Ramp introduces PorTAL with half-cost LoRA porting across Qwen and Gemma models
Ramp published PorTAL, a method that learns a reusable task representation once and recalibrates only a thin converter when moving that task to a new base model. In reported Qwen and Gemma experiments, it matched per-task LoRA accuracy while cutting data and cost roughly in half.
TL;DR
- Ramp says PorTAL learns a task once, then ports it across base models by generating LoRA adapters, which RampLabs' launch post frames as a way to avoid retraining fine-tunes from scratch on every new model release.
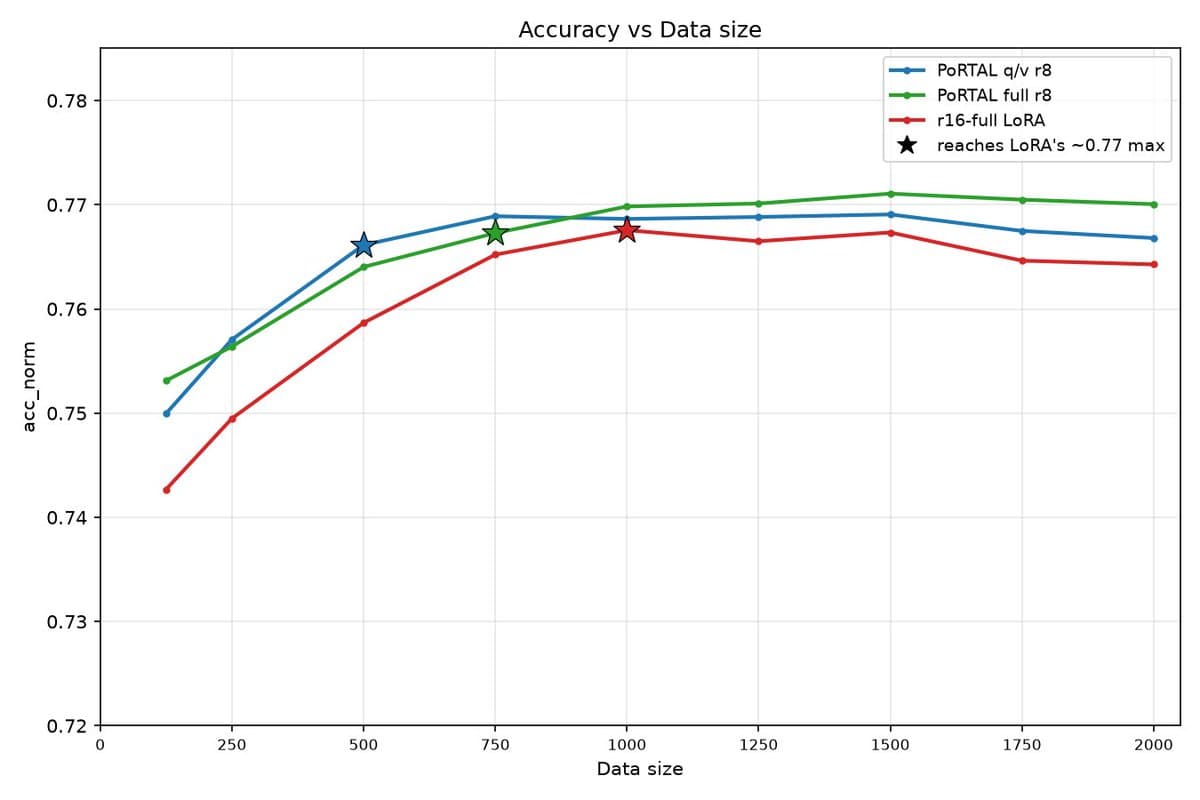
- In Ramp's reported experiments, RampLabs' results thread says PorTAL matched per-task LoRA accuracy on Qwen and Gemma transfers while using half the data and half the cost.
- The core trick, according to RampLabs' architecture post, is to keep the reusable task representation and decoder frozen while recalibrating only a thin converter for each new target model.
- Ramp linked RampLabs' write-up pointer to a longer write-up with baselines and ablations, which suggests this is more than a teaser thread.
Ramp is pitching a very specific pain point: model churn makes fine-tunes expensive to maintain. You can jump from the launch post to the architecture sketch and then to the full write-up link without much hand-waving in between.
Retraining every time
Ramp says every new base model release had been forcing it to retrain task adapters from scratch. PorTAL is meant to amortize that cost by learning a reusable task representation once, then reusing it when the base model changes.
That makes this less about squeezing a few extra benchmark points out of LoRA, and more about reducing the switching tax when teams want to move a tuned workflow onto a newer model.
Task latent, hypernet, thin converter
Ramp's thread breaks the method into three moving parts:
- a reusable task representation
- a hypernetwork and linear aligner that generate LoRA adapters for a frozen base model
- a thin converter that gets recalibrated when the task is ported to a new model
The freeze pattern is the interesting bit. Ramp says the task representation and core decoder stay fixed during porting, so the per-model work is narrowed to that converter layer.
Qwen to Gemma results
Ramp says it trained on Qwen3-1.7B and Qwen3-4B, then calibrated on Qwen3-8B and Gemma-3-4B. In those settings, the company says PorTAL matched per-task LoRA accuracy while cutting both data use and cost by half.
The thread also says the up-front task learning cost gets amortized over future ports, which is the whole economic claim here. The more often a team changes base models, the more that reuse matters.
Full write-up and fine-tuning context
Ramp linked to a fuller write-up with baselines and ablations, so there is at least a longer technical artifact behind the thread. Separately, omarsar0's reaction post called fine-tuning underexplored and argued that "agentic fine-tuning" is about to matter a lot more.
That reaction is broader than PorTAL itself, but it helps explain why a portability layer for adapters is getting attention now.