Anthropic reports Claude Code task success stays within 7 points of software engineering across occupations
Anthropic published data from 400,000 Claude Code sessions, finding average task value rose 27% and verifiable success across occupations stayed within seven points of software engineering. The report gives teams a concrete baseline for where coding agents already generalize and where domain expertise still changes outcomes.
TL;DR
- Anthropic said its new occupation comparison thread is based on 400,000 Claude Code sessions collected from October 2025 through April 2026, with more than half focused on writing or repairing code and nearly one in five on operating software.
- According to Anthropic's session breakdown, the estimated market value of the average Claude Code task rose 27% over that six-month window.
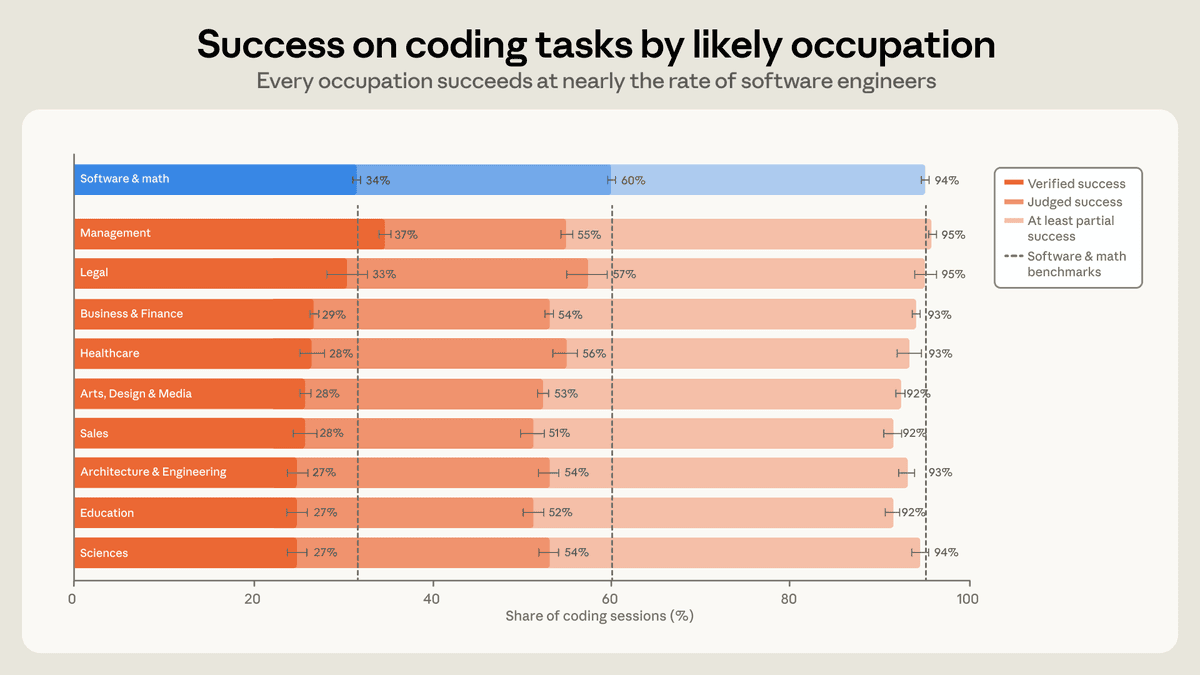
- On Anthropic's strictest success measure, which required verifiable evidence like committed code, the company's occupation chart put every field it studied within seven percentage points of software engineering.
- Anthropic also found that its domain-expertise thread linked stronger domain expertise to higher success rates, while saying the gap between intermediate and expert users was modest.
- Outside reaction from Dan Breunig's read focused on the surprisingly low absolute success numbers, including Anthropic's own claim that expert users see full success on 65% of tasks.
You can read Anthropic's full report, skim the occupation comparison thread, and check the domain-expertise post for the part that will probably get the most internal forwarding: Claude Code's success rates did not collapse outside software engineering. The weirder detail came from Dan Breunig's reply, which fixated less on the seven-point occupation spread and more on the fact that even experts only hit full success 65% of the time. Wes Roth's summary also surfaced the report's other big number, a 27% increase in estimated task value.
400,000 sessions
Anthropic said it ran a privacy-preserving analysis over 400,000 Claude Code sessions between October 2025 and April 2026. In the company's thread, more than half of those sessions were classified as writing or repairing code, while nearly 20% were classified as operating software.
That matters because this is not a narrow benchmark slice. Anthropic is describing production usage patterns across hundreds of thousands of real sessions, not just eval runs or curated demos, according to its methodology summary.
Task value
Anthropic's most concrete trend line was economic, not model quality. In the task-value post, the company said it mapped each session's work to comparable freelance-marketplace pricing and found the average session value rose 27% from October to April.
The report frames that as evidence that Claude Code is being used for more valuable work over time, per Anthropic's report announcement. The tweet evidence does not break out which categories drove the increase, but it does pin the change to a six-month window rather than a one-off spike.
Occupation gap
Anthropic's headline result is unusually direct: on its toughest success metric, every occupation it studied landed within seven percentage points of software engineering. The company's post defined that metric as requiring verifiable evidence that a goal was completed, such as committed code.
That is the part technical teams will keep around as a baseline. Anthropic is effectively saying Claude Code's usable range already extends beyond traditional software engineering work, and Wes Roth's summary repeats the same seven-point spread from the report.
Domain expertise
Anthropic said users with stronger domain expertise were more likely to succeed, based on the questions they asked and the vocabulary they used about a subject. But the same thread added that the difference between intermediate and expert users was modest.
That is a narrower claim than "expertise does not matter." It says some familiarity with the domain may already be enough to use a coding agent effectively inside that domain, according to Anthropic's wording.
Success-rate skepticism
The sharpest outside reaction came from Dan Breunig, who argued in his reaction post that weaker Claude Code users will hit limits much faster than skilled engineers. In a follow-up, Breunig highlighted Anthropic's own numbers showing 90% of expert tasks reached at least partial success, while 65% reached full success.
Breunig called those rates "wildly low," and his post is a useful reminder that Anthropic's cross-occupation result says more about relative spread than absolute reliability. He also used a separate reply on the charts to complain that the report's visualizations made the findings harder to read than they needed to be.