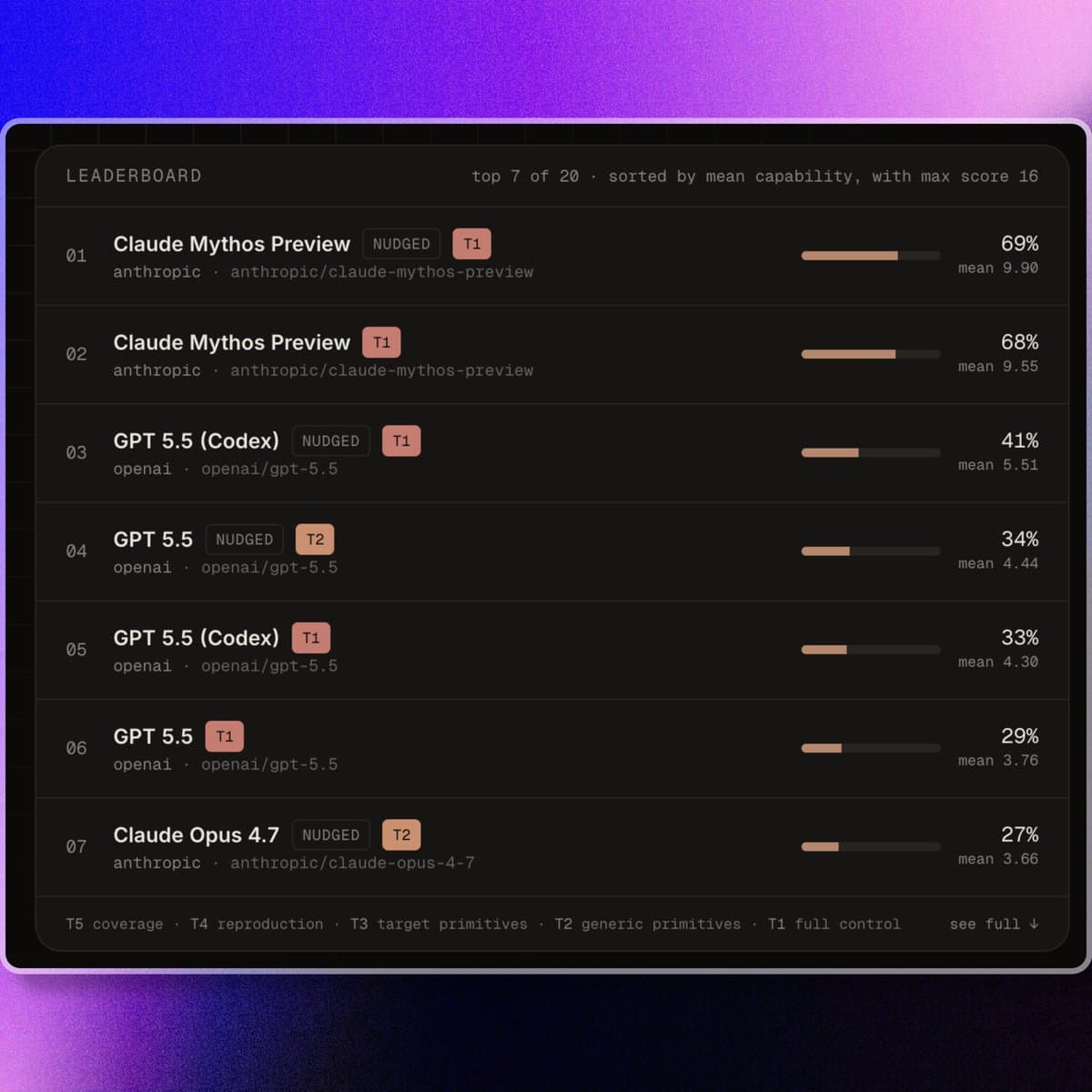
Mythos benchmarks 69% on ExploitBench with 16 T1 envs vs GPT-5.5 Codex's 2
Posts citing ExploitBench put Anthropic's unreleased Mythos at 69% overall and 16 full-control T1 environments, versus GPT-5.5 Codex at 41% and 2. Cost is the main caveat at roughly $36.4k versus $3.1k, while separate posts tied Mythos to an Apple M5 exploit report.
