Gemini 3.5 Flash users report 3x price hikes and broken tool chains one day after launch
Users reported failed harness runs, benchmark misses, broken Calendar and video-editing flows, and later a tripled Antigravity rate limit after Gemini 3.5 Flash launched. Watch real agent workflows closely, because the speed gains are arriving with higher spend and unstable behavior.
TL;DR
- Google rolled out Gemini 3.5 Flash globally in the Gemini app for free, but developers quickly fixated on a very different number: the API price moved to $1.50 input and $9 output per million tokens, which scaling01's pricing screenshot and AiBattle_'s comparison both framed as a 3x jump over Gemini 3 Flash.
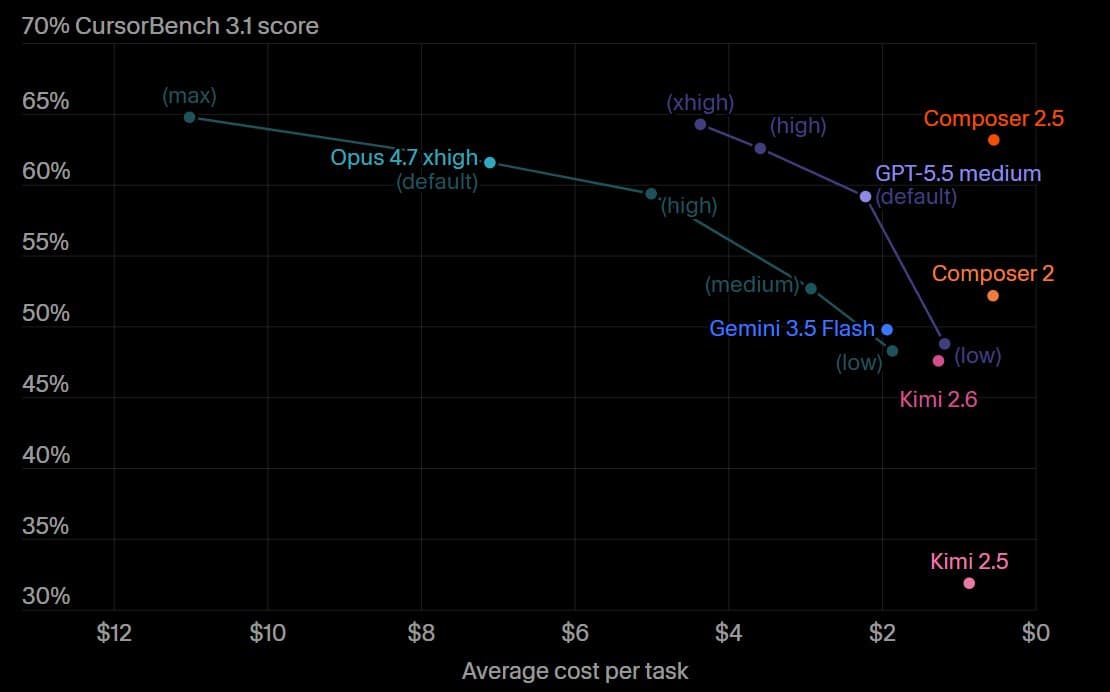
- Third party evals split hard between speed and value: BridgeBench's speed repost put Gemini 3.5 Flash at 581 tokens per second, while bridgemindai's CursorBench update, petergostev's BullshitBench update, and AiBattle_'s Artificial Analysis cost chart all argued that the extra speed came with weak cost effectiveness.
- Hands-on agent reports were even messier. kwindla's agent benchmark thread found a new top score on a multi-turn task agent eval, but rishdotblog's harness report said the model was "totally broken" outside Google harnesses and arohan's agent UX screenshot showed a rigid, over-scripted inner monologue in coding workflows.
- Gemini app users reported breakage outside benchmarks too: kchonyc's Calendar complaint said a PDF-to-Calendar workflow stopped working after the update, while koltregaskes's video workflow post described greyed out video creation controls and a chat state reset mid-project.
- Google kept widening the rollout anyway. Google's AI Ultra pricing post and GeminiApp's plan update pushed new $100 and $200 Ultra tiers around the launch, then OfficialLoganK's rate-limit update said Antigravity tripled rate limits across all tiers the next day.
Google's own materials say Gemini 3.5 Flash is headed almost everywhere: the Gemini app blog post ties Gemini Spark to the Antigravity harness, the model page exposes the 1M context window, and Simon Willison's notes pulled out the buried details, including a January 2025 knowledge cutoff and Google's new Interactions API. Meanwhile you can browse kwindla's eval code, inspect the Gradient Bang task benchmark, and check the BullshitBench viewer that fueled part of the backlash.
