Thinking Machines introduces interaction models with 200 ms full-duplex audio, video, and tool use
Thinking Machines previewed interaction models that process audio, video, and text in 200 ms micro-turns, letting the system listen, speak, and react at the same time. The demos matter because the interaction loop is trained into the model instead of stitched together from separate speech and tool layers.
TL;DR
- Thinking Machines previewed TML-Interaction-Small as a 276B MoE with 12B active parameters, and according to rohanpaul_ai's summary of the official post, the model processes audio, video, and text in 200 ms micro-turns instead of waiting for clean turn boundaries.
- In thinkymachines' demo thread and a second demo, the model keeps listening while speaking, interrupts when it thinks it should, and tracks cues like hesitation, yielding, and self-correction without a separate dialogue manager.
- The benchmark chart in testingcatalog's screenshot put TML-small at about 0.40 s latency, 77.8 FD-bench v1.5 interaction quality, and 43.4% on Audio MultiChallenge, which is the core claim behind Thinky's “fast without getting dumb” pitch.
- According to liliyu_lili's thread and rown's post, Thinky is also claiming “visual proactivity,” where the model responds to live visual changes like finger counting, posture, or pushup counting instead of waiting for a spoken prompt.
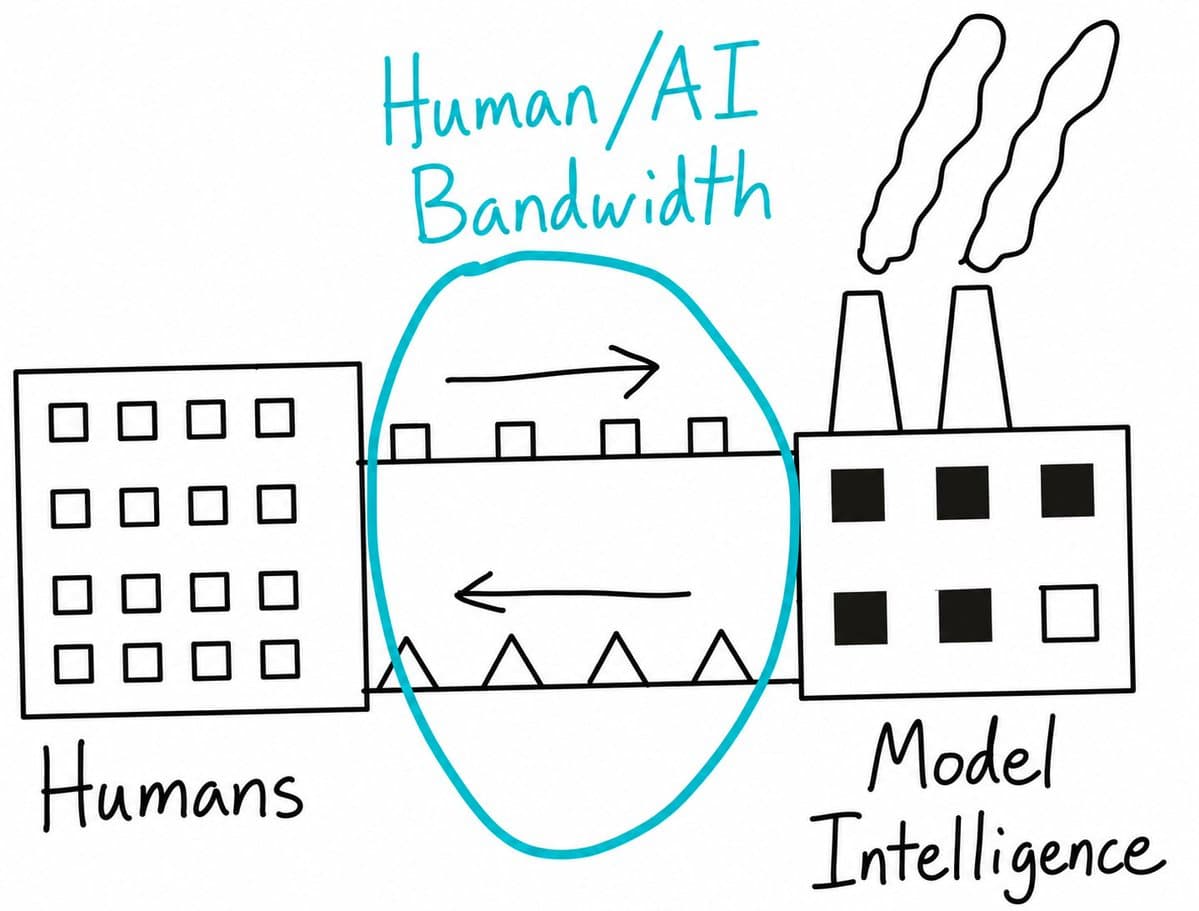
- The bigger framing came from cHHillee's bandwidth analogy and alex_kirillov's bitter-lesson post: Thinky is treating interactivity as part of the model itself, not as a harness wrapped around speech, vision, and tool components.
