Qwen3.7 Max launches with 1M context, 35-hour autonomy, and 56.6 AA Index
Alibaba launched Qwen3.7 Max as its new flagship agent model with 1M context, stronger coding and reasoning scores, and cross-harness benchmarks. OpenRouter, Together, AI Gateway, and Kilo support it on day one, making it ready for immediate deployment.
TL;DR
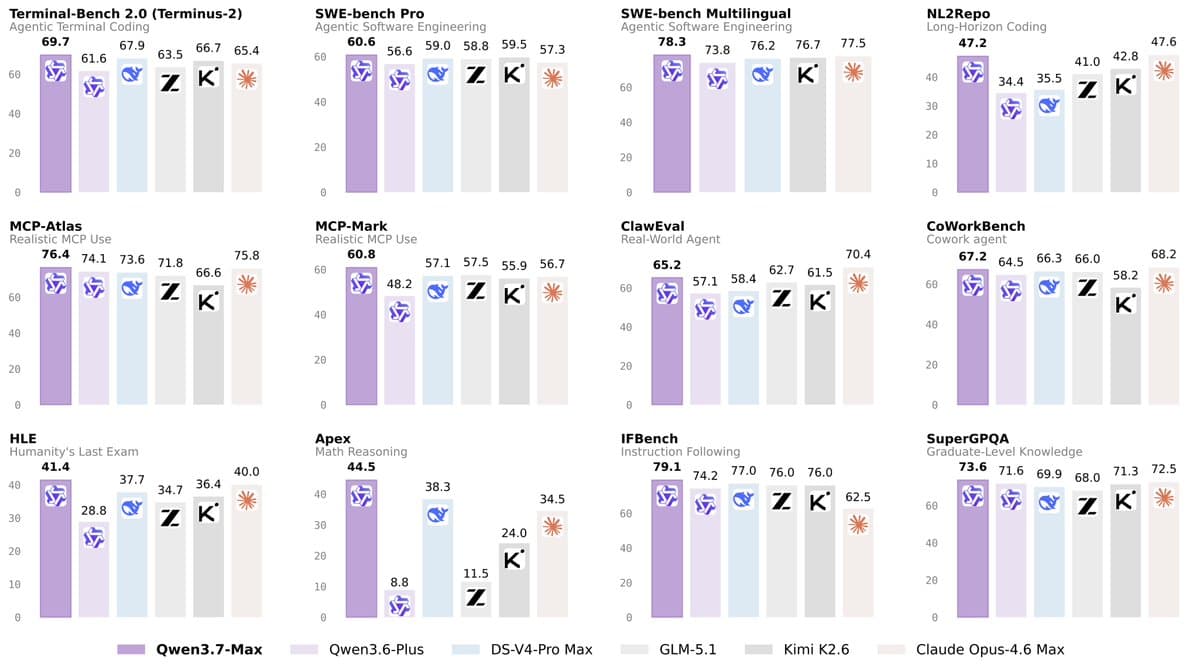
- Alibaba positioned Qwen3.7-Max as its new flagship for agentic work, with a 1M token context window, coding and office-task focus, and support for long autonomous runs, according to Alibaba_Qwen's launch post and ArtificialAnlys' model breakdown.
- The strongest third-party number in the evidence pool is 56.6 on the Artificial Analysis Intelligence Index, which ArtificialAnlys says is 4.8 points above Qwen3.6 Max Preview and near the current frontier cluster.
- Alibaba's core technical claim is not just raw benchmark gain, but generalization across training environments and harnesses, as Alibaba_Qwen's agent-scaling post and Alibaba_Qwen's cross-harness note frame it.
- The headline demo is a 35-hour autonomous kernel-optimization run with 1,158 tool calls and a reported 10.0x geometric-mean speedup over a Triton reference, per Alibaba_Qwen's self-evolving post.
- Day-one distribution moved fast: vercel_dev's AI Gateway announcement, OpenRouter's listing, kilocode's Kilo post, togethercompute's launch post, and AskVenice's Venice rollout all put Qwen3.7-Max on external surfaces within a day.
You can read the official blog post, check the Model Studio docs, and compare the launch framing against the Artificial Analysis model page. The interesting bits are pretty concrete: Alibaba is arguing that agent skill transfers across environments, OpenRouter is already advertising explicit prompt caching, and the ecosystem rollout hit Vercel AI Gateway, OpenRouter, and Venice immediately.
