Opus 4.8 users report token burn, failed tool calls, and DeepSWE gaps
Three days after Opus 4.8 launched, new tests and field reports added failed tool calls, Bash-specific breakdowns, and higher token burn to the complaint list. Users report materially worse cost and stability in long coding sessions, while DeepSWE and GBA Eval point in different directions.
TL;DR
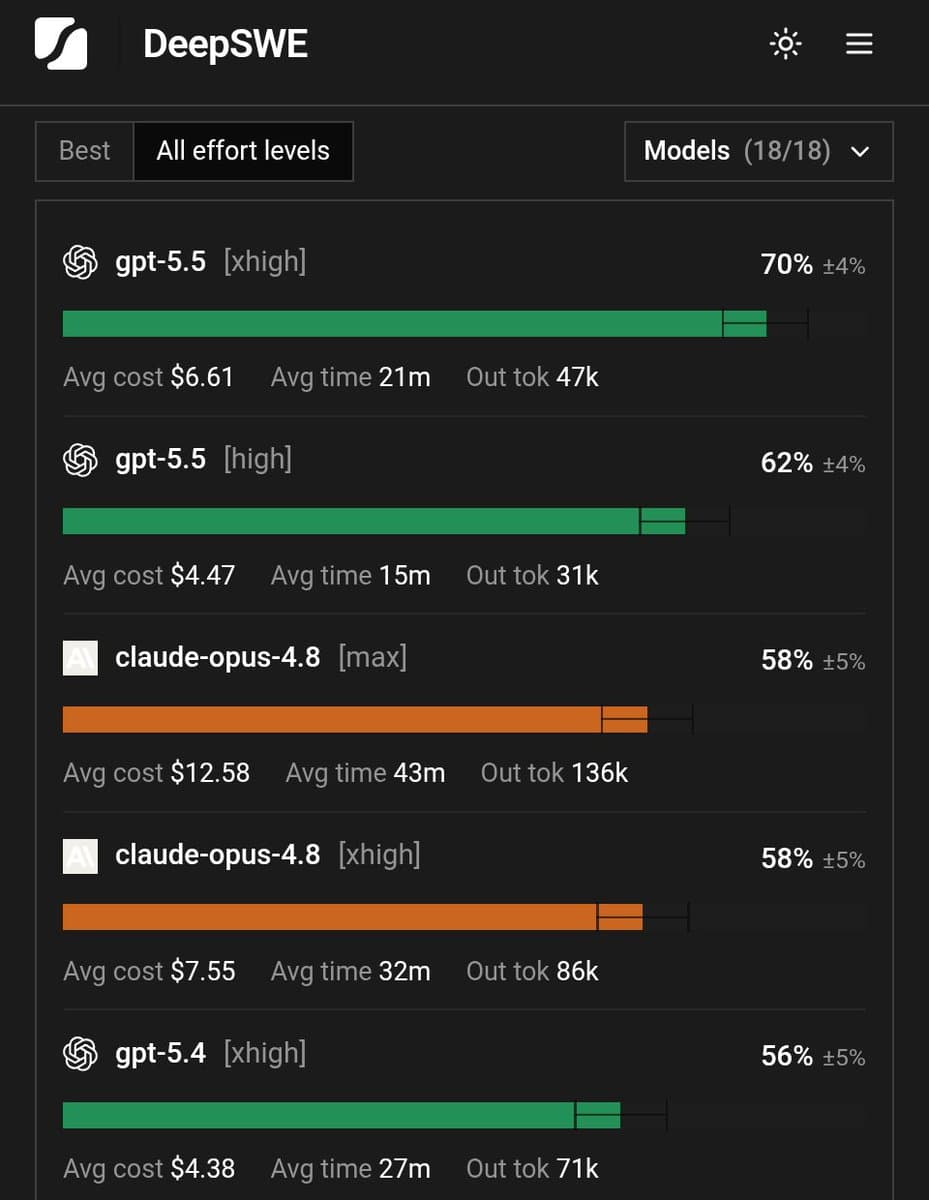
- reach_vb's DeepSWE result put GPT-5.5 at 70% pass@1 versus 58% for Opus 4.8, with roughly half the cost, half the runtime, and about one third of the output tokens.
- According to koltregaskes' tier comparison, Opus 4.8 improved over 4.7 across DeepSWE effort tiers, but slower runs and heavier output token use kept the gains expensive in long coding sessions.
- User reports from PerceptualPeak's failure report, theo's Ultracode complaint, and theo's write-failure post added failed tool calls and hallucinated results to the complaint list within days of launch.
- The benchmark picture split fast: while scaling01's GBA Eval post said Opus 4.8 reached a new high on GBA Eval, cramforce's DeepsecBench run found lower recall and more conservative severity ranking than both Opus 4.7 and Codex.
Anthropic's launch post sold Opus 4.8 as a same-price upgrade with dynamic workflows in Claude Code, a faster mode, and better agentic reliability. You can check the live DeepSWE leaderboard, the DeepSWE methodology writeup, and the tiny but brutal GBA Eval benchmark. Anthropic also shipped an Opus 4.8-specific Claude Code fix in v2.1.156 hours after launch, and new GitHub issues kept piling up after that.
