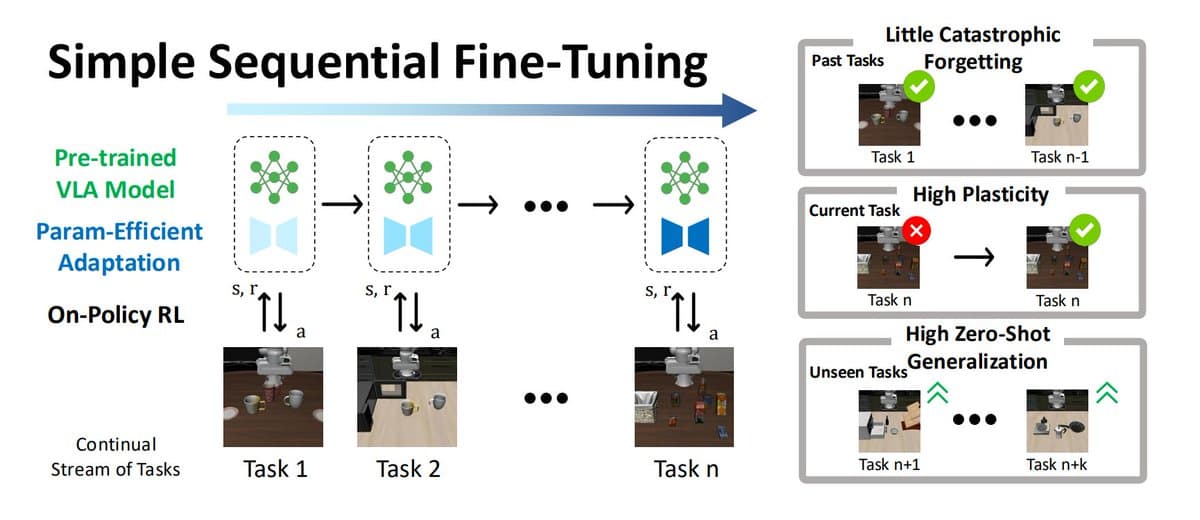
UT Austin compares Seq. FT + LoRA vs RL for VLA continual learning
UT Austin researchers report that simple sequential fine-tuning with LoRA and on-policy RL can retain prior skills while learning new VLA tasks. Try this baseline before reaching for more complex continual-learning methods.
TL;DR
- UT Austin researchers argue that a simple continual-learning baseline for vision-language-action models — sequential fine-tuning plus LoRA and on-policy RL — can retain prior skills, learn new tasks, and preserve zero-shot behavior, according to the main thread.
- The reported mechanism is a three-part stack: pretrained VLA models provide broad prior knowledge, LoRA constrains updates to a small subspace, and on-policy RL keeps policy updates gradual, as outlined across the method summary and the RL explanation.
- Their results claim strong plasticity and better zero-shot generalization, with multitask training still holding a small lead of about 5% unless Seq. FT is trained longer on weaker tasks, per the results post.
- The release includes both the paper and the code, making this a reproducible baseline rather than just a benchmark claim, as shown in the resource post.
What exactly did they test?
The core claim is that naive-looking sequential fine-tuning is not as brittle as the continual-learning literature often assumes. In the setup post, the recipe is simply “trains the model on one task,” then fine-tunes on the next, and keeps updating the same model as new tasks arrive; the thread opener says that with a large pretrained VLA, LoRA, and on-policy RL, this approach can “prevent catastrophic forgetting” while keeping “strong zero-shot abilities.”
The strongest implementation detail for engineers is that this is presented as a baseline that can rival heavier continual-learning machinery. According to the results post, the simple stack “even beats more complicated continual learning methods” in many cases, while multitask training still keeps a small edge of roughly 5% before extra training on weaker tasks closes the gap.
Why do LoRA and on-policy RL matter here?
The thread’s explanation is that each component limits destructive updates in a different way. The method summary says pretrained VLAs already carry strong general knowledge, LoRA “updates only small parts of the model,” and on-policy RL lets the model adapt while interacting with the environment instead of making abrupt offline shifts.
The more specific claim is that policy-gradient RL “reduces forgetting” because updates are based on actions from the current policy, so training stays near behaviors the model already performs, per the RL explanation. LoRA then narrows the update space: the LoRA post says it restricts changes to a low-rank subspace, with “rank ≈ 29 instead of ~200,” smaller overall update magnitude, and more evenly distributed changes. Another thread post adds the paper’s intuition that large pretrained models offer many nearly orthogonal “safe directions” for learning new tasks without overwriting old ones.
What can engineers reproduce from the release?
This is not just a social thread. The release post links both the arXiv paper and the GitHub repo, and the linked summary says the code covers continual RL for VLA models with benchmark baselines, PPO and GRPO implementations, and evaluation tooling.
For practitioners working on embodied agents, the useful takeaway is less “new algorithm” than “new default baseline.” The release positions Seq. FT plus LoRA plus on-policy RL as the thing to beat first, not the straw man, and the reported results suggest its main tradeoff is modestly trailing multitask training unless compute is spent longer on the weakest tasks.