Cursor ships Composer 2.5 with 2x included usage and a 10x-compute follow-on model
Cursor released Composer 2.5 in its editor and says it is stronger on long-running tasks, with included usage doubled for a week. Early comparisons place it near Opus 4.7-class coding, and Cursor says a much larger model is still training with 10x more compute.
TL;DR
- Cursor says Cursor's launch post ships Composer 2.5 as its strongest coding model yet, with better long-running task performance, better instruction following, and 2x included usage for the next week.
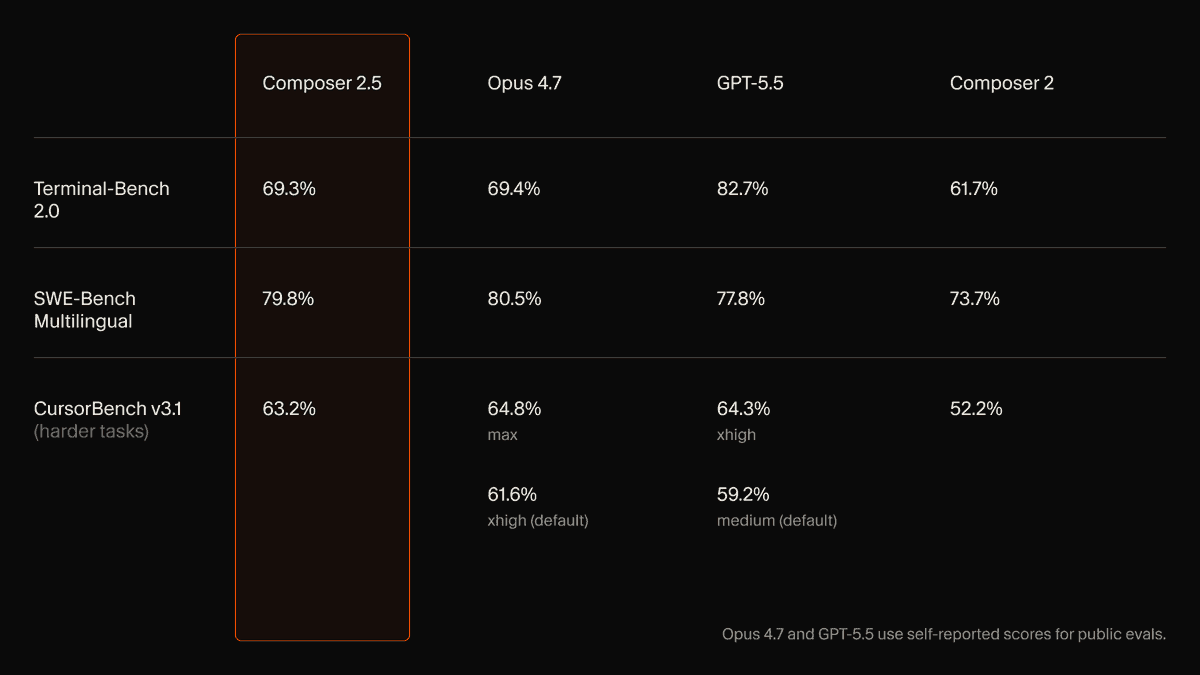
- The launch chart in Cursor's benchmark table puts Composer 2.5 near Opus 4.7 on Terminal-Bench 2.0 and SWE-Bench Multilingual, while beating Composer 2 by 11.0 points, 6.1 points, and 11.0 points respectively across the three listed evals.
- The cost chart from Cursor's efficiency plot places Composer 2.5 near a 63% CursorBench 3.1 score at about $0.50 per task, while Opus 4.7 and GPT-5.5 hit similar quality bands at materially higher cost settings.
- According to the compute breakdown retweet and testingcatalog's excerpt of Cursor's post, Composer 2.5 still uses Moonshot's Kimi K2.5 as its base, but Cursor says 85% of the compute behind the model came from its own additional training and RL.
- Cursor also used the release to say, in testingcatalog's quote from the post and ericzakariasson's screenshot, that a much larger follow-on model is training from scratch with SpaceXAI using 10x more total compute on Colossus 2.
You can scan Cursor's own charts, see the 85% training-compute breakdown, and compare that with an internal dogfood note saying most of the company had chats silently redirected to Composer 2.5 for two days. The weird part is that Cursor spent the same launch announcing the next model too, with a quoted line from the post about 10x more compute and AILeaksAndNews' repost tying that effort to xAI's training pipeline.
