Developers report Codex beats Claude Code on DeepSWE, token burn, and multi-hour /goal sessions
Independent users compared GPT-5.5/Codex with Opus 4.8/Claude Code using DeepSWE cost charts, GBA Eval runs, and long coding sessions. The split matters because engineers choosing a daily coding stack now have external quality-versus-cost evidence instead of only vendor launch claims.
TL;DR
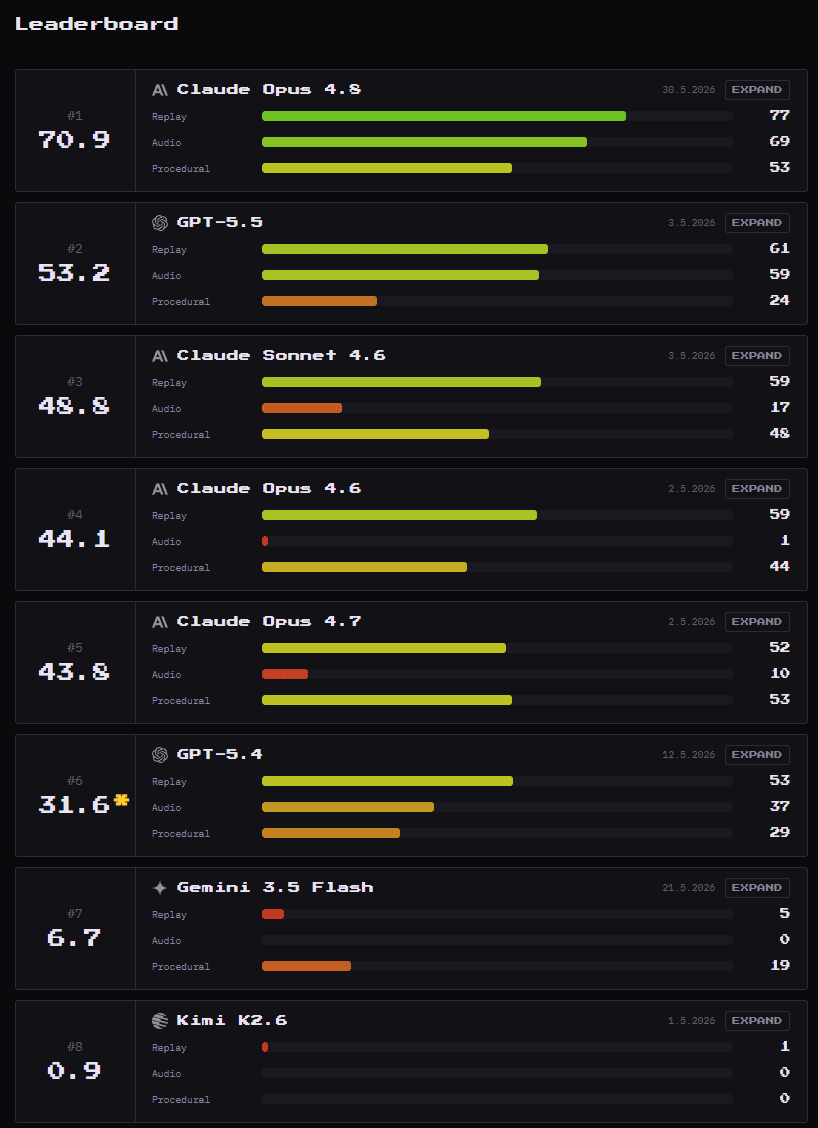
- On DeepSWE, GPT-5.5 xhigh posted 70% pass@1 at $6.61 per task, 21 minutes, and 47K output tokens, while reach_vb's leaderboard summary and the official DeepSWE leaderboard put Claude Opus 4.8 max at 58%, $12.58, 43 minutes, and 136K output tokens.
- Users comparing daily coding stacks kept landing on the same complaint: according to haider1, GPT-5.5 in Codex can stay on /goal for hours, while daniel_mac8's side-by-side test said Claude Code hit rate limits mid-task after using far more tokens.
- Codex also quietly picked up persistent goal storage and thread lifecycle APIs, and koltregaskes' session-control post matched late May OpenAI release notes and the app-server README, which document stored goals plus thread create, list, and archive operations.
- Anthropic still had one clean external win: scaling01's GBA Eval post linked to GBA Eval, where Opus 4.8 topped GPT-5.5 on a from-scratch Game Boy Advance emulator task.
- The pricing story split by surface. While thsottiaux reset Codex limits across paid ChatGPT plans, bridgemindai's usage post and bridgemindai's three-plan post described developers buying multiple Claude Max plans to brute-force Claude Code throughput.
You can inspect the full DeepSWE charts, read Datacurve's benchmark rationale, browse OpenAI's recent Codex release notes, and check Anthropic's own ultracode docs. The weirdest split is that Codex keeps winning the long-horizon cost and stamina conversation, while GBA Eval gave Opus 4.8 a visible agent benchmark win and Anthropic's settings docs show how much orchestration logic is now bundled into Claude Code itself.
DeepSWE
Datacurve built DeepSWE around 113 contamination-free tasks across 91 repos and 5 languages, with hand-written verifiers and substantially larger solution size than SWE-Bench Pro, according to the official benchmark post.
