Prime Intellect launches Hosted Evaluations with harnesses, sandboxes, and rollouts viewer
Prime Intellect launched Hosted Evaluations to manage harnesses, sandboxes, and rollout inspection for model testing. The service packages eval infrastructure while still supporting local runs against arbitrary engines, so teams can centralize testing without losing flexibility.
TL;DR
- Prime Intellect said in the launch post relay that Hosted Evaluations turns evals into a managed service, packaging the harnesses, sandboxes, and other infra pieces teams usually stitch together themselves.
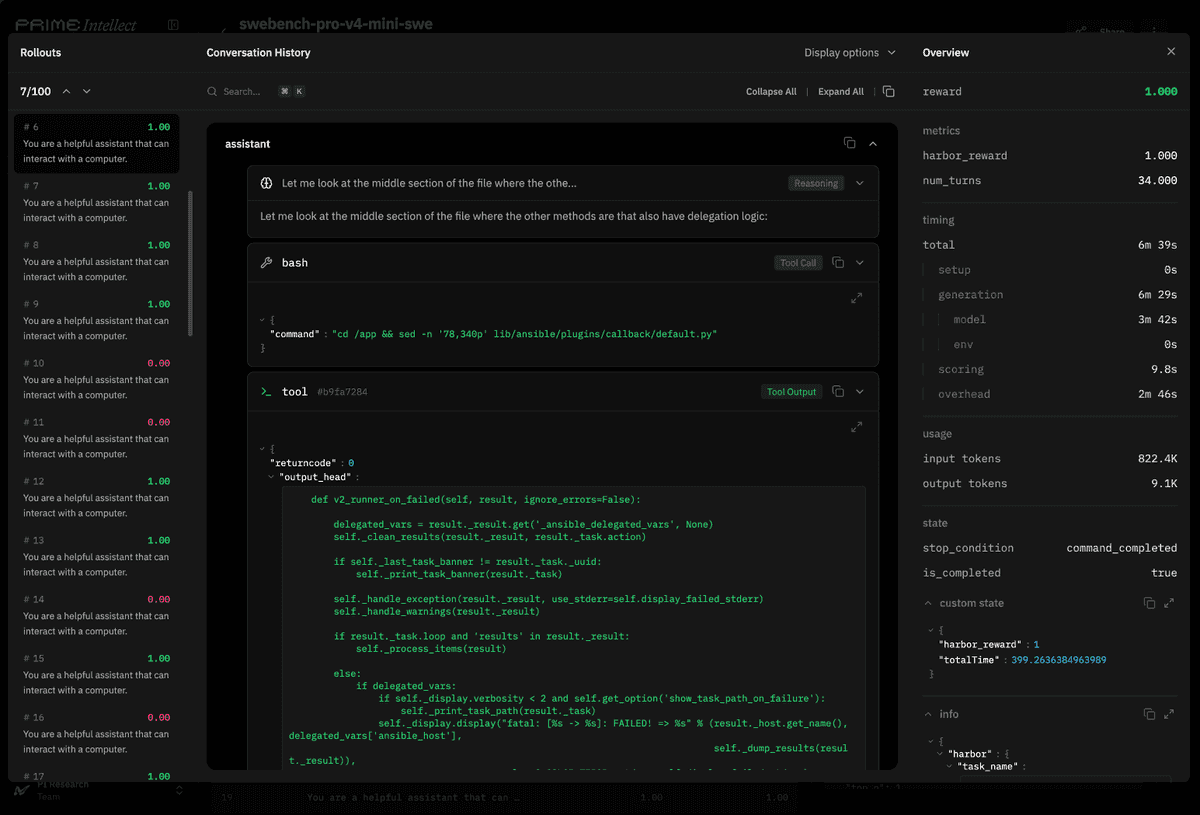
- xeophon's demo clip and eliebakouch's rollout viewer post both center the UI story: create a run, inspect rollouts, and browse eval data from one viewer instead of piecing logs together by hand.
- The launch does not lock teams into Prime Intellect-hosted inference, because Ivan Fioravanti's repost via TheZachMueller highlights local eval runs against any model or engine.
- johannes_hage's post points to Prime Intellect's blog post, while eliebakouch's follow-up says xeophon also published a deeper walkthrough.
You can jump straight to the official launch post, watch the short product demo, and get a feel for the UI from the rollout viewer screenshot. One useful wrinkle came from Ivan Fioravanti's repost: the same eval stack can still run locally against arbitrary engines. Separately, Vtrivedy10's workflow note shows people already pairing Prime Intellect's CLI with coding agents for RL-style experiment setup.
Hosted Evaluations
Prime Intellect's pitch is blunt: evals are an infra problem. The launch framing in the announcement relay names the usual moving parts, including harnesses and sandboxes, then offers Hosted Evaluations as the layer that manages them.
That makes this a packaging story more than a new benchmark story. johannes_hage describes it as the smoothest way to run evals, with the official write-up living in the company blog post.
Rollouts viewer
The most concrete product reveal is the rollouts viewer. eliebakouch calls out how easy it is to create runs, inspect outputs, and look at eval data, while xeophon's demo clip shows the feature live instead of as a static screenshot.
For engineering teams, that shifts the product from pure job execution toward inspection. The launch is not just about firing evals, it is about having a place to look through rollout traces after the run finishes.
Local engines
One of the more useful details came from outside the main announcement. Ivan Fioravanti's repost via TheZachMueller says you can run Prime Intellect evaluations locally against any model or engine.
That means the hosted layer is not presented as an all-or-nothing runtime. Teams can centralize parts of evaluation management without giving up the ability to point the harness at whatever engine they already use.
CLI and agent-driven setup
Vtrivedy10 described using a skill, the Prime Intellect CLI, and Codex's in-context learning to set up an RL-style workflow, debug niche errors, and leave the human role mostly to interpreting results and deciding next steps.
That post is not the product announcement, but it does add a concrete picture of how the tooling is being used around launch day: not only as a UI for hosted evals, but as part of an agent-assisted experimentation loop. eliebakouch's follow-up also points readers to a deeper walkthrough from xeophon, suggesting more product detail is landing outside the initial launch blurb.