Ollama moved its Apple Silicon runtime onto MLX, added NVFP4 support, and published higher prefill and decode speeds on M5 hardware in a preview release. The update also improves cache reuse for branching agent sessions and ships direct launch paths for Qwen3.5-35B-A3B with Claude Code and OpenClaw.
qwen3.5:35b-a3b-coding-nvfp4, it wants a Mac with more than 32 GB of unified memory, and Ollama says wider model architecture support is still coming get started, future models.The curiosities list is unusually concrete. Ollama is explicitly naming Claude Code and OpenClaw as target workloads, the preview is tied to a single Qwen 3.5 coding model, and the community immediately treated the post like a serious local inference milestone, pushing the HN thread past 600 points. The real story here is that Ollama is tightening the loop between local Mac inference and the production formats and agent patterns engineers already use.
Ollama says Apple Silicon is now powered by MLX, Apple’s machine learning framework, so it can lean on unified memory directly and, on M5-class chips, use GPU Neural Accelerators for both time to first token and steady-state decode Official blog post.
That makes this the biggest technical change in the release. The new CLI commands and model packaging matter, but the lasting part is the runtime shift. If you build local coding or assistant workflows on Macs, backend architecture is what decides whether a 35B model feels usable or frustrating.
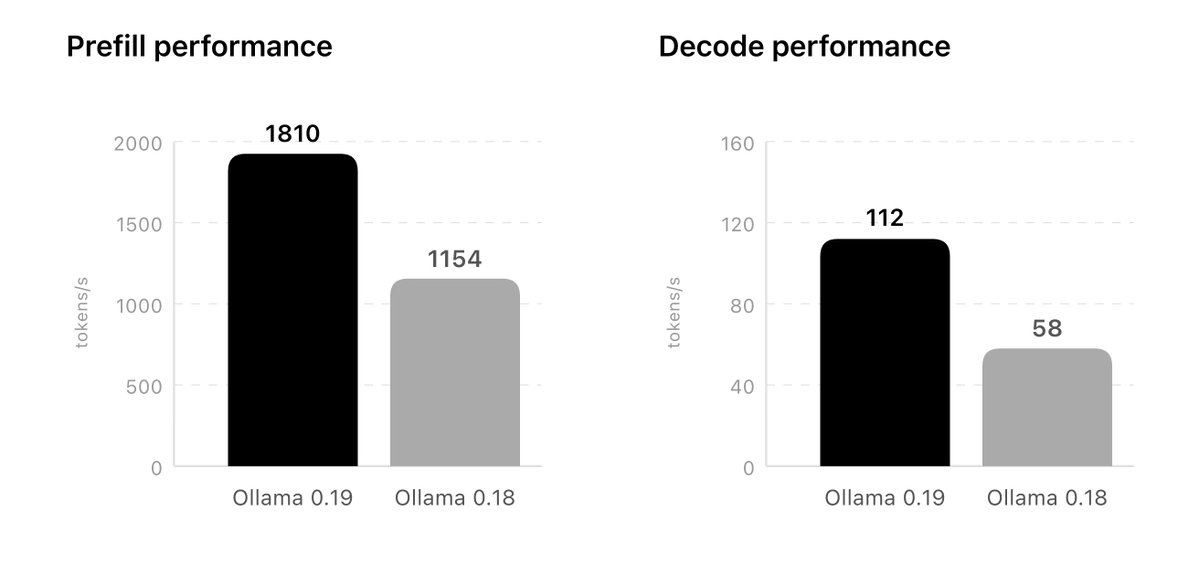
The published charts show the biggest jump in prefill, from 1154 tokens/s on Ollama 0.18 to 1810 on the preview path. Decode moves from 58 to 112 tokens/s, which is still a large gain, but the prefill jump is the more important one for agent workflows that repeatedly resend long system prompts, tool schemas, and conversation state Official blog post.
Ollama also slips in an even better number than the chart headline. In the fine print, it says Ollama 0.19 reaches 1851 prefill and 134 decode with int4 quantization on the same setup performance numbers. For engineers benchmarking local stacks, that means the launch graphic is not the ceiling.
NVFP4 is easy to read as marketing shorthand for "smaller model, faster run." Ollama is arguing for something more useful: local parity with hosted inference environments that are starting to standardize on the same format Official blog post.
That matters if you prototype prompts or agent behavior locally and then deploy to an inference provider later. Ollama says NVFP4 preserves model accuracy while reducing memory bandwidth and storage pressure, and it also opens the door to models optimized with NVIDIA’s model optimizer NVFP4 support. The practical pitch is consistency, not just speed.
This section of the release is more interesting than the benchmark charts. Ollama says it can now reuse cache across conversations, checkpoint intelligent points in the prompt, and keep shared prefixes alive longer even when older branches are evicted cache upgrades.
That is a direct fit for coding agents. Branch a session, keep a large shared system prompt, bounce between tool calls, and the runtime does less repeated work. Ollama even names Claude Code in the explanation, which makes the target scenario obvious Official blog post. If the MLX rewrite is the engine upgrade, this cache redesign is the part engineers will feel in day to day use.
The preview is not a general "all Macs are faster now" release. It is centered on qwen3.5:35b-a3b-coding-nvfp4, with tuned sampling parameters for coding, and Ollama recommends more than 32 GB of unified memory Official blog post.
The commands also show how opinionated Ollama has become about local AI entry points:
ollama launch claude --model qwen3.5:35b-a3b-coding-nvfp4ollama launch openclaw --model qwen3.5:35b-a3b-coding-nvfp4ollama run qwen3.5:35b-a3b-coding-nvfp4That is notable on its own. Ollama is not only shipping a faster runtime, it is packaging curated launch paths for specific agent surfaces get started, blog post.
Ollama says support is expanding, and promises an easier import path for custom fine tuned models on supported architectures future models. Right now, that is the main caveat to keep in mind.
So the release lands as a high-end preview, not a universal local inference upgrade. But even in that narrow form, it sets a clear direction: Apple Silicon support is becoming a first-class runtime strategy, and Ollama wants local coding agents on Mac to benefit from the same quantization formats, cache behavior, and workflow shortcuts engineers expect from production systems.
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework. This change unlocks much faster performance to accelerate demanding work on macOS: - Personal assistants like OpenClaw - Coding agents like Claude Code, OpenCode, Show more
This results in a large speedup of Ollama on all Apple Silicon devices. On Apple’s M5, M5 Pro and M5 Max chips, Ollama leverages the new GPU Neural Accelerators to accelerate both time to first token (TTFT) and generation speed (tokens per second). note: test was conducted on Show more

NVFP4 support: higher quality responses and production parity Ollama now leverages NVIDIA’s NVFP4 format to maintain model accuracy while reducing memory bandwidth and storage requirements for inference workloads. As more inference providers scale inference using NVFP4 format, Show more

Improved caching for more responsiveness Ollama’s cache has been upgraded to make coding and agentic tasks more efficient. Lower memory utilization: Ollama will now reuse its cache across conversations, meaning less memory utilization and more cache hits when branching when Show more
Get started This preview release of Ollama accelerates the new Qwen3.5-35B-A3B model. Please make sure you have a Mac with more than 32GB of unified memory. Claude Code: ollama launch claude --model qwen3.5:35b-a3b-coding-nvfp4 OpenClaw: ollama launch openclaw --model Show more
Future models We are actively working to support future models. For users with custom models fine-tuned on supported architectures, we will introduce an easier way to import models into Ollama. In the meantime, we will expand the list of supported architectures. Show more