What shipped
Alibaba's launch pitch breaks the model into four concrete jobs: coding agent, office assistant, long-horizon autonomous worker, and scaffold-agnostic base model.
- Context window: 1M tokens, up from 256K on Qwen3.6 Max Preview, according to ArtificialAnlys' model breakdown.
- Primary use cases: coding, office and productivity tasks, MCP-backed workflows, and multi-agent orchestration, per Alibaba_Qwen's launch post.
- Modalities: text in and text out only, according to ArtificialAnlys' model breakdown.
- Availability: Alibaba Model Studio API and Qwen Studio on day one, per Alibaba_Qwen's launch post.
- Positioning: proprietary flagship, while much of the rest of the Qwen line remains open-weight, according to ArtificialAnlys' model breakdown.
Benchmarks
The cleanest outside read comes from Artificial Analysis. ArtificialAnlys scored Qwen3.7-Max at 56.6 on its Intelligence Index, up from 51.8 for Qwen3.6 Max Preview.
The gains it called out are narrow rather than universal:
- CritPt: 3.7% to 13.4%, +9.7 points, per ArtificialAnlys' model breakdown.
- HLE: 28.9% to 38.1%, +9.2 points, per ArtificialAnlys' model breakdown.
- TerminalBench Hard: 43.9% to 50.8%, +6.9 points, per ArtificialAnlys' model breakdown.
- GDPval-AA: 1504 to 1546 Elo, +42 Elo, per ArtificialAnlys' model breakdown.
The caveat is more interesting than the topline. ArtificialAnlys says part of the AA Index gain comes from abstaining more often on AA-Omniscience: accuracy fell from 37.7% to 30.1%, while hallucination rate dropped from 44.2% to 22.9%.
Agent training
Alibaba is making an explicit training claim here. Alibaba_Qwen's agent-scaling post says Qwen3.7 extends Qwen3.5's environment-scaling approach by increasing the quality and diversity of agent training environments, with the thesis that agentic capabilities generalize the way language capabilities generalize from diverse text.
A second claim sits on top of that: Alibaba_Qwen's cross-harness note says the model stays strong across QwenClawBench and CoWorkBench regardless of which harness is used at eval time. That is a direct attempt to answer the usual suspicion around agent benchmarks, namely that a model learned one scaffold too well.
Kernel run
The launch's showpiece is not a chatbot demo. It is a long autonomous optimization loop on an attention kernel.
According to Alibaba_Qwen's self-evolving post, the run lasted about 35 hours, covered 432 kernel evaluations, used 1,158 tool calls, and produced a reported 10.0x geometric-mean speedup over a Triton reference across multiple workloads. kimmonismus usefully narrows the interpretation: the result is a model grinding through compile, profile, and rewrite cycles on one bounded target, not a general self-improvement jump.
That narrower framing still leaves a striking number. Alibaba_Qwen's launch post had already turned long-horizon autonomy into the headline, and togethercompute's launch post echoed the same run as evidence that the model can stay coherent over hours rather than minutes.
Where it shows up
This rollout was not limited to Alibaba's own surfaces.
- vercel_dev's AI Gateway announcement listed the model as
alibaba/qwen3.7-maxon Vercel AI Gateway. - OpenRouter's listing put it on OpenRouter the same day, with OpenRouter's prompt-caching guide linked alongside the launch thread.
- kilocode's Kilo post highlighted the 1M context window and 1,000-plus tool-call pitch inside Kilo.
- togethercompute's launch post added Qwen3.7-Max to Together Serverless Inference for production agent workloads.
- AskVenice's Venice rollout added it to Venice with function calling and prompt caching in the product description.
Access and pricing
Alibaba made the official access story simple: Qwen Studio for direct use, Model Studio for API access, and the official blog post as the main technical summary.
Pricing was less tidy in the early evidence. ArtificialAnlys' model breakdown said pricing was still unannounced at launch time, while scaling01's pricing post claimed the live rate looked like $2.5 per 1M input tokens and $7.5 per 1M output tokens. The same ArtificialAnlys' model breakdown also noted that its eval run consumed 96.7M output tokens, about 31% more than Qwen3.6 Max Preview.
One more implementation detail surfaced outside the official thread. OpenRouter's listing explicitly called out prompt caching for repeated context, and OpenRouter's prompt-caching guide linked to the provider-specific caching docs. That matters because a 1M-context model is not just about fitting more tokens, it is also about whether the serving stack exposes cost controls for repeated long prompts.