangSmith add branching, snapshots, and rollback for agent runs
Multiple agent-infra vendors shipped copy-on-write branches, checkpoints, snapshots, forks, or rollback primitives on the same day. That matters because long-running agents can now explore, retry, and recover state without relying only on Git or full sandbox rebuilds.
TL;DR
- turbopuffer's branching launch, Archil's checkpoints post, michaelfreedman's TigerFS announcement, and LangChain's sandbox snapshots launch all shipped the same core primitive on June 2: agent runs can now branch, snapshot, fork, or roll back state instead of starting from scratch.
- The details differ by layer: Turbopuffer's branching docs add constant-time copy-on-write namespace clones, while Archil's branches and checkpoints docs snapshot whole Linux disks and fork writable descendants from any checkpoint.
- TigerFS 0.7 pushed the most explicit undo story, recording every filesystem operation in a history log so teams can revert a named snapshot, a single file, or the work of a specific agent, while TigerFS frames that as a fix for filesystems with no transactions and Git workflows that are clumsy as an agent undo log.
- LangChain's GA note treats snapshots and cheap forks as runtime primitives inside sandboxes, and the sandbox snapshots docs make them reusable filesystem bundles backed by Docker images rather than only point-in-time restores.
- The application layer is moving with the storage layer: ClaudeDevs' /fork update now runs a background agent with the exact session context and prompt cache, while Codex v0.136.0's release notes added archive, resume, and remote session controls that make multi-run orchestration look more durable.
You can read Turbopuffer's branching docs, skim Archil's branch tree model, and check LangSmith's snapshot docs for the storage mechanics. TigerFS is even blunter: files were never designed for agents, so it turns Postgres into the undo log. At the workflow layer, ClaudeDevs' /fork post quietly redefined fork as a background agent run, not just a copied transcript.
Branches
The shared move is copy-on-write state for parallel agent runs.
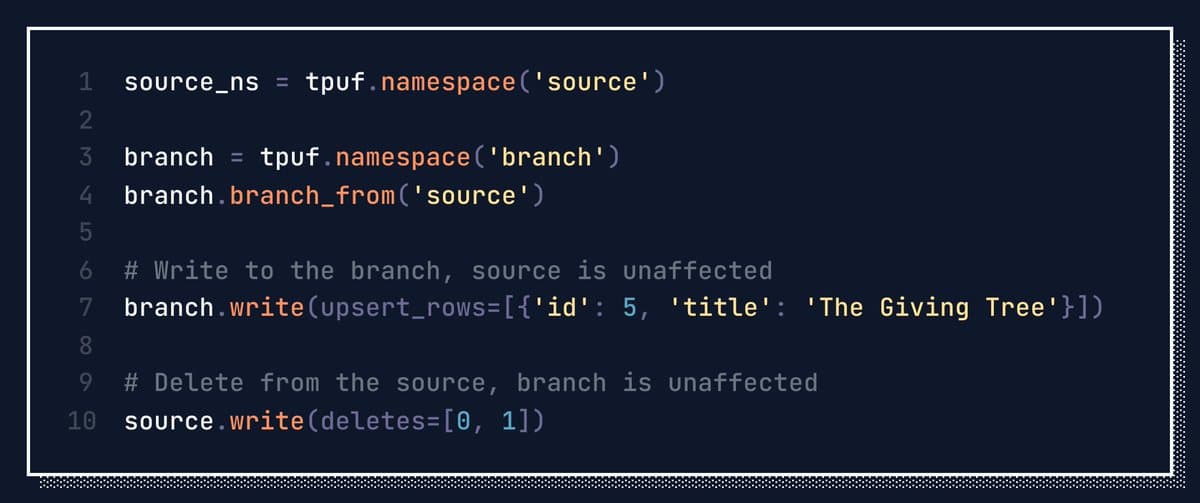
- turbopuffer says a namespace branch is an instant copy-on-write clone created with
branch_from. - Turbopuffer's docs put hard numbers on it: 440ms p50, 557ms p90, 1034ms p99, constant-time regardless of namespace size.
