Mixedbread releases Wholembed v3 and claims large gains on multimodal retrieval benchmarks
Mixedbread introduced Wholembed v3 as a retrieval model for text, image, video, audio, and multilingual search. Benchmark it on fine-grained retrieval tasks if single-vector embeddings have been collapsing in your pipeline.
TL;DR
- Mixedbread says Wholembed v3 is a new retrieval model for “all modalities and 100+ languages,” positioning it as an omnimodal system rather than another text-only embedder, as summarized in the launch retweet.
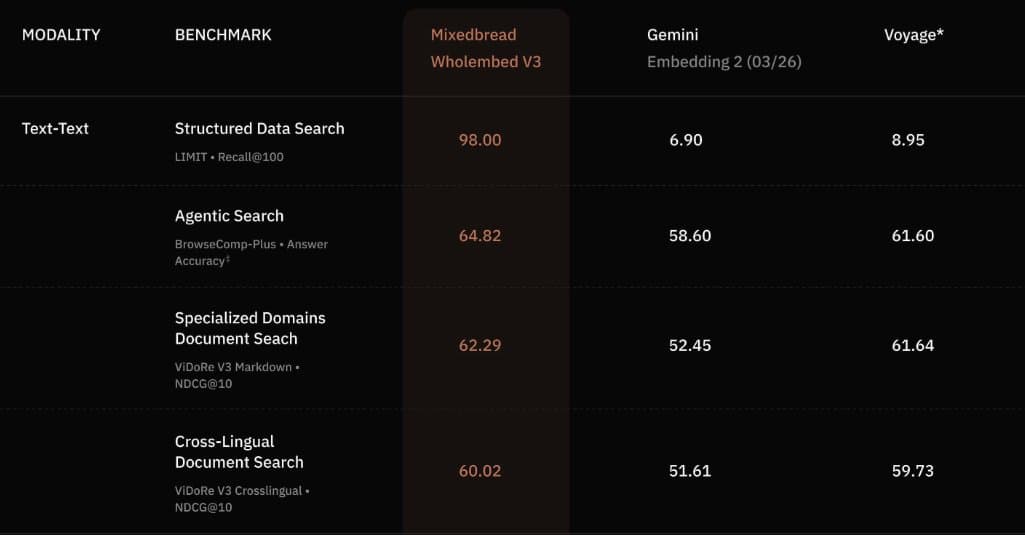
- The strongest public numbers so far come from a benchmark table showing large leads on several retrieval tasks, including 98.00 on Structured Data Search versus 6.90 for Gemini Embedding 2 and 8.95 for Voyage.
- Practitioners focused on late interaction are framing the release as evidence that multi-vector retrieval can beat single-vector embeddings on hard search cases, with one reaction thread arguing the gain “makes such an huge difference in production.”
- Mixedbread has not shared implementation details here, but a follow-up note says the team is open to academic access, which suggests external evaluation and reproduction may follow.
What shipped
Wholembed v3 is being introduced by Mixedbread as a state-of-the-art retrieval model “across all modalities and 100+ languages,” according to the launch wording. The product framing matters for engineers because the claim is not just higher text embedding quality; it is one model for text, image, video, audio, and multilingual search workloads.
The release is also being presented as an omnimodal retrieval system built from “a million different moving parts,” in the words of a team reply, with Mixedbread’s team saying they are “fairly confident it’s the best multimodal model that exists.” Public access details are still thin in this evidence set, but the academic-access post says the company is willing to support research projects even before a formal program exists.
Why the benchmark deltas matter
The public benchmark image shared in the main reaction post shows unusually large gaps on retrieval-heavy tasks. On Structured Data Search with LIMIT and Recall@100, Wholembed v3 posts 98.00, while Gemini Embedding 2 scores 6.90 and Voyage 8.95; on BrowseComp-Plus Agentic Search it scores 64.82 versus 58.60 and 61.60; on ViDoRe V3 Markdown it reaches 62.29 versus 52.45 and 61.64; and on ViDoRe V3 Crosslingual it lands at 60.02 versus 51.61 and 59.73
.
The biggest caveat is that at least one of those tests is explicitly adversarial to standard embeddings. Mixedbread’s Benjamin Clavié says in a follow-up reply that the structured-search benchmark is “designed to test specific breaking cases of embedding model,” making it “very much an all of nothing situation.” That does not negate the result; it narrows its interpretation. If your pipeline fails on fine-grained fields, tables, or other compositional retrieval, the cropped benchmark image suggests Wholembed v3 is aimed directly at those failure modes.
What this suggests for production retrieval
The practical argument from practitioners is less about headline leaderboard wins than about generalization. Antoine Chaffin writes in his thread that multi-vector models “crush benches” but, more importantly, “generalize very well” and make “a huge difference in production.” Another post from the same thread says he is seeing “random SOTAs on new domain” with older models, implying the new release may matter even more off-benchmark than on benchmark domain-generalization reply.
That reading lines up with how retrieval specialists are reacting. A separate practitioner post in the late-interaction reaction calls Mixedbread “world-leading experts in late interaction retrieval” and says late interaction done well can make common embedding models “look like they don’t work.” For engineers, the immediate takeaway is not that single-vector embeddings are obsolete everywhere; it is that workloads with brittle matching, multilingual retrieval, or multimodal search now have a new model claiming large gains, and the strongest evidence so far points to late-interaction style retrieval as the reason.