Anthropic launches Claude Fable 5 with Opus fallback and $10/$50 MTok pricing
Anthropic released Fable 5 as its public Mythos-class model and routes some sensitive prompts to Opus 4.8. Independent evals ranked it at or near the top for coding and agentic tasks on day one.
TL;DR
- Anthropic shipped Claude Fable 5 as a public, guarded version of the same underlying model behind Mythos 5, while claudeai's Mythos 5 post says the less-restricted variant is limited to Project Glasswing partners and a future trusted-access program.
- Sensitive cybersecurity, biology, chemistry, and distillation prompts can route to Opus 4.8, and claudeai's safeguards thread says those fallbacks fire in under 5% of sessions on average.
- Pricing landed at $10 per million input tokens and $50 per million output tokens, which Anthropic's launch post says is less than half the price of Mythos Preview, while ClaudeDevs' setup thread notes fallbacked UI requests are billed at Opus rates.
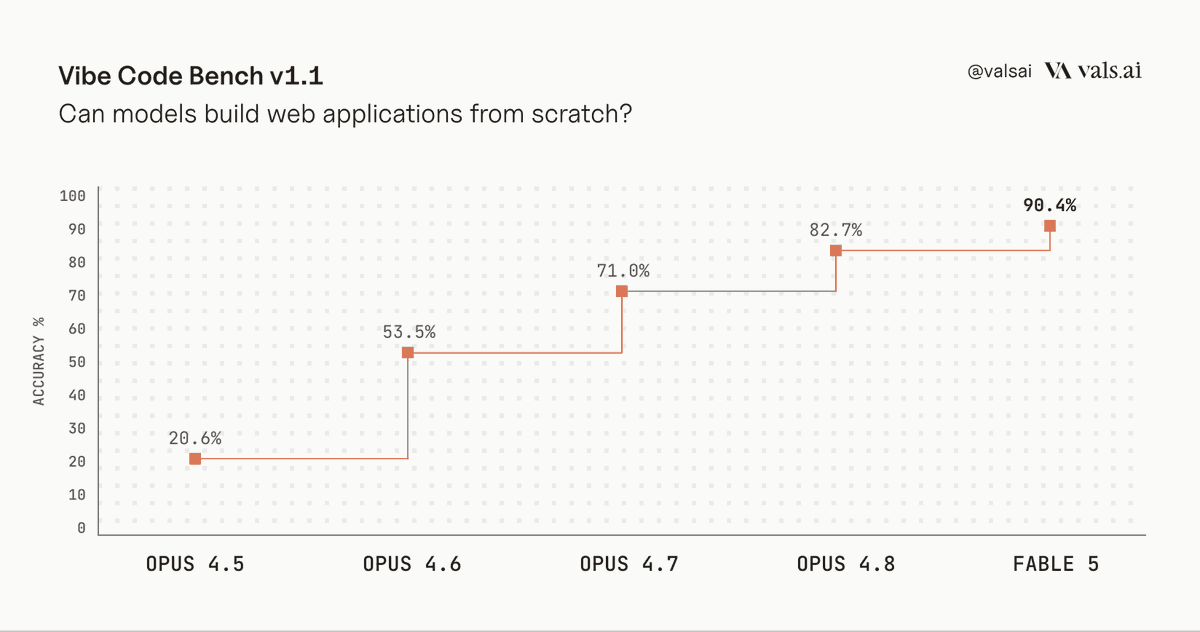
- Day-one evals put Fable 5 at or near the top for long-horizon coding and agentic work, with ArtificialAnlys ranking it first on GDPval-AA and ValsAI saying it hit 90.4% on Vibe Code Bench.
- The rollout immediately spread across Anthropic surfaces and partner products, with ClaudeCodeLog tying access to Claude Code 2.1.170 and Lovable plus opencode announcing support the same day.
The useful bits are buried in the docs. The official launch post confirms Fable and Mythos share one model, the prompting guide says adaptive thinking is always on, and the fallback billing guide explains how API users can avoid paying twice on routed requests. There is also a same-day Claude Code release for model access, plus a bug fix for missing transcripts in --resume sessions.
What shipped
Anthropic's core move was to split one model into two products. claudeai's launch post introduces Fable 5 as the public release, while claudeai's Mythos 5 post says Mythos 5 keeps fewer safeguards and stays restricted to cyber defenders and critical infrastructure providers.
The launch post adds three concrete details that matter more than the branding. Fable 5 and Mythos 5 share the same underlying model, both are priced at $10 input and $50 output per million tokens, and Anthropic says the public version was tuned for safe release rather than trained as a separate lower-capability system in its own right. Anthropic also used the post to claim a large enterprise reference point: the launch post says Stripe used Fable 5 to do a codebase-wide migration across a 50 million line Ruby codebase in one day, a job it said would otherwise have taken a team more than two months.
