Gemma 4 picked up benchmark, quantization, and runtime support across NVIDIA, Apple MLX, vLLM, and local toolchains a day after launch. The 31B and MoE variants can now be tested on laptops, RTX rigs, and serving stacks without custom integrations.
You can read the DeepMind launch post, the vLLM Gemma 4 announcement, and NVIDIA's two deployment writeups, one on Blackwell and NVFP4 and one on RTX and llama.cpp. The vLLM v0.19.0 release notes landed the next day, while the main HN thread immediately turned into a compatibility and local-serving logbook.
DeepMind's launch post frames Gemma 4 as the Gemini 3-derived open family, not a single flagship checkpoint. The practical split is straightforward: E2B and E4B for tighter memory budgets, 26B A4B as the MoE middle tier, and 31B dense for the best reasoning numbers.
Gemma 4 — Google DeepMind
1.7k upvotes · 455 comments
Artificial Analysis pulled the family into one clean inventory Artificial Analysis breakdown:
The release also changed the licensing story. Gemma 4 moved to Apache 2.0, where Gemma 3 had shipped under Gemma Terms of Use Artificial Analysis breakdown.
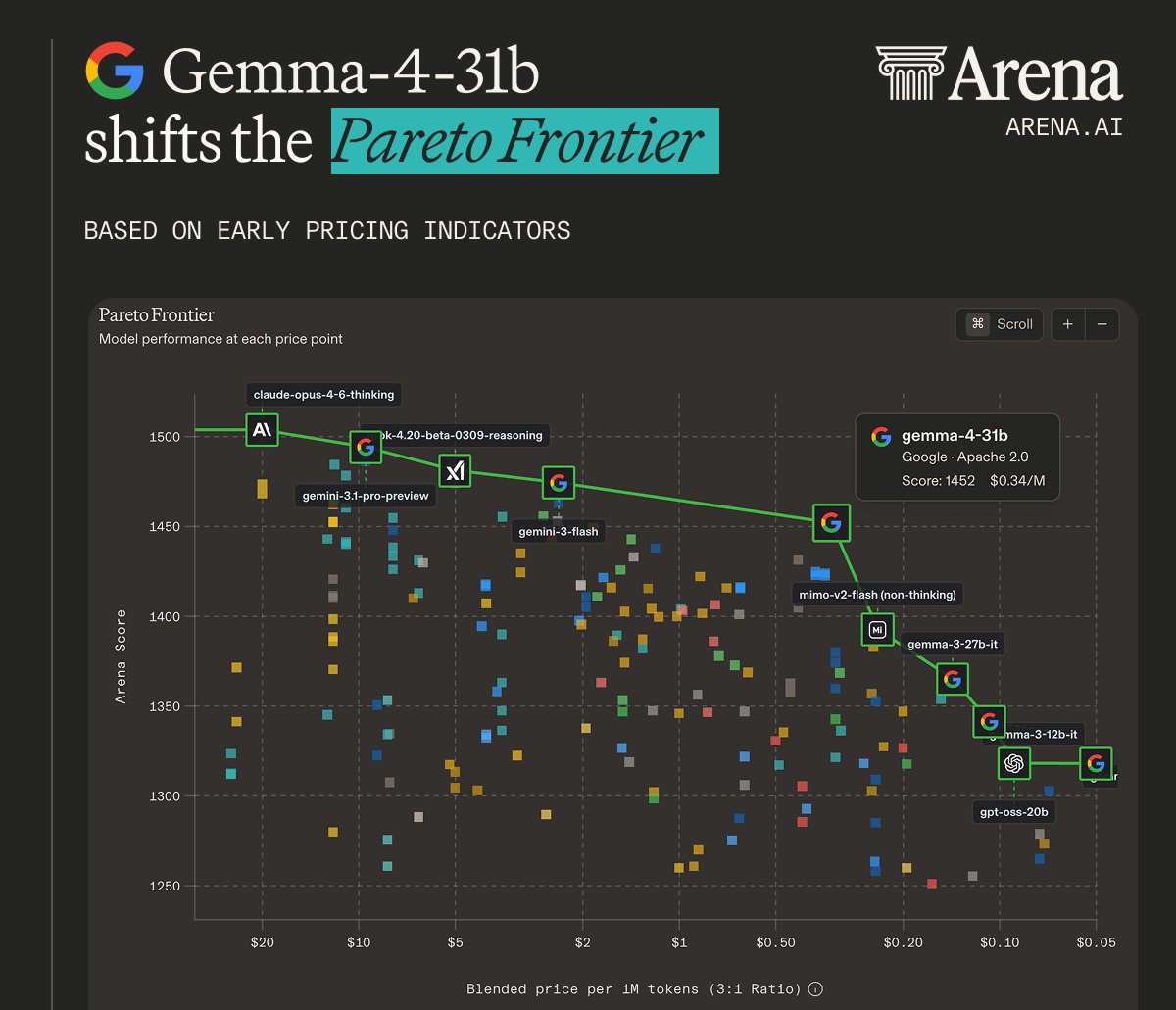
The loudest chart on launch day was the Arena Pareto plot. Arena placed Gemma 4 31B roughly 30 points above similarly priced models like DeepSeek 3.2, with the usual caveat that the pricing inputs were still early third-party estimates.
Artificial Analysis gave the more useful engineer readout: Gemma 4 31B landed at 39 on its Intelligence Index, behind Qwen3.5 27B Reasoning at 42, but it used 39 million output tokens to run the index versus Qwen's 98 million and GLM-4.7's 167 million Artificial Analysis breakdown Token efficiency follow-up.
That made two different launch stories run in parallel:
Artificial Analysis also noted where the gap remained. Gemma 4 31B stayed competitive on several non-agentic evals, but trailed Qwen3.5 mainly on agentic performance Artificial Analysis breakdown.