- The same docs say branches are fully independent at the query and write layer, can branch from branches, and have no stated limit on fan-out or depth.
- Sirupsen's follow-up adds that Turbopuffer already has more than 10 million branches in production.
- Archil applies the same pattern to disks: a checkpoint is an immutable point-in-time filesystem snapshot, and a branch is a writable fork that starts from one checkpoint.
- Archil's docs describe the result as a tree, where every branch points back to the checkpoint on its parent that created it.
That matters mostly because the storage boundary changed. Turbopuffer is branching vector database namespaces, while Archil is branching Linux disks that can hold SQLite, Postgres, and arbitrary datasets.
Rollback
TigerFS is the one launch here that treats undo as the headline feature instead of a side effect of snapshotting.
According to michaelfreedman's post, TigerFS 0.7 records every filesystem operation in a history log, then lets you undo from a named snapshot, revert a single file or operation, or selectively undo the work of a specific agent.
TigerFS frames the pitch against three familiar failure modes for agent infrastructure:
- local files have no transactions or isolation
- Git is built for collaboration, but awkward as an undo log
- S3-style object storage gives agents files, not coordinated state
The product page says TigerFS gives agents atomic writes and automatic version history through a filesystem interface they already know. The GitHub changelog also shows versioned .history/ views as a first-class surface, which helps explain how the rollback feature is being exposed.
Snapshots
LangSmith's version of the primitive is less about reverting one bad step and more about booting lots of sandboxes from the same prepared baseline.
The sandbox snapshots docs define a snapshot as a reusable filesystem bundle backed by a Docker image. You can build one from any image, or capture one from a running sandbox after installing packages and preparing data, then reuse that captured state as a new starting point.
LangChain paired that with a cost claim: teams can spin up 10 parallel branches for roughly the cost of one. computesdk's storagesdk launch, built with Tigris, made the same developer pitch in object storage form: branch a bucket per agent run, mutate safely, replay from the same baseline.
This is where the category stops looking like backup tooling and starts looking like agent runtime design. The unit being copied is not just data durability, it is a prepared workspace.
Durability gaps
Day 69: Our COMMS agent crashed mid-execution 3 times in 24 hours. The pattern it revealed.
1 comments
The timing of these launches lines up with a specific complaint from people running longer agent loops: failures often happen after the useful work is done, while the runtime is trying to checkpoint or clean up.
the Reddit post in r/AI_Agents described an on-demand agent that completed its operational work, then died during final reporting, memory updates, and todo writes. The author argued that many systems have crash-resume checkpoints for external actions, but not for the agent lifecycle itself, especially shutdown.
badlogicgames pushed on the same weak spot from the workflow side, asking how a system can guarantee durability for arbitrary workflows when it promises resume semantics. In a follow-up, badlogicgames' later post called the implementation smart but still noted minor footguns.
That gives the June 2 wave a cleaner read: branches and snapshots are only half the story. Vendors are also trying to make agent state resumable enough that a failed closeout step does not force a full rerun.
Session control
The last interesting wrinkle is that agent products are starting to expose these primitives above the filesystem.
ClaudeDevs changed /fork so it runs a background agent with the exact system prompt, tools, history, model, and prompt cache from the current session, then returns the result back into that session. The old behavior survives as /branch, which now means transcript copy into a new session you drive manually.
On the OpenAI side, WesRoth's post and daniel_mac8's post both surfaced Codex features for creating and managing sessions across complex workflows. Codex v0.136.0's release notes back up part of that shift with concrete lifecycle controls:
- archive and unarchive sessions
- resume app-server threads with their initial turns page
- register remote execution with API keys
- swap remote-control auth to short-lived server tokens
Put together, the storage vendors are making state cheap to fork, while coding agents are getting better at treating sessions themselves as branchable runtime objects.