Moonshot releases Kimi K2.7 Code HighSpeed at 180 tok/s with 2x API pricing
Moonshot rolled out HighSpeed for Kimi K2.7 Code, claiming about 180 tok/s on coding tasks, up to 260 tok/s on shorter contexts, and roughly 6x speedups. Watch the tight capacity limits and mixed benchmark results, and budget for the 2x pricing if you want the faster mode.
TL;DR
- Kimi_Moonshot's launch post says Kimi K2.7 Code HighSpeed delivers around 180 tok/s on median coding tasks, up to 260 tok/s on shorter contexts, and as much as 6x the speed of the standard mode.
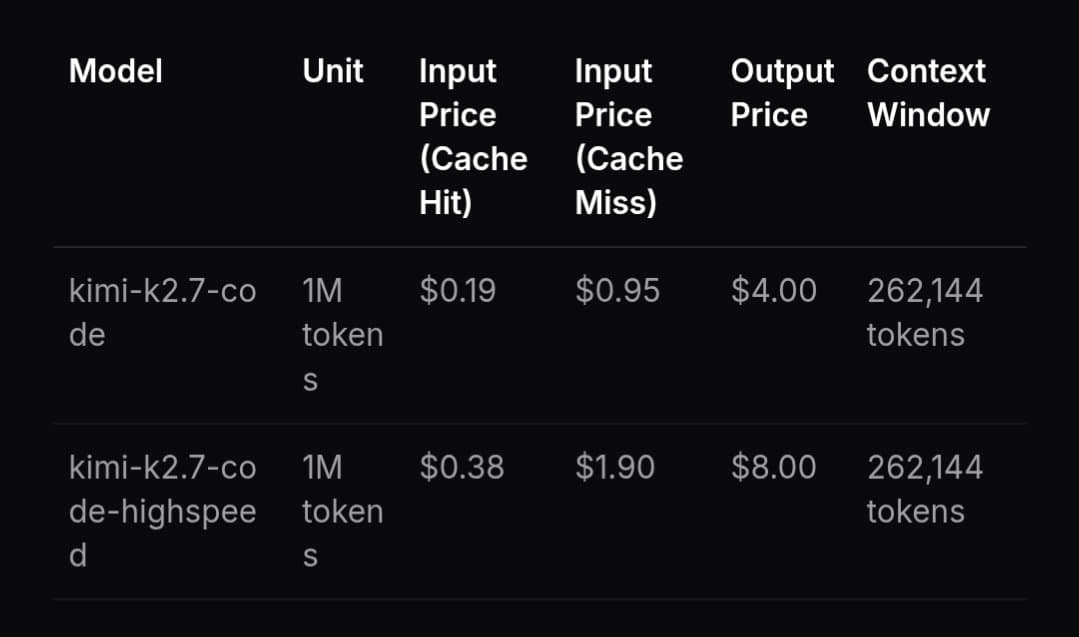
- Pricing did move: cedric_chee's reply says HighSpeed costs 2x normal API pricing, while cedric_chee's docs note says the faster tier is the same underlying model.
- Access is not broad yet. According to Kimi_Moonshot's rollout note, HighSpeed is limited to Kimi Code Beta members, API developers, and Business users, and ai_for_success's reply shows some beta requests were still pending.
- The model launch looked strong on coding evals, with ValsAI's benchmark thread putting K2.7 Code at 78.2% on SWE-bench and 67% on Terminal-Bench 2.1, but early hands-on reports from bridgemindai's limit complaint and bridgemindai's review were much rougher.
- Moonshot's speed push landed alongside unusually heavy local and partner distribution: UnslothAI's local-run post cut the model to 325GB in Dynamic 2-bit, while AskVenice's integration post, togethercompute's availability thread, and Teknium's Hermes Agent post show K2.7 surfacing across multiple stacks fast.
You can browse Kimi Code, inspect the API platform page, and the launch immediately spilled into other surfaces: Unsloth's local guide, the Vals benchmark page, and the Code Arena frontend leaderboard all added details the announcement itself did not.
HighSpeed mode
Moonshot framed HighSpeed as a speed tier for K2.7 Code, not a new model. Kimi_Moonshot gave three concrete numbers: around 180 tok/s on coding tasks with median-length inputs, up to 260 tok/s on shorter-context work, and up to 6x faster than the standard version.
That speed claim sits on top of a model Moonshot had already positioned as a coding-focused follow-up to K2.6. According to WesRoth's K2.7 launch summary, K2.7 Code improved 21.8% on Kimi Code Bench v2, 11% on Program Bench, and 31.5% on MLS Bench Lite versus K2.6, while using 30% fewer reasoning tokens.
Access and pricing
The catch is simple: faster costs more, and access is still gated. cedric_chee's reply says HighSpeed is priced at 2x the normal API rate.
That reply also matters because it answers the obvious product question. cedric_chee's docs note says HighSpeed is the same model according to Moonshot's docs, which makes this look like a premium throughput tier rather than a separate checkpoint.
Rollout is also narrow. Kimi_Moonshot's launch post limited access to Beta Program members, API developers, and Business users because of capacity, and ai_for_success's pending request suggests that even interested testers were waiting for approval.
Benchmarks and early usage
Independent benchmark posts were strong enough to explain the excitement. In ValsAI's thread, K2.7 Code ranked as the #1 open weight model on SWE-bench at 78.2% and on Terminal-Bench 2.1 at 67%, ahead of the next open model at 60.67%.
Other public evals filled in a more specific shape:
- ValsAI's follow-up put it at 47.21% on Vibe Code Bench, up from 37.89% for K2.6.
- the same ValsAI post scored it at 49.44% raw pass rate on ProgramBench.
- arena's leaderboard post ranked Kimi-K2.7-Code as the #3 open model in Code Arena: Frontend and #19 overall.
- ValsAI's config note says those Vals runs used the official Kimi API at temperature 1.0 and top_p 0.95, with a 256K context window and 32K max output tokens.
The hands-on reaction was less tidy. bridgemindai's limit complaint said a paid plan hit rate limits after about 30 minutes, while bridgemindai's review reported failed app-generation attempts and called the 262K context window underwhelming. bridgemindai's benchmark comparison went further, claiming GLM 5.2 beat Kimi on BridgeBench reasoning and that K2.7 regressed from K2.6 on that benchmark.
More positive early usage existed, but mostly as showcase clips rather than systematic testing. chetaslua's demo post said K2.7 Fast one-shotted a project in under a minute, and chetaslua's comparison reply called HighSpeed comparable to Opus 4.6.
Local quantization and distribution
The other notable reveal is how quickly K2.7 spread beyond Moonshot's own UI. togethercompute's availability thread put it on Together AI, AskVenice's post made it available on Venice with privacy-focused framing, and Teknium's Hermes Agent post added it to Hermes Agent without requiring a client update.
The local story is even more aggressive. UnslothAI's post says a Dynamic 2-bit version shrinks the 1T-parameter model to 325GB, down 48%, and can run above 40 tok/s on roughly 330GB RAM or VRAM setups.
Unsloth's How to Run Locally guide and Hugging Face release page add the concrete deployment menu:
- Dynamic 1-bit, around 310GB.
- Dynamic 2-bit, around 325GB to 350GB.
- Dynamic Q3, around 385GB to 470GB.
- Q8 lossless, around 605GB.
- Full precision, about 610GB according to UnslothAI's post.
That gives K2.7 Code a strange split personality on day one: a capacity-constrained hosted HighSpeed tier on one side, and a very large but already-documented local path on the other.