Nous Research releases TST with 2-3x pretraining speedup at matched FLOPs
Nous Research introduced Token Superposition Training, which bags tokens early in pretraining before returning to next-token prediction. The team says TST cuts wall-clock training 2-3x at matched FLOPs while leaving the deployed model unchanged.
TL;DR
- Nous Research says Token Superposition Training, or TST, cuts pretraining wall-clock time by 2 to 3 times at matched FLOPs, while keeping the deployed model identical to a conventionally trained one, according to NousResearch's launch thread.
- The method only changes the first 20 to 40 percent of training: NousResearch's mechanics post says the model reads contiguous bags of tokens, averages their input embeddings, predicts the next bag, then switches back to ordinary next-token prediction.
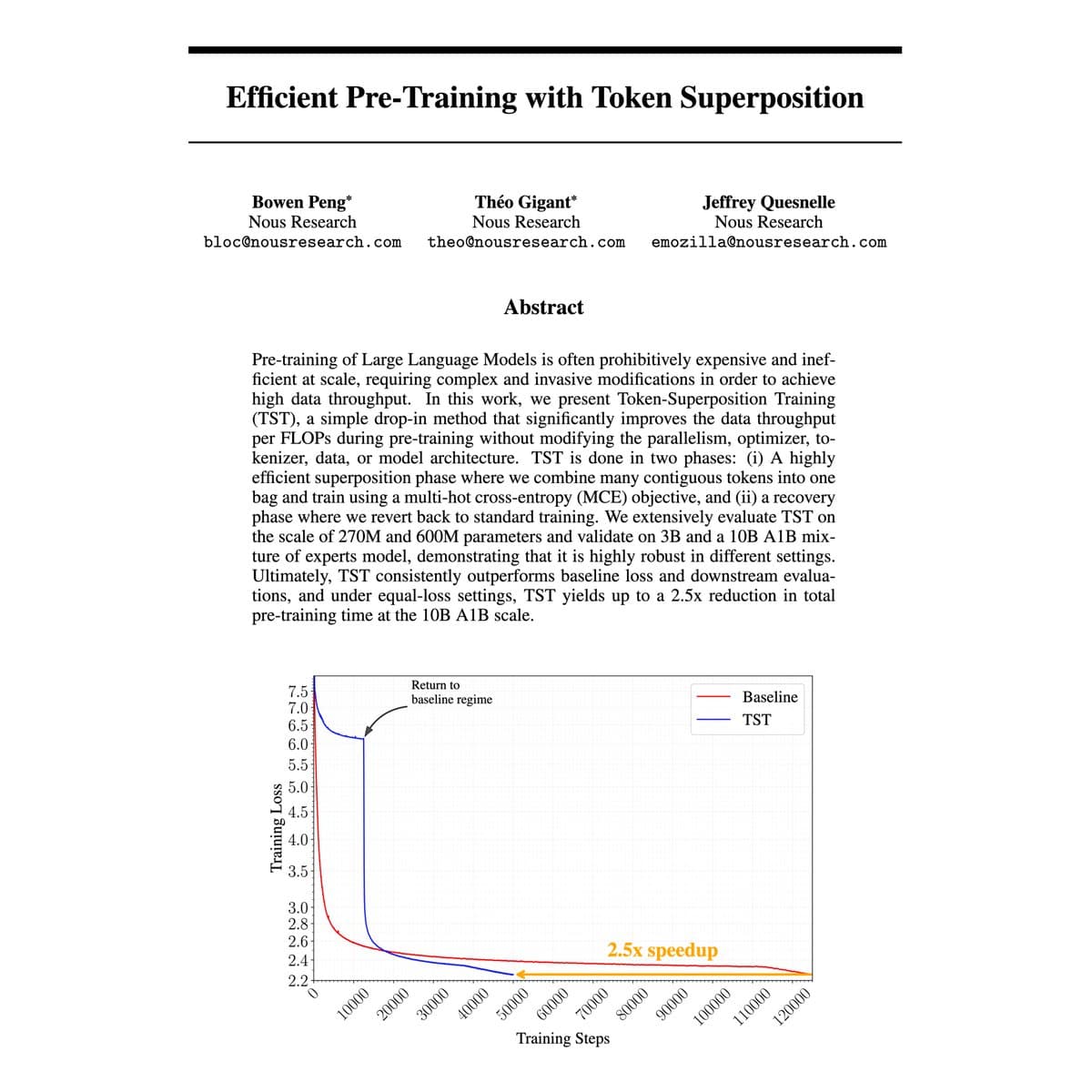
- Across 270M, 600M, 3B dense runs and a 10B-A1B MoE, NousResearch's validation post reports downstream gains over a matched-FLOPs baseline, including +1.6 MMLU points on the 10B run.
