Cowork supports 200-skill CLAUDE.md workflows with progressive loading
Practitioners documented Cowork and Claude Code setups that use shared CLAUDE.md files, progressive skill loading, and agent memory instead of blank-session prompting. That matters for vibe-coders because PM, design, and implementation workflows can compound across sessions, though some stronger performance claims came from third-party posts.
TL;DR
- The core workflow in this evidence set is a shared repo plus a shared
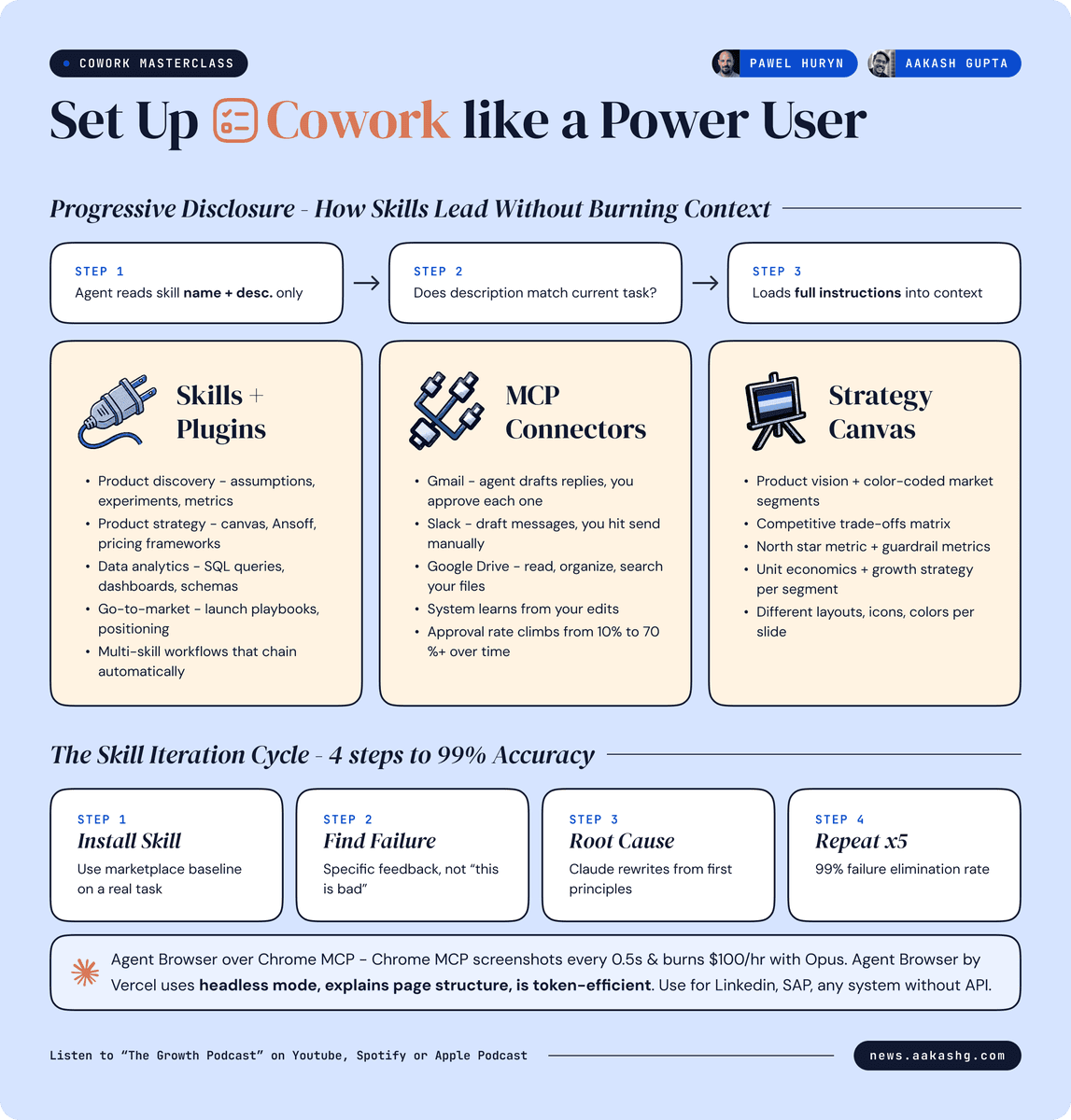
CLAUDE.md, where Cowork and Claude Code both load the same context instead of starting from a blank prompt every session, according to aakashgupta's Cowork versus Claude Code post and aakashgupta's compounding system post. - aakashgupta's 200-skill thread says Pawel Huryn runs about 200 skills through progressive disclosure, where the agent first reads only names and one-line descriptions, then loads full instructions only for the matching task.
- A separate Japanese explainer from 7_eito_7's CLAUDE.md thread frames the same pattern as turning Claude into a consistent project teammate, with
CLAUDE.md,MEMORY.md, andERRORS.mdstoring stack rules, decisions, and past failures. - The split between Cowork and Claude Code is architectural, not philosophical: aakashgupta's Cowork ceiling post lists hooks, subagents, local MCP scoping, lifecycle control, and HTML generation as the features that appear once teams move into Code.
