Perplexity benchmarks Qwen3 235B on GB200 NVL72: NVLS latency drops from 586 µs to 313 µs
Perplexity published serving results for post-trained Qwen3 235B on NVIDIA GB200 NVL72 and argues Blackwell materially outperforms Hopper for large MoE inference. The deltas show up in NVLS all-reduce latency, MoE prefill combine time, and high-speed decode throughput.
TL;DR
- perplexity_ai's announcement says Perplexity is serving a post-trained Qwen3 235B on NVIDIA GB200 NVL72, and frames Blackwell as a real inference upgrade for large MoE workloads, not just a training box.
- According to perplexity_ai's prefill-versus-decode breakdown, the gain is split across two different bottlenecks: prefill stays compute-bound, while decode is dominated by latency and memory movement.
- perplexity_ai's benchmark post puts concrete numbers on that gap: NVLS all-reduce latency fell from 586.1 microseconds on H200 to 313.3 microseconds on GB200, while MoE prefill combine time at EP=4 dropped from 730.1 microseconds to 438.5 microseconds.
- The same benchmark post argues GB200 keeps much higher decode throughput at high token speeds, which is the part of the curve that usually breaks first on big MoE serving.
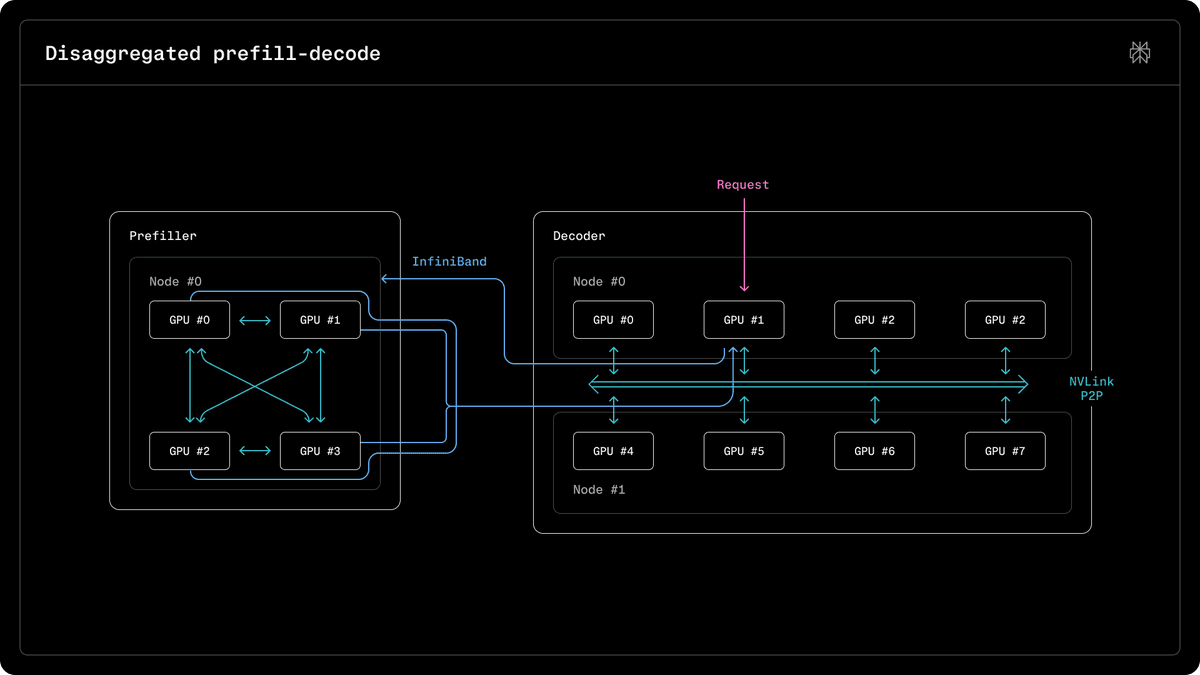
- In AravSrinivas's follow-up, Perplexity adds that GB200 changes how it does prefill and decode disaggregation for models like Qwen, which hints that the rack topology matters as much as the raw chip specs.
You can read the full Perplexity paper, and the short thread is unusually direct about where the gains come from: prefill versus decode splits the workload by bottleneck, while the benchmark post gives exact latency deltas instead of vague speedup language.
Prefill and decode
Perplexity's cleanest point is that "inference" is not one workload. In perplexity_ai's thread, prefill is described as compute-bound, where Blackwell's Tensor Cores, memory bandwidth, NVLink, and SHARP reductions help most.
The decode phase is a different story. The same post says decode is latency and memory bound, and credits GB200's rack-scale NVLink domain with unlocking parallelism that Hopper could not reach in the same way.
NVLS latency
The headline delta is communication latency. According to perplexity_ai's benchmark post, NVLS all-reduce latency drops from 586.1 microseconds on H200 to 313.3 microseconds on GB200.
Perplexity reports a second win in MoE prefill at EP=4:
- combine time: 730.1 microseconds on H200
- combine time: 438.5 microseconds on GB200
Those are the useful numbers in the thread because they tie the platform claim to one concrete subsystem: expert communication.
Serving stack
Perplexity's summary of the stack in its final thread post names four ingredients behind the result:
- prefill and decode disaggregation
- Blackwell-native quantization
- custom kernels
- rack-scale NVLink
The official write-up lives in the research article. The tweet thread does not unpack each optimization, but it does make one thing explicit: Perplexity is treating the GB200 rack as a serving system, not just a faster drop-in GPU.
Disaggregation
Arav Srinivas writes in his post that GB200 "changes how one does the prefill and decode disaggregation" for large MoEs like Qwen. That is the most specific architectural claim outside the main thread.
It adds one new detail the benchmark tweet only implies: Perplexity is not just measuring faster kernels on newer silicon, it is changing the serving layout around the model because the GB200 fabric makes different tradeoffs viable.