Ollama adds MLX preview on Apple Silicon with reported 2.2x speedups
Ollama's Apple Silicon preview switches local inference to MLX, and users reportedly see sizable speedups with some Qwen3.5 variants on M-series Macs. Try it if you run local coding agents, since faster prefill and caching can cut session reload time.
TL;DR
- Ollama's 0.19 preview swaps its Apple Silicon backend to Apple's MLX framework, and the company says that lifts Qwen3.5-35B-A3B prefill from 1154 to 1810 tokens per second and decode from 58 to 112 on M5-class chips Ollama blog.
- The preview is narrowly targeted: Ollama says the accelerated path currently centers on
qwen3.5:35b-a3b-coding-nvfp4, tuned for coding tasks, and needs a Mac with more than 32GB of unified memory Ollama blog. - Ollama also changed cache behavior, reusing cache across conversations, storing checkpoints at prompt breakpoints, and keeping shared prefixes alive longer, which is why the post explicitly calls out Claude Code, Codex, Pi, and OpenClaw Ollama blog.
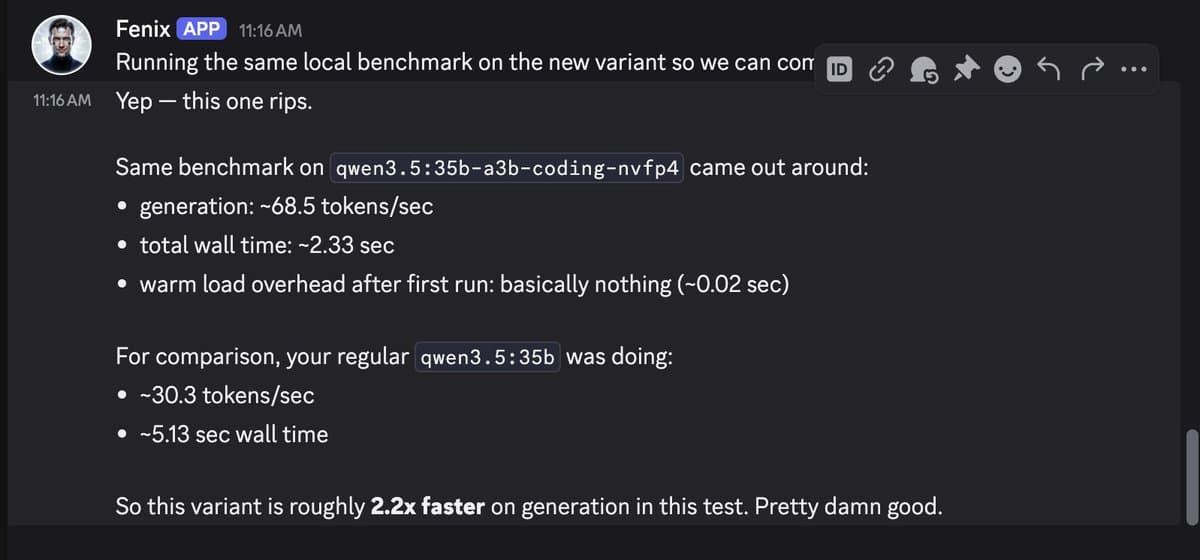
- Early user reports line up with the headline numbers: one shared benchmark screenshot showed roughly 68.5 tokens per second versus 30.3 before, about 2.2x faster generation on a Qwen3.5 coding variant User-reported 2.2x speedup.
You can read the official announcement, browse Apple's MLX framework, and the HN thread is worth opening because practitioners immediately started comparing quantization variants, cache behavior, and what local inference changes in app design.
MLX backend
Ollama is now powered by MLX on Apple Silicon in preview
Ollama 0.19 preview release integrates Apple's MLX framework for faster performance on Apple Silicon Macs, leveraging unified memory for speedups in prefill (1810 tokens/s vs 1154) and decode on M5 chips using Qwen3.5-35B-A3B model in NVFP4. Features improved caching for efficiency in coding agents like Claude Code and OpenClaw. Requires >32GB unified memory. Commands provided to launch models.
