GLM-5.2 benchmarks at 97.6% tool-calling and 2,626 tok/s on MI355X
Kilo, Composio, Together, and Wafer posted GLM-5.2 measurements including 40/41 tool tasks, 7/10 code review, and 2,626 tok/s on MI355X. Try it for lower-cost coding and tool use, but validate cross-file reasoning and latency on your workload.
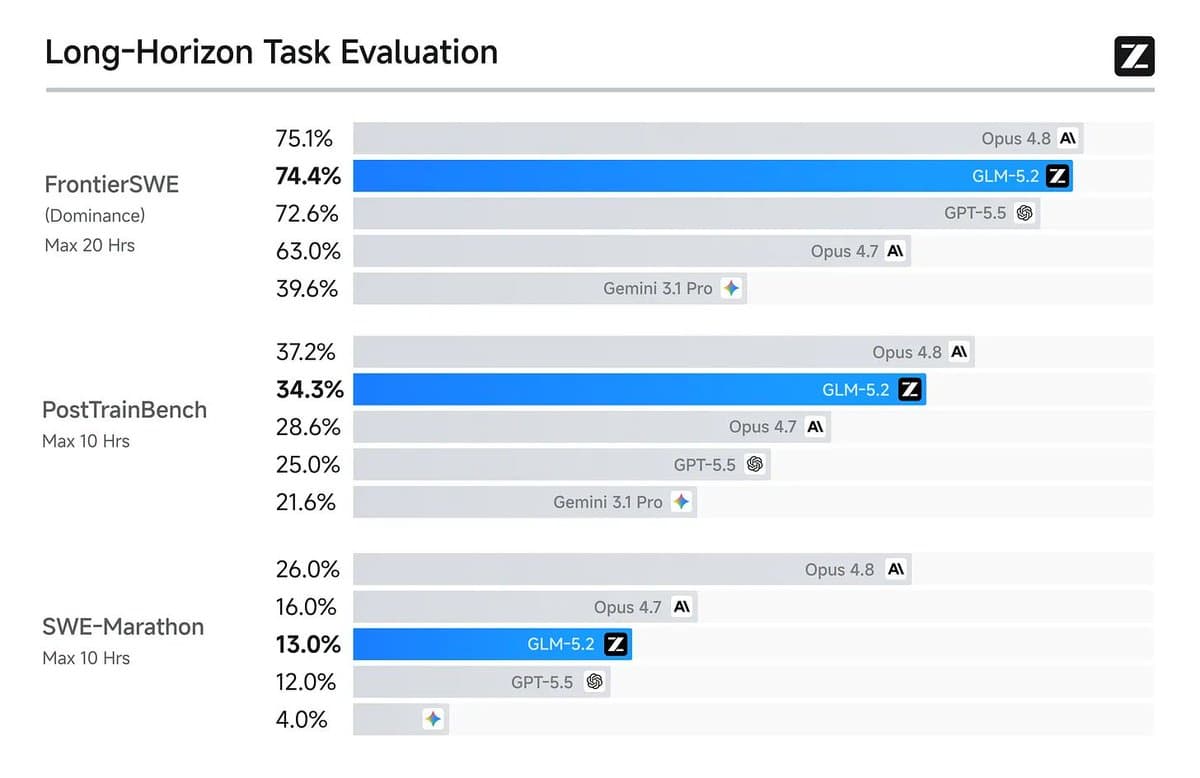
TL;DR
- composio's 41-task run put GLM-5.2 at 40/41 agentic tool-calling tasks across GitHub, Gmail, PostHog, Notion, and other production APIs, ahead of Opus 4.8 and GPT-5.5 in that harness.
- kilocode's hard-codebase result found GLM-5.2's best code-review run hit 7/10 bugs, one behind Opus 4.8 and two behind GPT-5.5, with high run-to-run variance.
- wafer_ai's MI355X post claimed 2,626 tok/s/node and 213 tok/s single-stream serving for GLM-5.2 on AMD MI355X at more than 2x lower cost than Blackwell.
- composio's cost note said GLM-5.2 averaged about 100 seconds per task versus 53 seconds for Opus, burned the most tokens, and still came out cheaper per task at GLM pricing.
- _akhaliq's usage note said they use GLM-5.2 in Claude Code via hf claude almost daily and have moved completely to open models.
Z.ai's launch post says the model pairs a 1M-token context with IndexShare and a better speculative-decoding layer. The migration guide exposes the knobs engineers actually touch: 128K max output, tool_stream=true, thinking, and reasoning_effort. Kilo published the full code-review benchmark, Wafer published the MI355X serving write-up, and OpenRouter's model page shows a 1M-context hosted route with $0.91/$2.86 per 1M token pricing.
GLM-5.2 baseline
Z.ai describes GLM-5.2 as a long-horizon model with a stable 1M-token context, open MIT-licensed weights, and multiple thinking-effort levels in its official announcement and Hugging Face model card. The engineering hook is not just context length.
