Open-source software for faster fine-tuning and inference of large language models.
Recent stories
Inkling's 1-bit GGUF ran in llama.cpp at 30–40 TPS, and TokenSpeed added day-zero support with a flat KV cache pool. Arena posts put Inkling #10 among open models in frontend code and text, while docs drew scrutiny.
Thinking Machines released Inkling with Apache 2.0 weights, 975B parameters, 41B active parameters, text/image/audio support, and up to 1M context. vLLM, SGLang, Modal, Databricks, and Vercel added day-zero support.
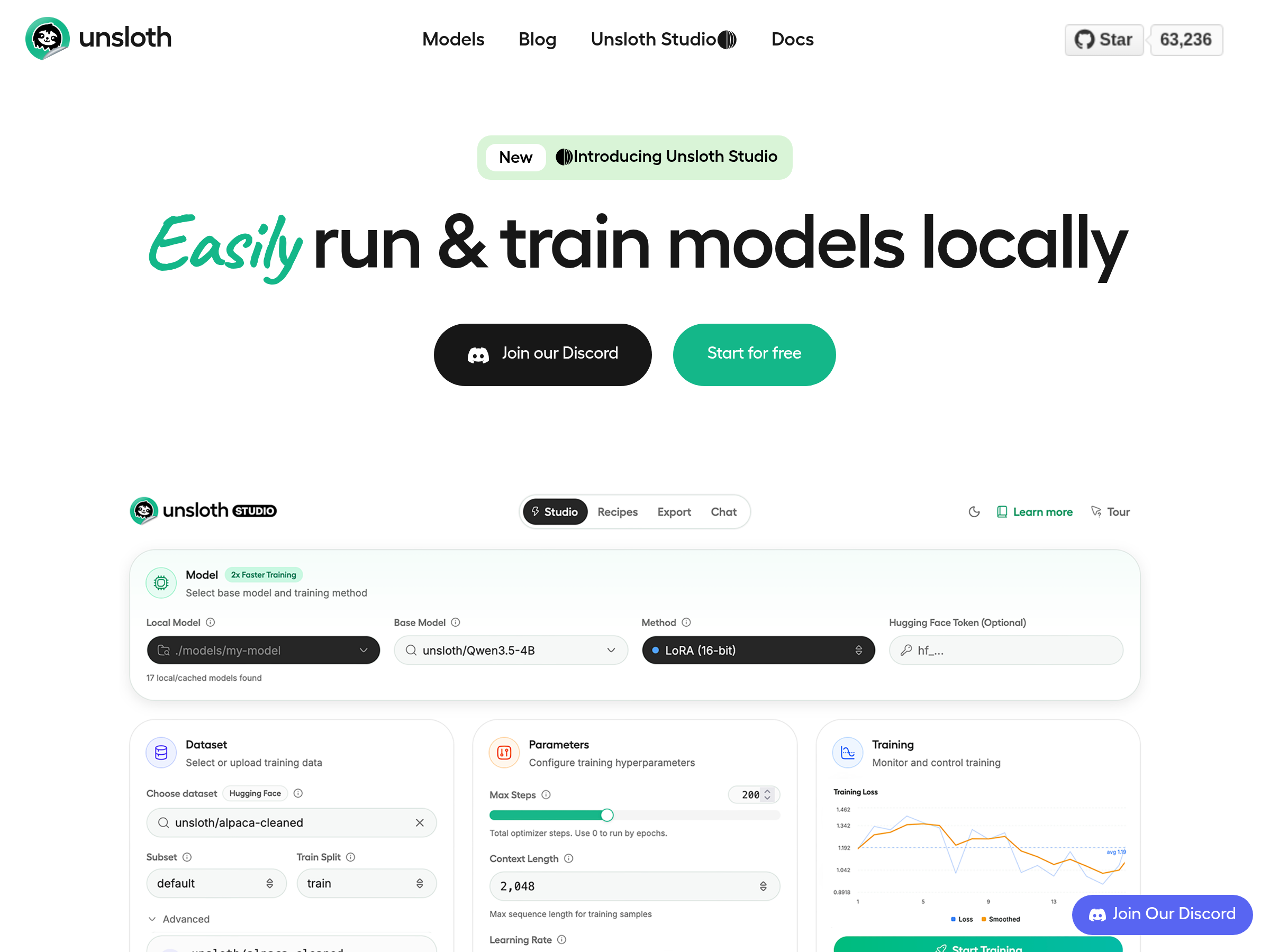
Unsloth released Qwen3.6 NVFP4 quants and claimed 2.5x GPU speedups, including 27B on 24GB VRAM. Follow-up notes warned vLLM users that Marlin or default backends can make W4A4 Qwen inference 2–2.5x slower.
MiniMax published M3 weights on Hugging Face with 428B total parameters, 23B active parameters, 1M context, and multimodal support. Unsloth quickly added local GGUF builds, so teams can try 2-bit runs at 138GB RAM or VRAM and 3-bit at 165GB.
Cohere added MLX support, Unsloth GGUFs, oMLX work, and updated docs for North Mini Code two days after launch, with llama.cpp still under review. The broader runtime coverage makes the 30B coding model easier to run on local Mac, quantized, and self-hosted stacks.
Google's new diffusion text model picked up same-day runtime support: vLLM added native diffusion-LM serving, Unsloth shipped GGUFs, and llama.cpp got local setup guidance. That shortens the path from release to local and hosted evaluation.
Unsloth said its updated Qwen3.5 MTP GGUFs now run about 1.8x faster after llama.cpp added spec-draft-p-min 0.75 and renamed the mode to draft-mtp. The update also raises draft-token settings and expands the small-model MTP set for local runners.