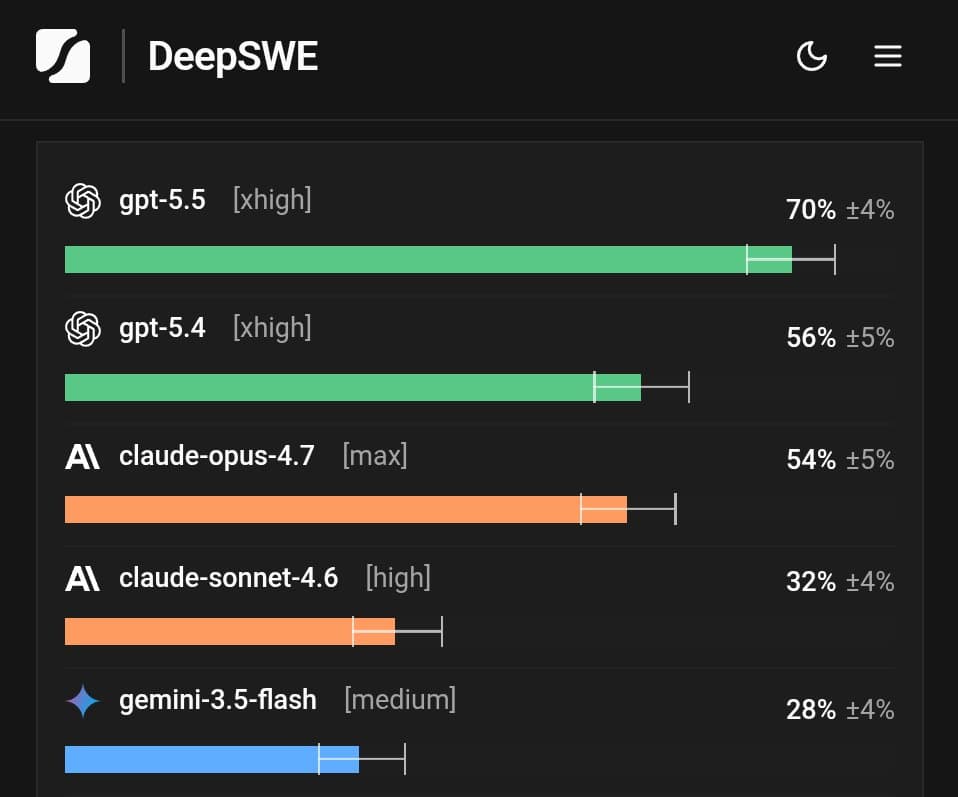
DeepSWE benchmarks GPT-5.5 at 70% on 113 tasks across 91 repos
DeepSWE launched a coding benchmark built from 113 original tasks across 91 repos and five languages, with GPT-5.5 leading at 70%. The setup is meant to better reflect repo search, multi-file edits, and verification in real agent workflows.
TL;DR
- DeepSWE launched as an agentic coding benchmark built from 113 original tasks across 91 repos and five languages, according to _philschmid's task breakdown and WesRoth's overview.
- The headline result is a wider spread than SWE-Bench-style leaderboards usually show: koltregaskes' summary put GPT-5.5 at 70% versus Claude Sonnet at 32%, while rohanpaul_ai's recap listed GPT-5.4 at 56% and Claude Opus 4.7 at 54%.
- DeepSWE is trying to reward repo search, multi-file edits, and behavior-level prompts instead of explicit file-by-file instructions, as koltregaskes and _philschmid both emphasized.
- The debate started immediately: MatthewBerman said DeepSWE matches what engineers report in practice, while bridgemindai called some placements implausible and jediahkatz argued a benchmark-optimized harness can score well without being a practical daily driver.
You can open the official blog, check _philschmid's notes for the harness mechanics, and watch MatthewBerman's video reaction if you want the early practitioner read. The weirdest detail is that a roughly 150-line agent, per OfirPress's post, is being presented as competitive with much heavier vendor coding products on this benchmark.
Task design
DeepSWE's core claim is not just harder tasks, but tasks that hide the file path. koltregaskes said the benchmark asks agents to start from a short behavioral prompt, find the right part of the repo, and implement the change cleanly without being handed modules and functions up front.
The structure, pulled from _philschmid's thread and rohanpaul_ai's recap, looks like this:
- 113 tasks
- 91 repositories
- 5 languages
- prompts about half the length of SWE-Bench Pro's
- solutions requiring 5.5 times more code
- around 7 files touched on average
- roughly 2 times more output tokens
That design is aimed at two weaknesses in older coding evals that DeepSWE's backers keep hitting: public issue contamination, and graders that only recognize one known patch path. koltregaskes argued SWE-Bench often misses day-to-day behavior for those reasons, while rohanpaul_ai said DeepSWE uses original tasks plus behavior-based verification so alternate valid fixes can still pass.
Harness
The benchmark harness is unusually stripped down. According to _philschmid's thread, every model gets one bash tool, the same system instruction, guarded execution, truncation past 10,000 characters, and retries for malformed tool calls instead of hard crashes.
The workflow the harness pushes is also explicit:
- Find the relevant code.
- Reproduce the issue.
- Fix it.
- Verify the fix.
- Check edge cases.
- Submit.
That tight coupling is part of the appeal and part of the caveat. _philschmid noted that the verifier grades against the same workflow, which could favor models that follow instructions literally, while jediahkatz said benchmark harnesses can be tuned in ways that do not translate to practical coding sessions.
Scoreboard
The new leaderboard landed because it separated models that older public boards had kept close together. koltregaskes' comparison framed the main surprise as GPT-5.5 at 70% versus Claude Sonnet at 32%, and rohanpaul_ai's recap added GPT-5.4 at 56% and Claude Opus 4.7 at 54%.
One confusion point was model naming. After people started comparing against Opus, koltregaskes' clarification stressed that the original headline comparison was Sonnet, not Opus.
The early reaction split along familiar lines. TheRealAdamG retweeting dedene and MatthewBerman both said the benchmark feels closer to what engineers see in real coding work, while kimmonismus tied the result to broader sentiment that GPT-5.5 had already improved Codex usage in practice.
Credibility fights
The strongest criticism is not about task size, but about whether some pairwise rankings pass the smell test. bridgemindai's post argued that Gemini 3.5 Flash tying or beating older Opus variants, plus a 26-point gap between Opus 4.7 and 4.6, does not match months of hands-on use.
That disagreement is useful because it isolates what DeepSWE is actually measuring. Supporters are praising it for matching agentic repo work better than older public leaderboards, while critics are saying some outputs still look overfit to the benchmark setup. jediahkatz made that tradeoff explicit: a harness can score well on evals and still be a bad default way to write software.
Mini-swe-agent
One of the sharpest reveals is that DeepSWE is also a harness story. OfirPress's post said mini-swe-agent is about 150 lines of code and performs as well as Claude Code, Codex, and Gemini CLI on the new benchmark.
_philschmid added that mini-swe-agent matched or beat first-party harnesses on the same tasks, with Claude Opus scoring 10 points higher than Claude Code and Gemini 3.1 Pro scoring 20 points higher than Gemini CLI. That turns DeepSWE into a benchmark for model plus harness combinations, not just model weights.
The official source set is already public through the DeepSWE blog, but the more interesting next step is whether other harnesses get run on the same tasks. _philschmid explicitly called out Cursor, Antigravity, and Factory as comparisons he wants to see next.