Qwen 3.7 Max users report 5-minute cache creation, $43 vibe-coding bills, and uneven task quality
A day after Qwen 3.7 Max launched, users posted both standout benchmark wins and rough real-work reports, including 5-minute cache creation and $43 in 15 minutes of vibe coding. That matters because teams evaluating coding agents are seeing a gap between leaderboard strength and per-task reliability.
TL;DR
- Alibaba positioned Qwen 3.7 Max as its new flagship for coding agents, MCP-heavy productivity work, and long autonomous runs, with API access in Alibaba's launch post and product links surfaced by Alibaba_Qwen's launch thread.
- The benchmark story is real: ArtificialAnlys put the model at 56.6 on the Artificial Analysis Intelligence Index, up from 51.8, while bridgemindai's SWE-Bench Pro post claimed a category win over several Chinese rivals and Claude Opus 4.6.
- The first hands-on reports were rougher than the charts. In bridgemindai's workflow review, a 15-minute coding session cost $43 and still returned 15 errors, while teortaxesTex's cache complaint called out a quoted five-minute cache creation step.
- The pricing story got messy fast: ZhihuFrontier's translated review said token usage rose about 50 percent while price dropped to 60 percent of the previous level, and teortaxesTex's follow-up noted a later 50 percent API discount.
- Qwen's more interesting technical claim is not the leaderboard jump but the harness angle. Alibaba_Qwen's cross-harness post said the model generalized across Claude Code, OpenClaw, Qwen Code, and custom stacks, while ZhihuFrontier's second article excerpt framed the broader fight as model plus harness, not model alone.
You can read Alibaba's launch post, skim the Artificial Analysis model page, and try the model through Qwen Studio, OpenRouter, or Vercel AI Gateway. OpenRouter also published an explicit caching guide for Qwen models, which is suddenly relevant given the day-one cache complaints.
Benchmarks
Alibaba's own framing was broad: strong coding-agent scores, stronger general-purpose agent performance, and a 35-hour autonomous kernel optimization run with 1,158 tool calls, per Alibaba_Qwen's launch thread and Alibaba_Qwen's kernel run post. Artificial Analysis gave the more compact outside summary: 56.6 on the Intelligence Index, up 4.8 points from Qwen3.6 Max Preview, with gains concentrated in scientific reasoning, agentic capability, and coding according to ArtificialAnlys.
A few concrete numbers stood out:
- Intelligence Index: 51.8 to 56.6, per ArtificialAnlys.
- Context window: 256K to 1M, also per ArtificialAnlys.
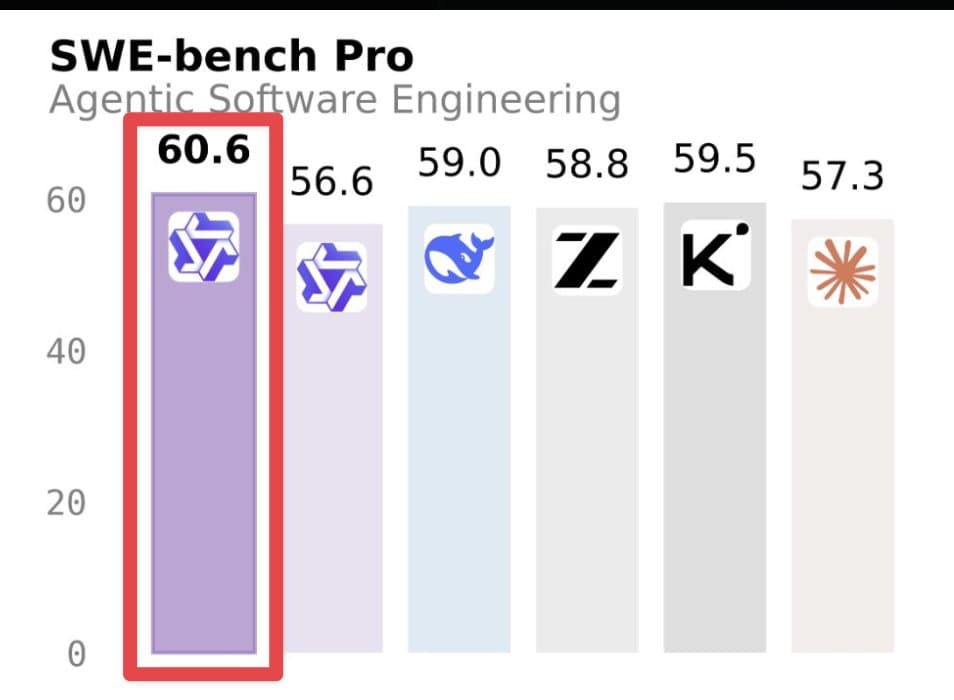
- SWE-Bench Pro: 60.6, which bridgemindai described as No. 1 overall.