- The strongest practical claim in the evidence is not raw prompt quality but iteration: aakashgupta's skill iteration post describes a loop where failures get rewritten into the skill itself, while Anthropic's own large-codebase best practices post points to teams operationalizing Claude Code across large repos.
You can read Anthropic's large-codebase guide, its separate post on HTML as a working surface in Claude Code, and the new cache diagnostics docs. The tweet evidence adds the more interesting bit: aakashgupta's router-pattern post reduces CLAUDE.md to six routing items, his Cowork ceiling post treats Code as the layer where hooks and subagents show up, and his agent-team post describes PM, design, and implementation agents wired together like a real squad.
Shared context
The repeated pattern across the primary tweets is one repo, one memory surface, multiple interfaces. aakashgupta's Cowork versus Claude Code post says Cowork, Claude Code, and even a heavier editor setup can all sit on top of the same files and the same CLAUDE.md.
That shifts the unit of work from prompt-writing to system-building. In aakashgupta's framing, the difference is whether today's context disappears or compounds into the next session.
Anthropic's own best-practices post sits cleanly under that framing. The company describes teams running Claude Code across monorepos, legacy systems, and microservices, which matches the evidence pool's emphasis on reusable project structure over one-off chats.
CLAUDE.md as a router
The most concrete design idea here is that CLAUDE.md stays short. aakashgupta's router-pattern post says Pawel Huryn's file has six items: project description, file structure map, identity context, knowledge routing, workflow pointers, and a three-line self-improving prompt.
Instead of stuffing style guides, examples, metrics, and procedures into one giant file, the router points to where each kind of knowledge lives. The tweet breaks it out like this:
CLAUDE.md: project description, file map, identity, routing, workflow pointersvoice/or equivalent: writing style rulespatterns/: good and bad examples- platform folders such as
x/andlinkedin/: surface-specific instructions - domain knowledge files: hypotheses, confirmed rules, metrics
skills/: detailed procedures
The Japanese thread from 7_eito_7 lands on the same architecture from another angle. It describes CLAUDE.md as the place for stack, prohibitions, style, protected areas, and past decisions, then extends the memory layer with MEMORY.md for historical decisions and ERRORS.md for failure logs.
Progressive loading and 200 skills
The most surprising claim in the set is not the number of skills, it is the loading strategy. aakashgupta's 200-skill thread says the agent sees only each skill's name and one-sentence description first, then pulls full instructions only when the task matches.
That progressive-disclosure model does two jobs at once:
- It keeps large skill libraries from flooding context.
- It turns a skill marketplace install into a starting point, not a finished system.
- It makes feedback operational, because corrections get rewritten into the skill instead of repeated manually.
The iteration loop shows up repeatedly in the evidence. aakashgupta's skill iteration post describes feeding a concrete failure back to Claude, asking for root cause, then rewriting the skill from first principles. his existence-check post adds another pattern: expensive artifacts like PRDs or launch docs start with a gate that checks whether the document should exist at all.
Where Code pulls ahead
The tweets are unusually specific about where Cowork ends. aakashgupta's Cowork ceiling post lists six capabilities that do not exist in Cowork: explorer view, hooks, subagents, local MCP server scoping, lifecycle control over tool calls, and HTML generation.
The image attached to that post makes the split easy to scan, and it also ties those features to a "second brain for agents" that extracts hook patterns, sound bites, voice archetypes, and engagement metrics by domain.
Anthropic's HTML post gives one official reference point for that list. The linked article is explicitly about using HTML as a working medium inside Claude Code, which lines up with the Cowork ceiling post treating HTML generation as one of the practical reasons teams graduate to Code.
Anthropic also shipped cache diagnostics in Claude Console, surfaced in ClaudeDevs' cache diagnostics post. That feature does not change the Cowork versus Code split directly, but it pushes the same operating model: stable prompts, visible changes, and less guesswork about what broke reuse.
Agent teams and the PM orchestrator
The most elaborate workflow in the evidence is aakashgupta's agent-team post, which describes five specialist agents, researcher, discovery, designer, engineer, implementer, with a PM orchestrator routing tasks but never writing code.
The important detail is where fixes land. When a feature breaks, the repair goes into the agent that built it and into the shared CLAUDE.md, then the run starts again. That treats failure as infrastructure work, not as a one-off patch.
A related thread from aakashgupta's prototyping ladder post says Boris Cherny's team killed roughly 80% of Claude Code feature variants before shipping and that Sachin Rekhi built baseline UI templates plus analytics into prototypes. The common move across both posts is iteration upstream, before engineering work hardens.
Backlog resurrection
The cleanest end-state example in the set is not a new skill or file, it is a scheduling tactic. aakashgupta's Monday morning ritual post says the move is to sort backlog tickets by oldest first, build one with Claude Code, and push a branch without touching sprint capacity.
Its three steps are concrete enough to stand alone:
- Pick the oldest approved ticket, not the newest priority debate.
- Paste the exact acceptance criteria into Claude.
- Push an isolated branch and share the preview.
That section introduces something the rest of the story only implies. Once context, skills, and agent roles are already encoded, the output is not a better chat session. It is a branch in the repo.