TL;DR
- On ExploitBench, chetaslua's benchmark note and haider1's cost breakdown put Anthropic's unreleased Mythos Preview at 68% to 69%, ahead of GPT-5.5 Codex at 33% to 41% and Claude Opus 4.7 at 24% to 27%.
- The bigger separation is at T1, ExploitBench's "full control" tier: chetaslua's thread says Mythos reached 16 environments, while GPT-5.5 Codex reached 2 and Opus 4.7 reached 0.
- Cost is the obvious catch. According to haider1's screenshot, nudged Mythos used about $36.4k of spend versus about $3.1k for nudged GPT-5.5 Codex, roughly a 12x gap.
- Separate posts tied Mythos to a reported macOS kernel exploit chain: kimmonismus said Calif used it to build a working bypass of Apple's M5 Memory Integrity Enforcement, while rohanpaul_ai's WSJ summary said the chain combined two unknown kernel bugs in five days.
You can check the ExploitBench leaderboard, read the human observations post, and skim Anthropic's earlier Glasswing page plus the big HN thread. The odd detail in the benchmark chatter is that chetaslua's thread says baseline Mythos hit more T1 environments than the nudged run, while eugeneyan's post points to transcript-level reads that looked more like a competent exploit researcher than a benchmark script.
ExploitBench
The headline number floating around X is 69%, but the table in haider1's screenshot is more useful because it shows the pack, not just the winner.
- Claude Mythos Preview NUDGED: 69%, about $36,428 spend haider1's screenshot
- Claude Mythos Preview: 68%, about $25,083 spend haider1's screenshot
- GPT-5.5 Codex NUDGED: 41%, about $3,075 spend haider1's screenshot
- GPT-5.5 Codex: 33%, about $1,255 spend haider1's screenshot
- Claude Opus 4.7 NUDGED: 27%, about $5,631 spend haider1's screenshot
- Claude Opus 4.7: 24%, about $3,636 spend haider1's screenshot
That makes Mythos look less like a narrow edge over Codex and more like a new top line on this particular cyber benchmark.
T1 environments
chetaslua's thread argued that the 69% headline compresses the part that matters most, T1 "full control" environments. On that count, Mythos reportedly reached 16 environments, GPT-5.5 Codex reached 2, and Opus 4.7 reached 0.
The same thread adds one more weird result: baseline Mythos, without hints, reportedly hit more T1s than nudged Mythos chetaslua's source follow-up. If that holds up, hints improved the top-line score without improving the hardest tier.
Spend
The benchmark table makes the tradeoff hard to miss. Nudged Mythos scored 69% at roughly $36.4k, while nudged GPT-5.5 Codex scored 41% at roughly $3.1k haider1's cost breakdown.
dbreunig's remark reduced the flex to two numbers, how many exploits the model finds and how long it takes. The table adds a third number, spend, and right now that number is doing a lot of work.
Apple M5 exploit
The benchmark story is landing next to a separate Mythos claim with much sharper edges. rohanpaul_ai's WSJ summary said Calif used Mythos to help chain two unknown macOS kernel bugs into a working privilege-escalation exploit in five days, targeting the deepest layer of macOS.
According to kimmonismus, the exploit bypassed Apple's new M5 Memory Integrity Enforcement with a data-only attack rather than pointer manipulation, and Calif plans to publish a 55-page technical report after Apple patches. WesRoth's post called it the first public kernel memory-corruption exploit against the M5 chip.
That claim also plugs back into Anthropic's earlier cyber positioning. WesRoth's summary of third-party evals said UK AISI credited Mythos with completing a 32-step network attack in 6 of 10 tries, while eugeneyan's post pointed to transcript reviews describing its bug reproduction and exploitation behavior as unusually strong.