- Extended NYT Connections: 82.2 to 89.8, per LechMazur's benchmark note.
- CritPt: a nearly 4x jump over the last generation, according to teortaxesTex's CritPt post.
The catch is in the sub-metrics. ArtificialAnlys said part of the Intelligence Index gain came from abstaining more on AA-Omniscience: accuracy fell from 37.7 percent to 30.1 percent while hallucination rate dropped from 44.2 percent to 22.9 percent.
Friction
The fastest shift in the conversation was from "best Chinese model" to "how expensive is a real task." bridgemindai's workflow review said the model looked excellent on paper, then burned $43 in 15 minutes of vibe coding and still produced 15 errors on one task.
That lined up with the softer skepticism around the launch. sbmaruf's reply said they were "totally disappointed" after using it, while teortaxesTex's cache complaint argued that a quoted "cache creation (5 min)" step made the long-horizon pitch hard to swallow.
The split is useful because it is not benchmark denial. bridgemindai's review explicitly said the benchmark scores were legit, then argued the cost per completed task was the problem. That is a much narrower and more engineer-relevant complaint.
Token economics
The most detailed independent review in the evidence pool, ZhihuFrontier's translated review, said Qwen 3.7 Max improved reasoning by more than 30 percent versus Qwen3.6-Max-Preview, but did it with average token use around 44K, roughly 50 percent higher than the prior generation.
That review described the pricing math this way:
- Token usage up about 50 percent.
- Price down to about 60 percent of the prior level.
- Overall task cost roughly flat, with faster TPS and better usability.
Artificial Analysis reached a similar conclusion from a different angle. ArtificialAnlys said Qwen3.7 Max consumed 96.7 million output tokens to run the Intelligence Index, about 31 percent more than Qwen3.6 Max Preview's 73.9 million.
The day-one user reports suggest flat benchmark-era economics do not automatically translate to flat workflow cost. bridgemindai's workflow review described the model as cheaper per token but more expensive per task, and teortaxesTex's follow-up noted that the API then got a 50 percent discount.
Harness claims
Alibaba's most ambitious claim was that Qwen 3.7 Max learned agentic behavior that transfers across scaffolds. In Alibaba_Qwen's cross-harness post, the company said results held across QwenClawBench and CoWorkBench regardless of evaluation harness, naming Claude Code, OpenClaw, Qwen Code, and custom stacks in the broader launch thread.
That is why kimmonismus focused less on the 35-hour kernel demo and more on the line about agentic capabilities generalizing from diverse training environments. If that claim holds up, the story is about training distribution, not a single flashy run.
The rollout also matched the scaffold-agnostic pitch. By the end of the first day, Qwen 3.7 Max had shown up on Vercel AI Gateway, OpenRouter, Venice, and Kilo, with those launches reflected in vercel_dev, OpenRouter, AskVenice, and kilocode.
Prompt-language gotcha
One of the stranger details came from ZhihuFrontier's translated review, which said Qwen's official blog recommends an extra system prompt during inference. Without it, the reviewer said, the model may reason in Chinese; with it, the chain of thought shifts to English.
That reviewer tied the language choice to measurable performance differences in coding, geometry, and spatial tasks. It is an unusually concrete reminder that part of Qwen 3.7 Max's published performance depends on prompt setup, not just the base model.
The same review also said the model becomes noticeably shakier around 100K-context coding sessions by round three, when it starts forgetting early constraints or making simpler errors. That is a different failure mode from the five-minute cache complaint, and a more specific one.