vLLM treated Gemma 4 like a first-class launch, not a later compatibility patch. Its launch post said support was immediate across multiple hardware backends, including day-zero support on Google TPUs, AMD GPUs, and Intel XPUs, and the 0.19.0 release notes spelled out full architecture support for MoE, multimodal, reasoning, and tool use.
The release notes tied Gemma 4 support to a broader inference-stack upgrade v0.19.0:
The other hardware-side addition came from NVIDIA. Its technical post said an NVFP4 quantized Gemma-4-31B checkpoint was already available through NVIDIA Model Optimizer for Blackwell developers using vLLM, a very specific sign that Google and inference vendors had pre-coordinated the rollout NVIDIA technical post.
The community evidence looked good, but messy in the familiar open-model-launch way. The HN thread quickly filled with reports from Ollama, llama.cpp, LiteRT-LM, and OpenCode-style harnesses, plus notes on memory, backend flags, and parser bugs HN deployment delta.
A few details stood out:
litert-lm --backend gpu on Apple Silicon gave a large prefill and decode speedup HN comment on LiteRT-LM GPU backend.That combination, solid demos plus same-day parser and tokenizer fixes, is basically Christmas come early for coding agent nerds.
Google also used Gemma 4 to push a more aggressive on-device story than the usual laptop demo loop. The Google Developers post pitched Gemma 4 for multi-step planning, autonomous action, offline code generation, and function-calling-style agent flows on-device, with access through Google AI Edge and Android's new AICore Developer Preview Google Developers post.
NVIDIA's launch material made the same point from the hardware side, positioning the family across Blackwell servers, RTX workstations, DGX Spark, and Jetson edge systems RTX deployment post NVIDIA technical post.
The odd little launch artifact was that the consumer-facing iPhone path showed up almost immediately too. A tweet linking Google's AI Edge Gallery app claimed Gemma 4 models were already runnable offline on iPhone, with "Thinking Mode" and "Agent Skills" called out in the update card AI Edge Gallery iPhone app.
Fresh discussion on Google releases Gemma 4 open models
1.7k upvotes · 455 comments