The leaderboard gap was not subtle:
- GPT-5.5 xhigh: 70% pass@1, $6.61, 21m, 47K output tokens, per DeepSWE.
- Claude Opus 4.8 max: 58% pass@1, $12.58, 43m, 136K output tokens, per DeepSWE.
- Like-for-like against Opus 4.7, koltregaskes' comparison said 4.8 improved score at every tier, but still got slower and more output-hungry.
That same split carried into practitioner reaction. koltregaskes' earlier thread called 4.8 a big jump from 4.7 but still about twice the cost and twice the latency of GPT-5.5 xhigh, while kimmonismus landed on the same basic read after the first DeepSWE charts.
Session orchestration
The most underreported Codex change was not the model score, it was session control. koltregaskes described Codex as a multi-context orchestrator that can create, rename, edit, delete, and archive its own sessions.
OpenAI's own docs support most of that framing. The late May Codex release notes say goals are now enabled by default, backed by dedicated storage, and tracked across active turns. The app-server README documents thread/start, thread/list, and archive operations, plus thread/goal/set and thread/goal/clear for persisted goals.
That helps explain why long-running /goal sessions kept showing up in the evidence:
- steipete said GPT-5.5 plus /goal, autoreview, and crabbox pushed prompts from 30 to 60 minutes into 4 to 10 hour tasks.
- vincent_koc posted a Codex /goal run still going after five days.
- danshipper shared a 56 hour longest task and 38 billion tokens.
- mattrickard reported 86.5 billion cumulative tokens across 3,650 Codex sessions, then clarified that count in mattrickard's follow-up.
Token burn
Claude Opus 4.8's hardest-to-miss regression was token appetite. The official DeepSWE chart already showed a 136K output-token average for Opus 4.8 max versus 47K for GPT-5.5 xhigh, and users said the difference was obvious in product.
Daniel Mac's side-by-side test was unusually concrete:
- Codex dynamic workflows: 175K tokens in 15 minutes, with 99% of weekly ChatGPT Pro usage left, per daniel_mac8.
- Claude Code dynamic workflows: 700K tokens in 40 minutes, with 86% of a Team plan left, also per daniel_mac8.
- DeepSWE max-tier output tokens: 47K for GPT-5.5 xhigh versus 136K for Opus 4.8 max, according to reach_vb's token-efficiency post and the official DeepSWE leaderboard.
Other users described the same thing in less polite terms. haider1 said Opus 4.8 exhausted their tokens about 4.8 times faster than 4.7, and dexhorthy said the brief shift back from Codex to Claude did not last.
Dynamic workflows
Anthropic's counterpunch was orchestration breadth. The official Claude Code model configuration docs say ultracode is not a model effort level, it is a Claude Code setting that sends xhigh and automatically orchestrates dynamic workflows. Anthropic's settings docs add switches for disabling workflows entirely or turning on ultracode per session.
In practice, that looked like developers using Claude Code as a background swarm runner:
- steipete said Codex was creating a QA scenario for every commit, driving webVNC and browser-use tools, and opening PRs with fixes.
- daniel_mac8's workflow instructions framed Opus 4.8 plus
/ultracodeas the switch that unlocks Claude Code's new Dynamic Workflows. - sidbid said the workflows were expensive enough that they asked Claude to shrink them just to inspect token use.
- bridgemindai's 105-agent review said 105 UltraCode agents still shipped a bug to production and failed eight repair attempts.
The docs explain part of the bill. Anthropic says ultracode adds workflow orchestration on top of xhigh reasoning, and community explainers around the feature describe hard caps of 16 concurrent agents and 1,000 total agent invocations per run, which matches the shape of the token complaints even when users still preferred Claude's coding quality.
GBA Eval
DeepSWE was the anti-Anthropic chart. GBA Eval was the pro-Anthropic one.
The official GBA Eval site says frontier coding agents are asked to build a Game Boy Advance emulator in WebAssembly from scratch, then graded against Mesen2. scaling01 said Opus 4.8 was the new state of the art there, and the benchmark link points back to the public leaderboard.
That lines up with a broader pattern in the evidence: benchmark arguments depended heavily on what counted as success. DeepSWE and user reports favored long-horizon cost, speed, and role retention; Victor Taelin's reposted take argued that some of Opus' best traits, like communication clarity and restraint, were mostly invisible to benchmark tables.
Limits and arbitrage
The usage model is turning into part of the product. On the OpenAI side, sama's repost of thsottiaux said five million users would agree with a Codex limit reset, and thsottiaux's own post confirmed hourly and weekly limits were restored across paid ChatGPT subscriptions. reach_vb said the reset applied across plans and surfaces.
On the Anthropic side, power users were solving the same problem with credit cards instead of resets:
- bridgemindai said they bought three $200 Claude Max 20x plans and ran them in parallel.
- bridgemindai's follow-up claimed 1.63 billion tokens in two days on Max plans, which they framed as about $1,500 of API-equivalent usage for a flat fee.
- bridgemindai's comparison post still preferred Claude Code overall, despite also paying for ChatGPT Pro.
That last split is probably the cleanest summary of this moment: external charts and many heavy users now favor Codex for stamina, cost, and session durability, but some of the people spending the most money on coding agents still keep extra Claude Max seats around because they think Opus 4.8 writes better code when the meter is not the bottleneck.