Cohere releases Command A+ under Apache 2.0 with 25B active params and 2x H100 deployment
Cohere open-sourced Command A+, a 218B MoE multimodal model with 25B active parameters, 48-language support, and deployment starting at two H100s. Artificial Analysis put it at 37 on its Intelligence Index and 281 tok/s, and vLLM plus Transformers added support.
TL;DR
- Cohere shipped cohere's launch post as an Apache 2.0 open-weights release, and Aidan Gomez said it is the company's first fully open Apache 2 model.
- The model is a 218B mixture-of-experts system with 25B active parameters, according to Jay Alammar's summary and mervenoyann's notes.
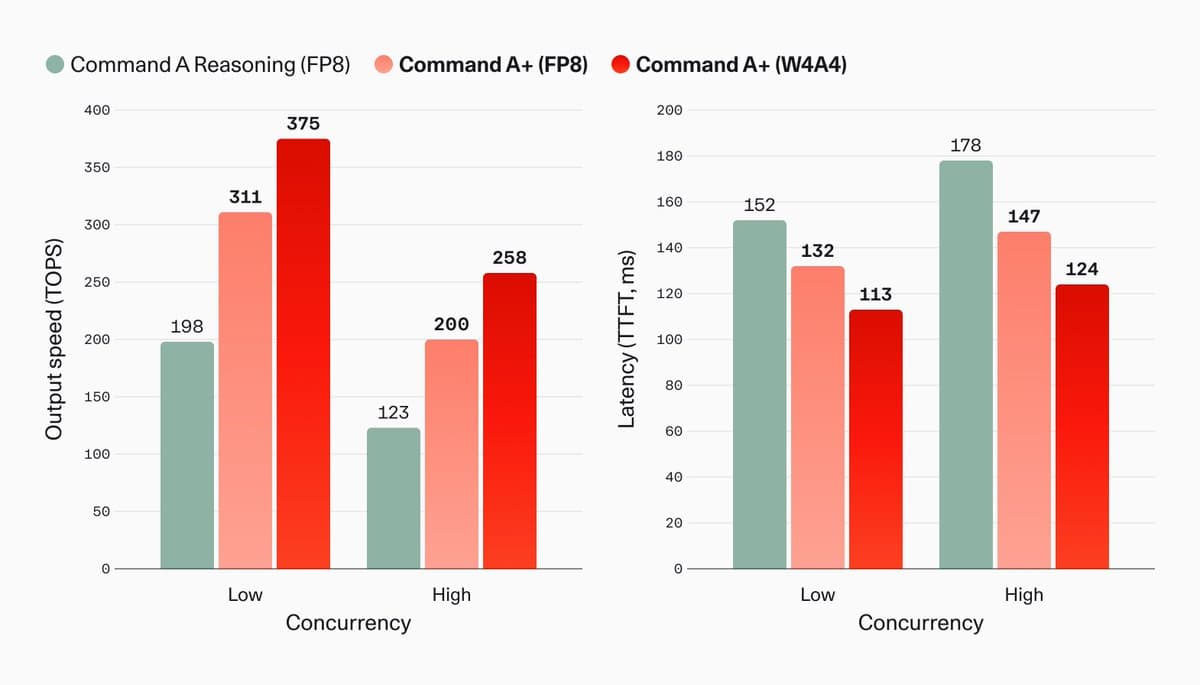
- Cohere says its speed claim is more than 2x higher output speed with 30% lower latency than earlier Command A models, while Artificial Analysis measured about 281 output tokens per second on Cohere's API.
- Hardware efficiency is the headline pitch: Cohere's deployment note says it can run on as few as two H100s, while vLLM's day-0 support post tied that claim to a W4A4 serving setup.
- The model adds native support for 48 languages and multimodal text-plus-image inputs, per Cohere's language post and Jay Alammar's model summary.
The official Command A+ blog post pairs the open-source release with a Hugging Face drop for both W4A4 weights and bf16 weights. Artificial Analysis' model page puts it at 37 on its Intelligence Index and 63% on MMMU-Pro. You can also see vLLM's support announcement, plus mervenoyann's note that Transformers support landed on day one.
Apache 2.0 and the weight drop
The license shift is the biggest story here. Cohere framed Command A+ as an enterprise-grade agentic model released under Apache 2.0, and Aidan Gomez called it Cohere's first fully open Apache 2 model.
The weight drop is already split across deployment profiles:
That makes this less of a teaser open release and more of a real packaging move. Clement Delangue's post singled out the Apache 2.0 license, which tells you what the open model crowd noticed first.
Model shape and deployment floor
The public specs that surfaced across the evidence are unusually concrete:
- 218B mixture-of-experts total parameters, from Jay Alammar's summary
- 25B active parameters, from mervenoyann's notes
- 128K context window, from mervenoyann's notes
- Text and image inputs, from Jay Alammar's summary
- Native support for 48 languages, from Cohere's language post
Cohere's main pitch is that this package still fits a modest deployment footprint for its class. The company's launch thread says two H100s, while Jay Alammar described the floor as one B200.
Speed and benchmark profile
Cohere's own launch thread stays high level on capability, saying the model improved on agentic, reasoning, and multi-step tasks. Artificial Analysis adds the sharper benchmark picture:
- Intelligence Index: 37, via Artificial Analysis' model page
- Output speed: about 281 tokens per second on Cohere's API, according to Artificial Analysis
- AA-Omniscience Non-Hallucination: 86%, roughly 3 points ahead of the next-best model, per Artificial Analysis
- AA-Omniscience headline score: -4, because low accuracy was paired with very low hallucination, per Artificial Analysis
- MMMU-Pro: 63%, according to Artificial Analysis
- HLE: about 11%, GPQA Diamond: about 76%, Terminal-Bench Hard: about 25%, SciCode: about 38%, all from Artificial Analysis
The interesting split is speed versus frontier depth. Artificial Analysis says Command A+ is quick for its intelligence class, but still weak on the hardest science and agentic coding benchmarks.
Day-one serving support
The ecosystem response was immediate. vLLM announced day-one support and repeated the 218B MoE, 25B active, Apache 2.0, multimodal, 48-language, 2x H100 W4A4 packaging story.
That lines up with mervenoyann's post, which flagged Transformers support on day one, and with the official release links that already point straight to downloadable weights instead of a waitlist or managed-only endpoint. For engineers, Christmas came early for practical open model shipping.