You can read the official post, jump straight to the technical report, and inspect the benchmark examples. The weirdly useful demos are all in thinkymachines' launch thread, while lmsysorg's note adds one stack detail the launch material barely foregrounded: Thinky upstreamed streaming sessions back into SGLang.
200 ms micro-turns
Thinky's core design choice is to treat interaction as a continuous stream. rohanpaul_ai's summary of the official post says the model slices audio, video, and text into 200 ms micro-turns, which lets it keep listening, watching, and acting while the exchange is still happening.
The architecture diagram captured in giffmana's screenshot shows what that means mechanically for a single 200 ms window:
- Text goes through tokenization and embeddings.
- Video frames go through 40x40 patches and an hMLP.
- Audio goes through dMel features into a bag of embeddings.
- A central transformer predicts both text and audio outputs for the same window.
That is a much tighter loop than the usual realtime stack, where STT, VAD, turn detection, tool calls, and TTS are all glued together outside the model.
Native interaction loop
Thinky's launch line was “models that handle interaction natively rather than through external scaffolding,” as testingcatalog's quote of the official announcement summarized. The company kept repeating the same point in different words because it is the whole bet.
The strongest evidence is in thinkymachines' Lilian demo, where the company says the model tracks when a speaker is thinking, yielding, self-correcting, or inviting a response, and that there is “no specific built dialogue management system.” johnschulman2 framed that as full-duplex multimodal interaction, while alex_kirillov argued that making interactivity integral to the model will outpace harness-based approaches.
Two concrete behaviors show up across the demos:
- Simultaneous speech, in the Alex parents demo and Nathan Lambert's reaction, where both sides talk at once.
- Background work during live conversation, in thinkymachines' multi-task demo, where the model searches while listening and responding.
Benchmarks
Thinky did not just ship vibes and demo clips. The benchmark chart shown in testingcatalog's screenshot and recapped by rohanpaul_ai's thread is the main quantitative evidence.
The topline numbers shown in the evidence pool:
- FD-bench v1 turn-taking latency: 0.40 s for TML-interaction-small.
- FD-bench v1.5 interaction quality: 77.8.
- Audio MultiChallenge APR: 43.4%.
- The chart places TML-small near GPT-2.0 xhigh on intelligence while materially ahead on responsiveness and interaction quality.
Thinky's framing is “combined performance in intelligence and responsiveness,” quoted in testingcatalog's launch screenshot. That matters because realtime systems usually trade one off against the other.
There is one caveat worth stating plainly. The strongest benchmark evidence here is still first-party presentation material from Thinky, reposted in testingcatalog's screenshot and kimmonismus' thread, not an external eval report.
Demos that actually looked different
The launch thread is full of toyish scenes, but a few mechanics are genuinely new-looking. thinkymachines' multi-task demo shows the model searching in the background while it keeps talking, the Lilian clip shows it reacting to conversational cues without hard turns, and another clip in the same thread shows it drawing when a visual explanation is easier.
The recurring demo patterns are easier to scan as a list:
- Overlap: the model speaks while the user is still talking, per thinkymachines' simultaneous speech demo.
- Background search: it looks things up mid-conversation, per thinkymachines' Long demo.
- Visual explanation: it draws diagrams instead of forcing everything through speech, per thinkymachines' drawing demo.
- Continuous time awareness: the company claims it tracks elapsed time in ongoing situations, per thinkymachines' trivia-night example.
- Speech nuance: it handles hesitations and mispronunciations in live speech, per thinkymachines' Mianna demo.
Some reaction posts captured the same thing more bluntly. NickADobos called the UX shift “small tweaks but big changes in feeling,” while emollick said the capability looked neat but the demo set underplayed high-value use cases.
Visual proactivity
Video is where Thinky is making the sharpest claim. In liliyu_lili's thread, the team defines “visual proactivity” as a model responding when something happens visually, with examples like slouch detection, pushup counting, or telling you when a person stops doing something.
liliyu_lili's live finger-counting test is a good litmus test because it requires continuous watching, change tracking, and timing the response correctly. rown went further and called Thinky's system the first general video-plus-speech model that is visually proactive.
That claim is still an attributed one, not an independently established category win. But it is the cleanest statement of what Thinky thinks turns continuous video from “multimodal input” into an interaction primitive.
Training log and stack
The most revealing stray details came from the people building it. lilianweng said the team went through 12 versions, plus many subversions, and filled 137 pages of training run logs before landing this preview.
Two extra implementation details surfaced outside the main launch copy:
- lmsysorg said SGLang was part of the stack, and that Thinky upstreamed streaming sessions back to the project.
- alex_kirillov said building interaction models “from scratch” made many things easier than working in a turn-based world.
Those details make the preview look less like a voice skin on top of an existing model, and more like a training and serving effort built around concurrency from the start.