Step 3.7 Flash opens 30-day free access for Hermes users via Nous Portal
A day after launch, Nous made Step 3.7 Flash free for 30 days to Hermes users through Nous Portal. The access window landed alongside fresh vLLM/NIM and MLX-VLM support, making the model easier to test in both local and production stacks.
TL;DR
- NousResearch said Step 3.7 Flash is free for 30 days through Nous Portal, aimed at Hermes Agent users testing an MoE vision-language model for coding, search, and multimodal agent work.
- Teknium added that the Portal access comes with a longer-term availability guarantee than the usual short-lived free model drops.
- Day-one distribution was already broad: OpenRouter put the model on its router, modal offered hosted support, and vllm_project shipped vLLM serving with quantized weights.
- The runtime story is unusually complete for a small launch, because vllm_project tied Step 3.7 Flash to NVIDIA NIM and DGX Station deployment while TheZachMueller surfaced immediate MLX-VLM support for Apple hardware.
You can grab the free window in the Nous Portal, check the hosted SKU on OpenRouter, and see the NVIDIA-side serving path on the DGX Station vLLM page. The interesting bit is how many inference surfaces were ready inside 24 hours: OpenRouter for quick trials, Modal for hosted runs, vLLM and NIM for production stacks, and MLX-VLM for local Apple setups.
Nous Portal access
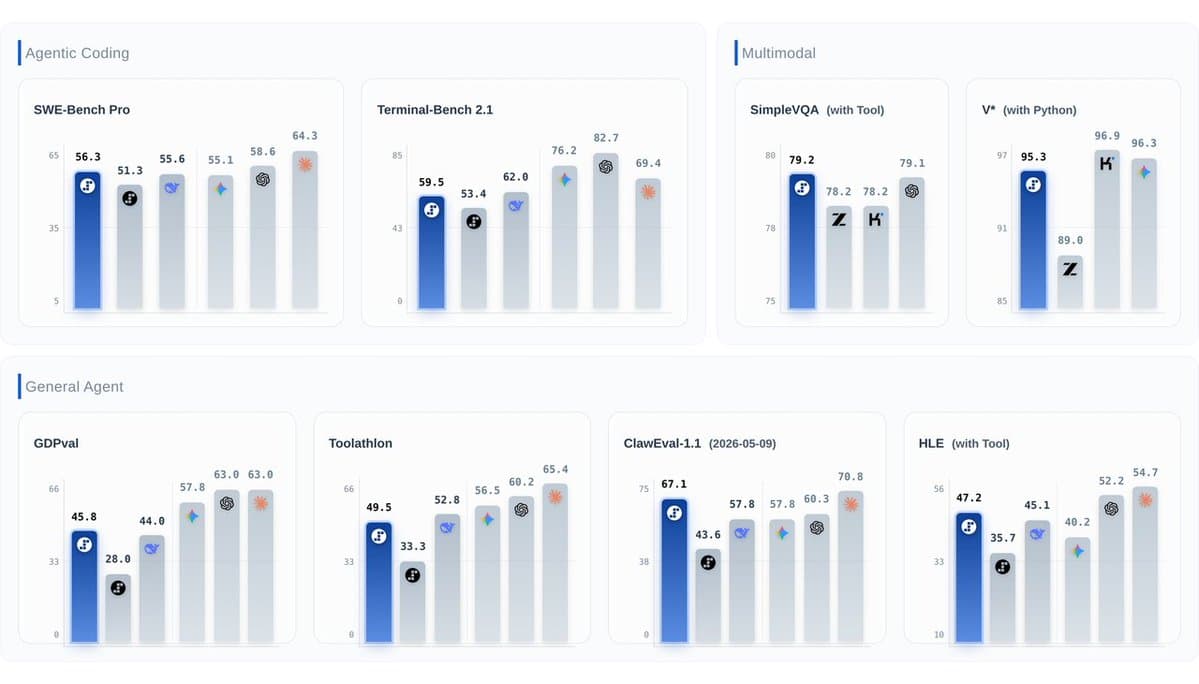
Nous pitched the offer as a 30-day free run for Hermes Agent users, one day after Step 3.7 Flash launched. The post described the model as a new MoE vision-language model tuned for agent efficiency, coding, search, and multimodal workflows.
Teknium's follow-up matters because it narrows the practical question engineers always ask first: how long will the free tier stick around. He wrote that this one comes with a relatively long-term guarantee, rather than disappearing on short notice.
What shipped on day one
By launch day, Step 3.7 Flash was already spread across several common test and deployment surfaces:
- OpenRouter described it as a multimodal MoE for image, video, and text, with 11B active parameters out of roughly 196B total, plus selectable reasoning levels.
- modal advertised day-zero support with 198B total parameters, 11B active, a 256K context window, and three reasoning levels.
- kilocode said the open-weight model was live in Kilo at roughly 400 tok/s.
- vllm_project said vLLM support shipped immediately with FP8 and NVFP4 quantized weights, native tool calling, reasoning parsing, and built-in MTP speculative decoding.
The numbers vary slightly by post, 196B versus 198B total parameters, but the distribution story is clear: this was not a single-endpoint release.
Serving stack
The strongest infrastructure signal came from the vLLM side. Its launch note tied the model to long-context repo and document work, native image plus text input, and ready-to-serve quantized weights.
A day later, vLLM connected that same model to NVIDIA's DGX Station stack and NIM containers. That gives Step 3.7 Flash a cleaner path from quick benchmarking to local workstation runs and production serving than most open-weight releases get in their first 48 hours.
Apple and local runtimes
The local story was not just CUDA. TheZachMueller boosted Ivan Fioravanti's MLX-VLM update adding Step 3.7 Flash conversion, vision support, and text support, which puts the model into the Apple-side inference toolchain immediately.
That lands next to the hosted and datacenter options above: OpenRouter for API access, Modal for managed serving, vLLM and NIM for production infra, and MLX-VLM for local experimentation on Apple hardware. For a low-key open-weight release, Christmas came early for inference stack nerds.