- IndexShare reuses the same indexer across every four sparse-attention layers, which Z.ai says cuts per-token FLOPs by 2.9x at 1M context.
- The MTP layer was updated for speculative decoding, with Z.ai claiming up to 20% longer acceptance length.
- The migration guide lists 1M maximum context, 128K maximum output, streaming tool-call arguments via
tool_stream=true, andreasoning_effortcontrols. - OpenRouter lists supported reasoning efforts as
highandxhigh, withxhighmapping to max reasoning.
That spec sheet matches the benchmark pattern: strong long agent loops, visible latency, and recurring sensitivity to the harness around the model.
Tool-calling: 40 of 41
composio tested GLM-5.2 on 41 chained tool-calling tasks across GitHub, Gmail, PostHog, Notion, and other production APIs. composio's earlier post reported final scores of 40/41 for GLM-5.2 and 39/41 for both Opus 4.8 and GPT-5.5.
The benchmark was less about one-shot function calling than recovery and state tracking:
- composio's LaunchDarkly task said GLM-5.2 took 37 tool calls, hit four rejected typed patch calls, recovered, and created the approval request.
- composio's Gmail task said the model followed 19 pages of history API pagination with
max_results=2, found eight matching messages, and labeled only those. - composio's PagerDuty task said the model escalated exactly one qualifying Zendesk ticket out of three and left the others untouched.
- composio's failure case said GLM-5.2 stopped when GitHub's API reported the first 18 code-search results as complete; GPT-5.5 failed the same way, while Opus 4.8 kept digging.
The best detail is the miss: GLM-5.2 trusted a tool response that the harness expected it to challenge.
Code review: prompt framing beat reasoning depth
Kilo turned daily-driver variance into a controlled TypeScript backend test. kilocode's simple-codebase result said GLM-5.2 caught every serious security bug in every run, found 13 to 15 of 16 planted issues, and barely moved when the prompt changed.
On the harder codebase, the prompt mattered more than extra thinking. kilocode's hard-codebase finding said a strict "approve this production PR" framing scored worse because it collapsed into a security checklist.
Kilo's result split cleanly:
- Simple backend: 13 to 15 of 16 issues, steady across prompts, all serious security bugs caught.
- Harder backend: coverage dropped, prompt wording dominated, reasoning depth did not close the gap.
- Best hard run: kilocode's comparison put GLM-5.2 at 7/10, one behind Opus 4.8 and two behind GPT-5.5.
Cross-route rules
kilocode said GLM-5.2 reliably caught local bugs visible inside one function, then missed product rules spread across routes. The examples were archived tasks leaking into search, exports, and overdue lists.
That maps to a common failure shape in code-review agents: a model can read a handler correctly while failing to hold the product invariant across every surface that reuses the entity.
MI355X serving path
Wafer's write-up says its GLM-5.2 deployment on AMD MI355X hit 2,626 tok/s/node on a 20K input, 1K output workload with a 60% cache-hit rate at 2.4 RPS and a defined TTFT knee of at most 5 seconds. The same post says this was about 80% of measured B200 throughput at more than 2x lower cost.
The tuning path is concrete:
- MXFP4 quantization with AMD Quark.
sglangas the serving stack.- Speculative decoding fixes in the ROCm path.
- Manual MoE kernel tuning after an fp4 MoE fallback slowed prefill.
- A separate single-stream result of 213 tok/s on 10K input and 1.5K output.
wafer_ai's Vercel Gateway screenshot first claimed 287 tok/s on live AI Gateway traffic; wafer_ai's correction updated the number to 301 tok/s for GLM-5.2 Fast.
Workload economics
The cost story is workload-specific, not a flat price-table win. composio said GLM-5.2 was slower than Opus in its agent benchmark, averaged around 100 seconds per task versus 53 seconds, and burned the most tokens of the three models.
Three independent claims put numbers on the trade:
- composio's cost note still found GLM-5.2 cheaper per completed task than Opus 4.8 and GPT-5.5 at GLM pricing.
- togethercompute's DeepSWE comparison said GLM-5.2 delivered roughly 80% of Sonnet 5's software-engineering capability at roughly 20% of the price.
- baseten's Braintrust note said GLM-5.2 was 4.3x cheaper than Opus 4.8 on long-context retrieval with a 3.5% quality tradeoff.
Claude Code routing
The hands-on routing signal came from coding-agent users, not only benchmark posts. _akhaliq said they use GLM-5.2 in Claude Code via hf claude almost daily and have moved completely to open models.
Z.ai's coding-agent switch guide says the GLM Coding Plan now supports GLM-5.2 for Max, Pro, and Lite users, including Claude Code through an Anthropic-compatible endpoint. The same guide maps Claude Code's model slots to glm-5.2[1m] and sets CLAUDE_CODE_AUTO_COMPACT_WINDOW to 1000000.
EMostaque made the harness point explicitly, saying GLM-5.2 could reach Fable-level performance with the right harness and naming a "zenith harness" test in progress.