The core change is simple: Ollama on Apple Silicon now runs on top of MLX, Apple's array framework for machine learning on Apple Silicon, instead of its previous path through llama.cpp-style plumbing. Ollama says that lets it use unified memory more directly, and on M5, M5 Pro, and M5 Max it also taps the new GPU Neural Accelerators for both time to first token and generation speed.
That is a bigger deal for coding agents than for chat demos. Ollama's own examples are Claude Code, Codex, Pi, and OpenClaw, which tells you where it expects the latency win to show up first.
NVFP4 numbers
Ollama's chart compares 0.19 running Qwen3.5-35B-A3B in NVFP4 against 0.18 running Q4_K_M. The posted numbers are 1810 versus 1154 tokens per second for prefill, and 112 versus 58 for decode. The same post says int4 can go higher still, to 1851 prefill and 134 decode, but the main headline benchmark uses NVFP4 for what Ollama calls better production parity with providers already serving that format.
Discussion around Ollama is now powered by MLX on Apple Silicon in preview
Thread discussion highlights: - xmddmx on Benchmark results: On a M4 Pro MacBook Pro with 48GB RAM I did this test... qwen3.5:35b-a3b-q4_K_M 6.6 / 30.0, qwen3.5:35b-a3b-nvfp4 13.2 / 66.5, qwen3.5:35b-a3b-int4 59.4 / 84.4 - Yukonv on Caching and workflow: MLX powered inference makes a big difference... using omx.ai that has SSD KV cold caching... no longer have to worry about a session falling out of memory and needing to prefill again. - LuxBennu on Engine comparison: The mlx switch is interesting because ollama was basically shelling out to llama.cpp on mac before, so native mlx should mean better memory handling on apple silicon.
The useful HN replies immediately split the story by quantization. One commenter on a 48GB M4 Pro reported:
q4_K_M: 6.6 prefill, 30.0 decodenvfp4: 13.2 prefill, 66.5 decodeint4: 59.4 prefill, 84.4 decode
Those are not apples-to-apples with Ollama's lab chart, but they point in the same direction: the MLX path and the new quantization options shift the speed ceiling a lot on recent Macs.
Cache reuse
Ollama is now powered by MLX on Apple Silicon in preview
Ollama 0.19 preview release integrates Apple's MLX framework for faster performance on Apple Silicon Macs, leveraging unified memory for speedups in prefill (1810 tokens/s vs 1154) and decode on M5 chips using Qwen3.5-35B-A3B model in NVFP4. Features improved caching for efficiency in coding agents like Claude Code and OpenClaw. Requires >32GB unified memory. Commands provided to launch models.
The less flashy part of the release is probably the stickier one. Ollama says the cache now works in three new ways:
- Reuse across conversations.
- Intelligent checkpoints in the prompt.
- Smarter eviction that keeps shared prefixes around longer.
Ollama is now powered by MLX on Apple Silicon in preview
Relevant if you build or ship local AI features: the discussion covers MLX-based inference on Apple Silicon, observed speedups on M4/M5-class Macs, quantization tradeoffs, and how local caching changes agent and coding-tool UX. It also highlights practical constraints like unified memory, parallel model limits, and model-selection choices for dev machines.
That matches the most practical comment in the discussion thread, which focused on KV cold caching and no longer needing to reprefill a session after it falls out of memory. Another commenter pushed the idea further, arguing that on-device inference changes app architecture because the system starts behaving more like a local state machine than a remote request pipeline.
Memory floor and model scope
Ollama is now powered by MLX on Apple Silicon in preview
Ollama 0.19 preview release integrates Apple's MLX framework for faster performance on Apple Silicon Macs, leveraging unified memory for speedups in prefill (1810 tokens/s vs 1154) and decode on M5 chips using Qwen3.5-35B-A3B model in NVFP4. Features improved caching for efficiency in coding agents like Claude Code and OpenClaw. Requires >32GB unified memory. Commands provided to launch models.
The preview is not a blanket acceleration layer for every model in Ollama. The post says the new release accelerates the new Qwen3.5-35B-A3B model first, with sampling tuned for coding tasks, and asks for more than 32GB of unified memory.
Ollama also says broader architecture support is still in progress, and that an easier import path for fine-tuned custom models is coming later. For now, the preview looks less like a universal Mac speedup and more like a very fast lane for one large coding model on memory-rich Apple laptops and desktops.