OpenAI releases GPT-5.4 mini and nano with 400K context
GPT-5.4 mini and nano bring 400K context, multimodal input, and the full GPT-5.4 reasoning-mode ladder at lower prices. Early benchmarking suggests nano is the strongest cost-performance tier for agentic tasks, but both models spend far more output tokens than peers.
TL;DR
- OpenAI has released GPT-5.4 mini and nano, the first smaller GPT-5.4 variants, with multimodal image input, a 400K-token context window, and the same reasoning-effort ladder as the full model, according to the launch thread.
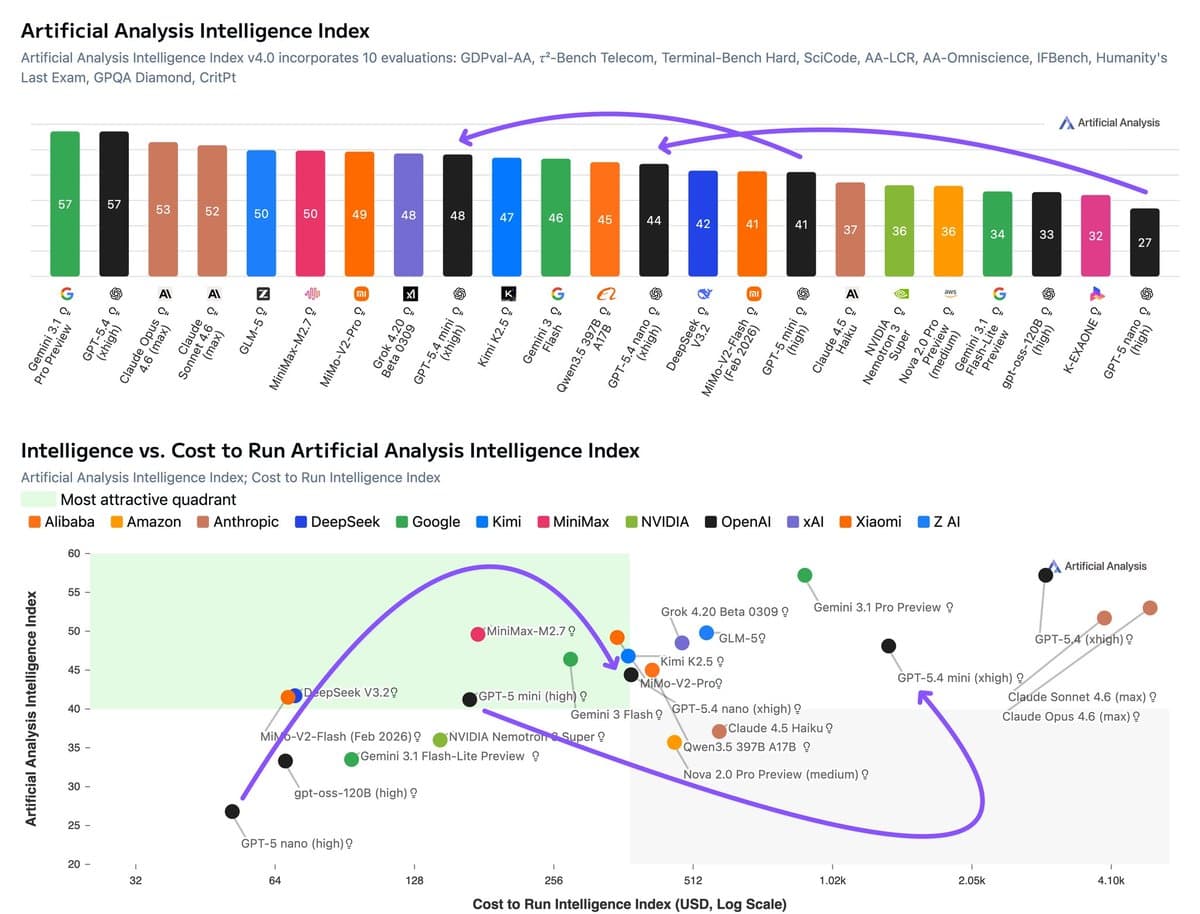
- Artificial Analysis' benchmark thread says GPT-5.4 nano is the stronger cost-performance tier: at xhigh reasoning it scored 44, ahead of Claude Haiku 4.5 at 37 and Gemini 3.1 Flash-Lite Preview at 34, while listing lower per-token pricing.
- The agentic picture is mixed but useful: GDPval-AA results put GPT-5.4 mini at 1405, ahead of Gemini 3 Flash Preview at 1191 but behind Claude Sonnet 4.6 at 1633, while nano landed at 1169, roughly even with Claude Haiku 4.5.
- The tradeoff is token burn. Artificial Analysis' usage note says both models used 200M+ output tokens at xhigh reasoning, with mini around 235M and nano around 210M, materially above several competing small models.
What shipped in GPT-5.4 mini and nano?
OpenAI's smaller GPT-5.4 variants inherit most of the implementation-facing surface area of the flagship model. Artificial Analysis says both mini and nano support text-plus-image input, text output, a 400K context window, and the full reasoning setting ladder from xhigh down to none launch thread. Pricing is substantially lower than full GPT-5.4: mini is listed at $0.75 per 1M input tokens and $4.50 per 1M output tokens, while nano is $0.20 and $1.25, versus $2.50 and $15 for GPT-5.4 pricing details.
The early benchmark picture favors nano more than mini. In Artificial Analysis' results breakdown, GPT-5.4 nano at xhigh scored 44 on its Intelligence Index, up from 27 for GPT-5 nano, while mini reached 48, up from 41 for GPT-5 mini. The linked model comparison page also lists GPT-5.4 nano at 213.3 tokens/sec with knowledge up to August 2025.
Where do these models win, and what is the catch?
On task-oriented evaluations, both models look competitive for agentic workloads. Artificial Analysis' GDPval-AA results puts mini at 1405 on agentic real-world work tasks, ahead of Gemini 3 Flash Preview's 1191, and nano at 1169, just behind Claude Haiku 4.5's 1173 and well ahead of Gemini 3.1 Flash-Lite Preview's 944. The same benchmark breakdown says nano also led its smaller-model peers on τ²-Bench and TerminalBench, posting 81% and 42% respectively.
The catch is efficiency and reliability. Artificial Analysis says both models were "more verbose," consuming over 200M output tokens to run the index, with mini using about 3.4x the output tokens of GPT-5 mini and more than Claude Sonnet 4.6 despite scoring lower overall usage note. It also reports weak AA-Omniscience results driven by high hallucination rates: mini at -18.7 with a 90% hallucination rate, and nano at -29.6 with 74%, partly because both models "attempt to answer far more questions" instead of abstaining hallucination details. That leaves nano as the more attractive deployment tier on current numbers: Artificial Analysis estimates an effective run cost around $376 for nano versus about $1,406 for mini, while still showing nano ahead of Haiku 4.5 on its cost-to-intelligence tradeoff cost analysis.