- NousResearch's ablation post says TST's two pieces, input-side averaging and output-side multi-hot cross-entropy, each help on their own and combine roughly additively when used together.
- Community reactions from eliebakouch's slide share and eliebakouch's follow-up immediately placed TST next to earlier lines of work such as multi-token prediction and SuperBPE, rather than treating it as a clean-sheet invention.
You can read the paper, the Nous blog post, and the Hugging Face paper card from NousResearch's link post. The fastest useful reveal is that TST is a training-loop trick, not a deployment change, while eliebakouch's slide screenshot makes the visual pitch even clearer: shorter processed length early, vanilla model at the end.
Two-phase pretraining
TST splits pretraining into two regimes. In phase 1, the model processes contiguous bags of tokens instead of single next-token steps. In phase 2, it returns to standard autoregressive training.
According to NousResearch's mechanics post, the input-side change is just a reshape plus a mean over token embeddings, and the output-side change is a sum of standard cross-entropy terms over the next bag. The team explicitly says there is no new kernel, no auxiliary head, and no inference-time architecture change.
That makes the method unusually legible:
- Group contiguous tokens into bags of size k.
- Average embeddings within each bag on the input side.
- Predict the next bag with a modified multi-token loss.
- Run this regime for roughly 20 to 40 percent of training.
- Switch back to ordinary next-token prediction for the rest of the run.
Scale and transfer
Nous says it validated TST on four scales: 270M, 600M, 3B dense, and a 10B-A1B mixture-of-experts run. The 3B and 10B experiments, per NousResearch's validation post, used non-cherry-picked standard hyperparameters.
The most important detail is that the claimed speedup did not stay trapped in loss curves. On the 10B run, NousResearch's validation post reports gains over the matched-FLOPs baseline on HellaSwag (+1.1), ARC-Easy (+0.4), ARC-Challenge (+1.0), and MMLU (+1.6).
The same post says TST has two main knobs:
- Bag size k: Nous says the optimal value may grow with model size.
- Step ratio r: Nous says values between 0.2 and 0.4 worked at every tested scale.
That combination, few knobs and transfer claims on downstream tasks, is why this one landed harder than the usual training-speed thread.
Ablations and prior art
The ablation result is cleaner than the headline. NousResearch's ablation post says both halves of TST, input-side averaging and output-side multi-hot cross-entropy, beat the matched-FLOPs baseline independently, then stack roughly additively together.
Nous also offers two interpretations for the input-side effect in NousResearch's ablation post: it may regularize the embedding table, or it may act like a cheap pre-pretraining stage on a coarser version of the same corpus.
Community readers quickly connected the design to older efficiency ideas. eliebakouch's slide share described TST as building on prior work like multi-token prediction and SuperBPE, while eliebakouch's follow-up noted that the method is "not new" in a broad sense and pointed to earlier related papers. itsclivetime's reaction thread independently summarized the core recipe as mean-pooled 8-token segments predicting the next segment, which is almost the whole idea in one line.
Decoupling from deployment
The strongest strategic claim in the thread is not the 2 to 3 times number. It is the decoupling. NousResearch's decoupling post argues that TST improves training-time efficiency without locking the final model into a special inference stack, which makes it composable with other pretraining changes such as sparse attention, MoE routing, tokenizer swaps, or optimizer changes.
That framing also lines up with another Nous-adjacent theme from this week. In omarsar0's Lighthouse Attention summary, a separate Nous paper called Lighthouse Attention was described as a training-only wrapper around standard attention that can be removed near the end of training. TST applies the same general instinct to the token prediction loop instead of the attention layer.