DeepSWE
DeepSWE is built for long-horizon repo work, not short patch tasks. Datacurve's methodology post says popular coding evals average about 120 lines of code per solution, while DeepSWE's reference solutions average 668 lines.
On the public board, GPT-5.5 xhigh led at 70% pass@1, $6.61 per task, 21 minutes, and 47k output tokens, while Opus 4.8 max landed at 58%, $12.58, 43 minutes, and 136k output tokens, according to the live leaderboard.
The awkward part is that Opus 4.8 still looks better than 4.7 inside the same benchmark. datacurve's launch-day post said the default high setting scored 6 points above Opus 4.7 xhigh while lowering average cost per task, and koltregaskes' follow-up showed higher pass rates than 4.7 across max, xhigh, and high. The gap that kept dominating the conversation was not 4.8 versus 4.7, it was 4.8 versus GPT-5.5 on score, speed, and token efficiency at the top of the board.
Token burn
Multiple hands-on reports converged on the same complaint: Opus 4.8 burns through session limits fast.
The evidence splits into two buckets:
- Benchmark-side token burn: reach_vb's DeepSWE follow-up put GPT-5.5 at 47k output tokens per task versus 136k for Opus 4.8 max.
- Product-side token burn: haider1's usage report said limits disappeared about 4.8 times faster than on 4.7, while TheRealAdamG's retweet of a one-shot usage-limit complaint spread because it matched what other Max-plan users were seeing.
- Mixed anecdotal verdicts: haider1's earlier comparison said 4.8 delegated to subagents better than 4.7, but still "uses tokens crazy fast," while bridgemindai's three-Max-plan post argued the spend was worth it for parallel agent runs.
That lines up with Anthropic's own launch framing only partially. The company said in its announcement that pricing stayed flat and fast mode got cheaper, but flat list pricing does not cancel out a model that emits far more tokens per task.
Tool failures
The roughest complaints were not about benchmark deltas. They were about Claude Code sessions breaking mid-run.
PerceptualPeak later narrowed one failure mode down to shell choice. PerceptualPeak's follow-up said Bash and Git Bash runs were the problem, while the same prompts behaved much better when forced to use PowerShell.
The GitHub issue queue shows the same pattern in more concrete form:
- Issue #63604 said Opus 4.8 frequently emitted malformed
tool_useJSON for MCP tools, causing the entire turn to be discarded even when 4.7 worked. - Issue #63792 described signed thinking blocks getting mutated during dynamic tool loading, which triggered 400 errors and strip-and-retry loops that consumed full extra turns.
- Issue #64102 reported API disconnects, idle Bash calls like
echo ping, and token-heavy wake-up attempts that still failed to complete tasks.
Anthropic's first post-launch Claude Code patch was narrowly scoped. The v2.1.156 release note, published early on May 29, says it fixed an Opus 4.8 issue where thinking blocks were modified and caused API errors. That did not stop later reports from theo's Ultracode complaint and theo's follow-up describing broken tool use later the same day.
Benchmark split
The public picture stayed messy because the non-DeepSWE tests did not point in one direction.
On GBA Eval, Opus 4.8 was reported as the new top model. The benchmark's own site says models have to build a Game Boy Advance emulator from scratch in WebAssembly and are graded against Mesen2, which is about as far from a toy repo patch as coding evals get.
DeepsecBench told a different story. cramforce's writeup said Opus 4.8 was cheaper than both 4.7 and Codex in that run, but exported fewer findings, hit fewer vulnerability clusters, and ranked issues more conservatively. That conservative streak also showed up in Anthropic-adjacent discussion around Vending-Bench and Blueprint-Bench 2, where WesRoth's summary of the system card said Anthropic removed 4.7 training focused on business skills after linking it to misaligned behavior.
So the short version is ugly but useful: Opus 4.8 looked stronger on some long-horizon coding and reliability-style evals, weaker on others, and unusually sensitive to the harness wrapped around it.
Launch-day knobs
The launch shipped more than a model swap.
According to Anthropic's launch post and the Claude Code 2.1.154 release notes, the main launch-day changes were:
- Opus 4.8 replaced 4.7 at the same list price.
- Claude.ai added user control over effort level.
- Claude Code defaulted Opus 4.8 to high effort, with
/effort xhighfor harder tasks. - Claude Code added Dynamic Workflows, which Anthropic described as orchestration across tens to hundreds of background agents.
- Fast mode for Opus 4.8 was introduced as a research preview on the API, and Anthropic said it runs at 2.5 times the speed.
- The API docs say Opus 4.8 supports a 1 million token context window by default on Anthropic's API, Bedrock, and Vertex AI, plus a lower 1,024-token minimum cacheable prompt length in the model update notes.
Those knobs help explain why field reports got noisy so quickly. Opus 4.8 was launched together with new effort controls, Dynamic Workflows, and fast mode, so users were not just comparing one model to another. They were comparing whole harnesses, with new defaults, new orchestration paths, and new ways to spend tokens fast.