Benchmarks
The official benchmark card is broad rather than numeric, but the launch post makes three specific performance claims. Anthropic says Fable 5 leads its own tested set in software engineering, knowledge work, vision, and scientific research, says medium effort is enough to top FrontierCode, and says the model keeps widening its lead as tasks get longer and more complex.
Independent testers filled in the sharper numbers:
- ArtificialAnlys scored Fable 5 at 1932 on GDPval-AA and said the model fell back to Opus 4.8 on 2% of tasks during that run.
- ValsAI said Fable 5 reached 90.4% on Vibe Code Bench, up from a sub-20% ceiling for any model six months earlier.
- danshipper's vibe check said Every's internal Senior Engineer benchmark moved from 63 for Opus 4.8 to 91 for Fable 5, a 28 point jump.
- bridgemindai and bridgemindai's follow-up both called out CursorBench and Artificial Analysis as day-one confirmation that the model was leading coding-heavy public evals.
Opus fallback
The most unusual part of the release is not the price or the benchmark chart. It is the routing layer that swaps models when a request touches high-risk categories.
According to claudeai's safeguards thread, Fable 5 classifiers watch for offensive cybersecurity work, biology and chemistry topics, and distillation-related requests. When they trigger, the user is told the answer is coming from Opus 4.8 instead.
The API behavior is more specific than the tweet thread. Anthropic's fallback billing guide says a blocked request returns HTTP 200 with stop_reason: "refusal" plus stop_details.category, and recommends either server-side fallback or client-side handoff logic. The same guide says Anthropic changed billing so API customers avoid extra token costs in most fallback cases, but ClaudeDevs' setup thread says requests rerouted inside the product UI are shown and billed at Opus prices.
Prompting changes
Fable 5 shipped with a behavior shift as well as a capability jump. ClaudeDevs' setup thread says thinking is always on, responses can take longer, and Anthropic now recommends starting with high effort because even low and medium often beat earlier models at xhigh.
The official prompting guide is blunt about what breaks from Opus-era habits:
- Adaptive thinking is the only thinking mode.
- Thinking cannot be disabled.
- Thinking output is summarized only.
- Older prompts and skills may now be too prescriptive.
- Multi-agent setups are still supported, including delegation from Fable to smaller models inside Claude Managed Agents.
That lines up with Anthropic's own onboarding thread. ClaudeDevs suggests giving Fable a backlog item scoped at a week, letting it interview the user for the spec, and then leaving auto mode running overnight.
Vibe check
Early hands-on reports converged on the same pattern: Fable 5 is strongest when a task is large enough to justify latency, cost, and long autonomous runs.
Dan Shipper, CEO of Every, wrote that Fable cleared production bug backlogs, built a playable 3D experience, and produced a two-minute animated film in one shot, but he also said the model routinely burned 500,000 to 1 million tokens per task and felt mismatched for lighter collaborative writing. Boris Cherny, Claude Code lead at Anthropic, made the internal product case more tersely when bcherny called it "the best model I have used for coding" and listed fewer prompts, better tool use, longer sessions, and higher autonomy.
Other outside reactions landed in the same zone. deedydas highlighted codebase migration, 3D graphics, and a 10x optimization result on a proprietary evaluator, while raunakdoesdev focused on recall, saying the model could surface niche training-data details even with web search disabled.
Where it shows up
Fable 5 was not a slow surface-by-surface rollout. The model appeared across Anthropic products, coding agents, and downstream app builders within hours.
Day-one availability included:
- Claude app and API, per claudeai's availability post.
- Claude Code via version 2.1.170, per ClaudeCodeLog and the linked release notes.
- Browser Use Terminal, where browser_use demoed Fable spending $7.21 chasing a coupon code.
- Lovable, per Lovable.
- OpenCode, per opencode.
- Devin, where swyx said Mythos and Fable were available for 1.4x ACUs.
- The
@codeapp, where code posted that rollout had started.
Access window
Anthropic also treated launch day like a sampling event. testingcatalog reported that Fable 5 was included in usage plans until June 22 at 2x Opus usage, and later that day ClaudeDevs said Anthropic reset 5-hour and weekly rate limits for all users.
The practical activation checklist was short but easy to miss in the noise:
- In Claude Code, run
/model claude-fable-5, according to ClaudeDevs' access instructions. - Upgrade Claude Code to 2.1.170 for access, per ClaudeDevs' access instructions and ClaudeCodeLog.
- Desktop users needed the latest app version, per ClaudeDevs' access instructions.
- The 2.1.170 release also fixed a transcript persistence bug affecting VS Code integrated terminals and shells inheriting Claude Code environment variables, according to ClaudeCodeLog and the linked GitHub release.