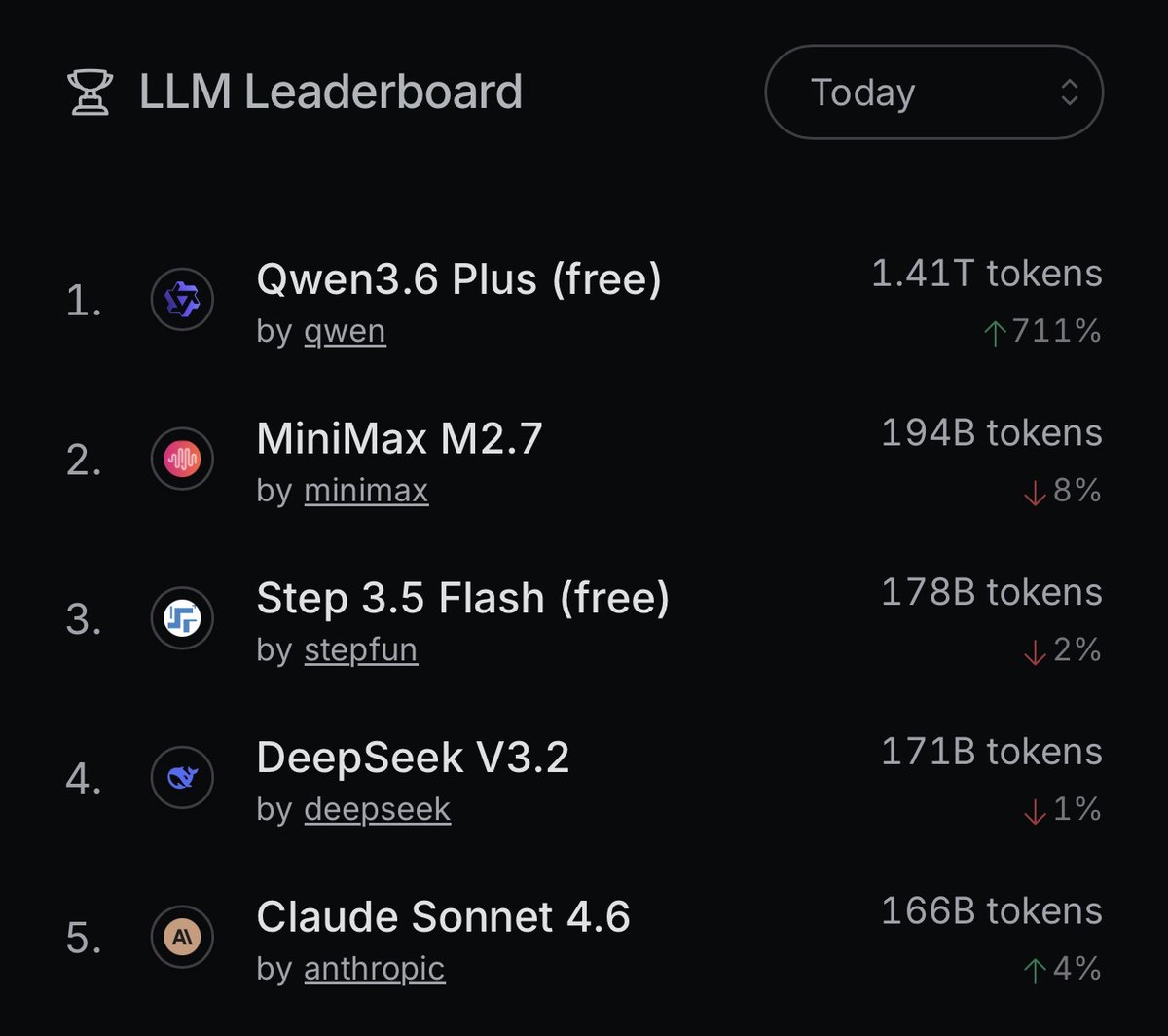
OpenRouter said Qwen3.6-Plus became its first model to process more than 1 trillion tokens in a single day, and Alibaba said it reached the platform's top rank. The usage milestone adds adoption signal to the 1M-context launch and makes live code-arena comparisons more relevant.
You can read Alibaba's official launch post, skim the fuller Alibaba Cloud mirror, pull up the OpenRouter model card, or check the broader Qwen collection page, which already shows even higher cumulative token volume. There is also a live Code Arena entry for head to head coding tests.
OpenRouter framed the story as an adoption event, not just a launch. Its post said Qwen3.6-Plus processed roughly 1.4 trillion tokens in one day, the strongest full-day performance for any new model released this year on the platform.
Alibaba amplified that signal a few minutes later, saying Qwen3.6-Plus had already reached the top spot on OpenRouter. OpenRouter's own Qwen collection page now shows 1.81T cumulative tokens for the free model, which suggests the day-one spike kept compounding after the initial post.
Alibaba's launch post described Qwen3.6-Plus as a major step up from Qwen3.5 for real-world agents, with immediate API access and a default 1 million token context window. The OpenRouter model page repeats the same core pitch: hybrid linear attention plus sparse MoE routing, free access, and strength on repository-scale problem solving.
According to Alibaba's launch materials and the benchmark summary circulating alongside them, the headline numbers include:
Arena moved quickly to turn the launch into a live comparison target. Its post says Qwen3.6-Plus is available in both Text and Code Arena, and the Code Arena framing is unusually concrete: real-world agentic web development tasks, with HTML or React apps you can share or download.
That makes the early benchmark chatter more interesting than the usual screenshot tour. One community post put Qwen3.6-Plus at 71.5 on the Extended NYT Connection Benchmark, far ahead of the two comparison scores in the same post, although that is a narrower unofficial signal than the vendor benchmarks.
One of the first community reactions was not about raw capability, but how expensive those capabilities feel in practice. A reply-post comparing Qwen3.5 27B with Gemma 4 31B argued that paper wins matter less if the model burns far more tokens to get there.