Pricing
The launch landed with Flash branding and near-Pro pricing. According to haider1's pricing comparison, Gemini 3.5 Flash sat much closer to Gemini 3.1 Pro Preview than to earlier Flash models.
The price complaints were not just about list rates. Several benchmark runners said the model also spent more tokens to finish work:
- AiBattle_'s Artificial Analysis chart put the AA Intelligence Index cost at $1,552 for Gemini 3.5 Flash versus $892 for Gemini 3.1 Pro.
- theo's cost-performance thread said GPT-5.5 Medium reached a higher AA score with 22 million tokens and $1,199 total cost, while Gemini 3.5 Flash used 73 million tokens and $1,522.
- scaling01's PencilPuzzleBench post claimed Gemini 3.5 Flash was 7.46x more expensive than GPT-5.5 xhigh on that eval.
- scaling01's WeirdML comparison said the model barely improved over Gemini 3 Flash on WeirdML while becoming 3.5x more expensive there.
That made "Flash" feel like a label with legacy expectations attached to it, not a cheap tier.
Benchmarks
The benchmark picture was not uniformly bad. It was weird.
On the positive side, kwindla's thread said Gemini 3.5 Flash with a high thinking budget became the top model on a 32-turn task-agent benchmark, with a per-turn P50 under two seconds. The same thread said the model improved tool calling over earlier Gemini 3 variants, even though median time to first token stayed around 1 second.
On the negative side, other public evals were much colder:
- bridgemindai's CursorBench update placed Gemini 3.5 Flash at 49.8 percent and ranked it below GPT 5.5 Low and Opus 4.7 Low.
- petergostev's BullshitBench update said it scored below Gemma 4 in that benchmark's hallucination-style setup.
- bridgemindai's subscription complaint called it #14 on BridgeBench and #22 in reasoning.
- BridgeBench's speed repost credited it with a benchmark-leading 581 tokens per second.
The cleanest read from the evidence pool is that Gemini 3.5 Flash looked best when the test rewarded throughput plus long multi-turn completion, and much worse when people cared about cost-normalized coding quality or reliability.
Harnesses
The loudest complaints came from people running the model inside agent harnesses instead of single-turn chats.
The reports clustered around three failure modes:
- Harness mismatch: rishdotblog's report said Gemini 3.5 Flash was "totally broken in non-Google harnesses" and slower and worse than GPT-5.5 or Opus at tool chaining.
- Over-scripted agent narration: arohan's screenshot showed the model repeatedly speaking in an "I will" pattern during a coding task, then arohan's follow-up suggested the summarization model should sound more like an inner voice.
- Volatile real-task quality: bridgemindai's Flappy Bird demo called its coding output "pure slop," while petergostev's video summary said it sometimes generated best-in-class results and sometimes crashed out or did something strange.
Google's own product framing helps explain why this gap mattered. simonw's linked quote highlighted the line that Gemini Spark "runs on Gemini 3.5 and uses the Antigravity harness," so harness behavior was part of the product story on day one, not an edge case.
Gemini app
The web and app rollout produced concrete regression reports within hours.
Two reports were especially specific:
- koltregaskes's post described a greyed out "Create video" action, unclear credit exhaustion, and a multi-video project that suddenly forked into a fresh chat on the fifth step.
- kchonyc's post said Gemini stopped turning schedules from PDFs or HTML into Google Calendar entries after the update, then kchonyc's later follow-up said the Calendar integration was still broken the next morning.
Those issues landed alongside a broader UI refresh. testingcatalog's UI preview had already spotted a new Gemini interface, a thinking effort selector, and a usage-limits tab before I/O. The official rollout posts, GeminiApp's free rollout clip and OfficialLoganK's feedback request, showed Google treating the model as a live product surface that would be tuned in public.
Antigravity rollout
Google widened access even as complaints piled up.
Three rollout details stood out:
- Subscription packaging changed at the same moment the model shipped. Google's plan announcement introduced a new $100 per month AI Ultra plan, while GeminiApp's pricing post cut the top Ultra tier from $250 to $200 and promised 5x Gemini app limits versus Pro on the new lower tier.
- The ecosystem moved quickly. OpenCode's support announcement added Gemini 3.5 Flash on day one with a 1M context window, and Jerry Liu's managed agents post plugged Gemini Managed Agents into LlamaParse and LiteParse.
- Google loosened the faucet a day later. OfficialLoganK's rate-limit update said Antigravity had tripled rate limits across all tiers so users could push 3.5 Flash harder.
That last update matters because the launch story did not end at ship. It kept changing under load, with new limits, new packaging, and more surfaces exposing the same fast, expensive, still-settling model.