Benchmarks
Cursor's benchmark card is unusually direct. It puts Composer 2.5 almost level with Opus 4.7 on two public coding evals, then shows a much larger jump against Composer 2 on CursorBench v3.1.
The three numbers Cursor surfaced:
- Terminal-Bench 2.0: 61.7% for Composer 2, 69.3% for Composer 2.5, +7.6 points
- SWE-Bench Multilingual: 73.7% for Composer 2, 79.8% for Composer 2.5, +6.1 points
- CursorBench v3.1: 52.2% for Composer 2, 63.2% for Composer 2.5, +11.0 points
On the same chart, Composer 2.5 lands 0.1 points behind Opus 4.7 on Terminal-Bench and 0.7 points behind on SWE-Bench Multilingual, according to bridgemindai's repost of the table. GPT-5.5 stays ahead on Terminal-Bench at 82.7%, but trails Composer 2.5 on SWE-Bench Multilingual, as shown in Wes Roth's screenshot of the chart.
The footnote matters. Cursor's chart says the Opus 4.7 and GPT-5.5 public eval numbers are self-reported.
Cost curve
The louder claim in the launch is not that Composer 2.5 is best-in-class. It is that Cursor pushed it onto the coding-model Pareto frontier at a much lower per-task cost.
According to Cursor's efficiency plot, Composer 2.5 sits around a 63% CursorBench 3.1 score at roughly $0.50 average cost per task. On that same plot, Opus 4.7's xhigh default sits around 61.6% at roughly $8, while GPT-5.5's medium default sits around 59.2% at roughly $2.
That is where the "up to 10x more efficient" line from Cursor's launch thread comes from. Community reactions from Muennighoff's Pareto-frontier post, scaling01's reply, and kimmonismus' follow-up all focused on the same chart rather than the raw benchmark table.
One early caveat came from bridgemindai's speed test post, which called the model "lightning fast" but also said it looked "benchmaxed." The launch evidence does not resolve that claim, but it does explain why the chart grabbed people: Cursor is showing one fixed Composer 2.5 point against multiple effort-level sweeps for Opus 4.7 and GPT-5.5.
Kimi base model
Cursor did not train Composer 2.5 from scratch. The company and several reposts say it is built on the same open-source base as Composer 2, Moonshot's Kimi K2.5.
The more interesting number is the compute split. The image in the compute breakdown retweet says 85% of the compute for Composer 2.5 came from "Composer training and RL," with 7.5% attributed to Kimi K2 and 7.5% to Kimi K2.5.
That framing also shows up in commentary around the release. Maxime Rivest's reaction treated the model as evidence that an open-weights base plus training data and post-training can still move a coding model onto the frontier, while Clement Delangue's response read the launch as another sign that major AI application companies want their own training stack.
Cursor employees pushed the same direction in plainer language. Jediah Katz's post called it "many small steps of training," and Andrew Zhai's note said the model had become his daily driver.
Internal rollout
The hands-on reports are short, but they all point at the same thing: Cursor appears to have tested Composer 2.5 internally as a near-drop-in replacement before the public release.
According to Dan Perks' internal test post, most of the company had chats redirected to Composer 2.5 for about two days the prior week, and he says he did not notice. sjwhitmore's test report made the same comparison more explicitly, saying he forgot he was not on GPT-5.5 for a while.
The non-benchmark feedback is mostly about interaction quality and speed:
- stephenhaney's early use note called it smart and very fast.
- bridgemindai's post said iteration speed was the standout.
- A retweet captured in sjwhitmore's repost says the model sends more useful updates while it works and acts like a better collaborator.
That fits the product-language change in Wes Roth's summary of the launch, which adds two claims not shown on the benchmark card: improved communication style and better effort calibration.
Follow-on model
Composer 2.5 may end up being remembered as the warm-up. Cursor used the same launch to preview a larger model training from scratch with SpaceXAI, backed by 10x more total compute.
The quoted line, repeated in testingcatalog's excerpt and kevinkern's summary, says the next model is being trained "with Colossus 2's million H100-equivalents" and should be a major leap in capability. Together AI's partnership post confirms at least one infrastructure partner was part of the Composer 2.5 launch itself.
Some of the speculation around that next system is already getting ahead of the evidence. AILeaksAndNews' repost links the effort to xAI's broader training pipeline, and eliebakouch's compute estimate tries to backsolve possible model sizes and token counts from the 85% compute chart. Those estimates are useful as estimates only.
The concrete new fact from the launch is simpler: Cursor is now talking like a lab with an application, not just an editor with model routing.