xAI releases Grok 4.20 Beta API with 2M context and $2 input pricing
xAI released Grok 4.20 Beta in the API with reasoning, non-reasoning, and multi-agent variants, a 2M-token window, and lower pricing than Grok 4. Test it for long-context and speed-sensitive workloads, but compare coding performance against top rivals on your own evals.
TL;DR
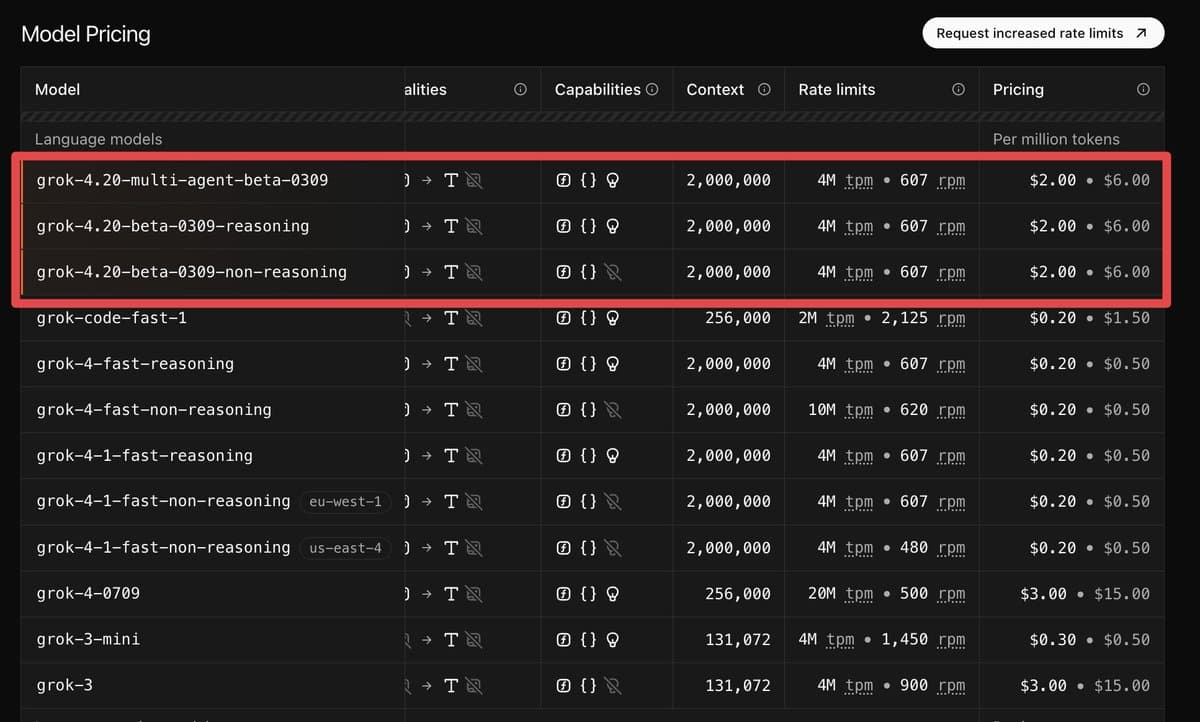
- xAI has released Grok 4.20 Beta in its API with three variants — reasoning, non-reasoning, and multi-agent — and the launch SKU list shows a 2,000,000-token context window at $2 per 1M input tokens and $6 per 1M output tokens API pricing.
- Distribution widened quickly: OpenRouter listed both Grok 4.20 Beta and the multi-agent variant on launch day, with OpenRouter's model listing and OpenRouter post also surfacing web-search pricing and the API's reasoning toggle.
- Third-party evals paint a split picture: Artificial Analysis says Grok 4.20 improved intelligence by +6 points over Grok 4, leads its non-hallucination metric at 78%, and tops IFBench at 82.9% while serving at roughly 265-267 tokens/sec AA breakdown AA highlights.
- Coding performance is better but not frontier-leading in single-model tests: Vals places the reasoning snapshot at #13 overall with low cost and latency Vals index, while Artificial Analysis' coding index has it at 42, behind GPT-5.4 at 57 and Claude Opus 4.6 at 48 coding index.
What shipped in the API
xAI's launch adds three API variants: grok-4.20-multi-agent-beta-0309, grok-4.20-beta-0309-reasoning, and grok-4.20-beta-0309-non-reasoning. The launch table in the API pricing post shows all three at 2M context with the same $2/$6 per-million token price, and the attached screenshot also lists 4M TPM and 607 RPM rate limits.
OpenRouter exposed the release almost immediately, which matters for teams already routing across providers. The OpenRouter listing shows both the base and multi-agent variants, and a follow-up post says the base model includes "agentic tool calling capabilities," a built-in reasoning toggle, and $5 per 1K web searches. Artificial Analysis adds the clearest before-and-after comparison: according to its model breakdown, Grok 4.20 moves from Grok 4's 256K context to 2M and cuts API pricing from $3/$15 to $2/$6.
Where it looks strong
The strongest early signal is reliability under uncertainty. Artificial Analysis says in its highlights thread that Grok 4.20 hallucinates only 22% of the time when it should refuse, calling that "the lowest hallucination rate of any model we have tested." Its fuller writeup in the AA breakdown reports a 78% AA-Omniscience non-hallucination score, the best result in that benchmark so far.
The same source says Grok 4.20 also leads IFBench at 82.9%, a +29.2 point jump over Grok 4, and runs at about 265-267 output tokens per second on xAI's API AA highlights AA breakdown. That combination of long context, lower price, and high throughput is the practical engineering story here. OpenRouter screenshots cited in the throughput post even show the multi-agent variant reaching 1,122 tokens per second through xAI on one routed path, though that figure is provider-path-specific rather than a universal model speed guarantee.
Where it still trails frontier coding models
The coding story is less clear-cut. Vals says in its benchmark post that the Grok 4.20 Beta reasoning snapshot lands at #13 overall, but it also "shines on the SWE Bench split" at #4 with 72.55% and improves Terminal Bench 2 by 10 percentage points versus earlier Grok models. That suggests meaningful progress, especially for long-context and repo-style tasks, without breaking into the very top tier overall.
Artificial Analysis is more cautious on agentic and coding-adjacent work. Its full breakdown says Grok 4.20 scores 42 on the Artificial Analysis Coding Index and 1,062 on GDPval-AA, which it describes as "well behind frontier peers" on general agent performance. BridgeBench results from a benchmark post are more favorable for the new multi-agent mode, with a 4-agent setup taking #1 at 96.1 overall and 100% completion, while the single-model Grok 4.20 Beta sits lower on the same leaderboard. For engineers, that makes the release look strongest where long context, speed, instruction following, and low hallucination matter most, with coding quality still needing task-specific evals against GPT-5.4, Claude, and Gemini.