Unsloth benchmarks Qwen3.6-35B-A3B GGUF quants at 20-40 tok/s on local rigs
Unsloth published GGUF quant benchmarks for Qwen3.6-35B-A3B while practitioners shared local setup guides and long-context agent runs on Apple silicon and high-RAM desktops. The sparse 35B model is becoming a credible local coding-agent option, but speed and reasoning quality still vary by quant and offload strategy.
TL;DR
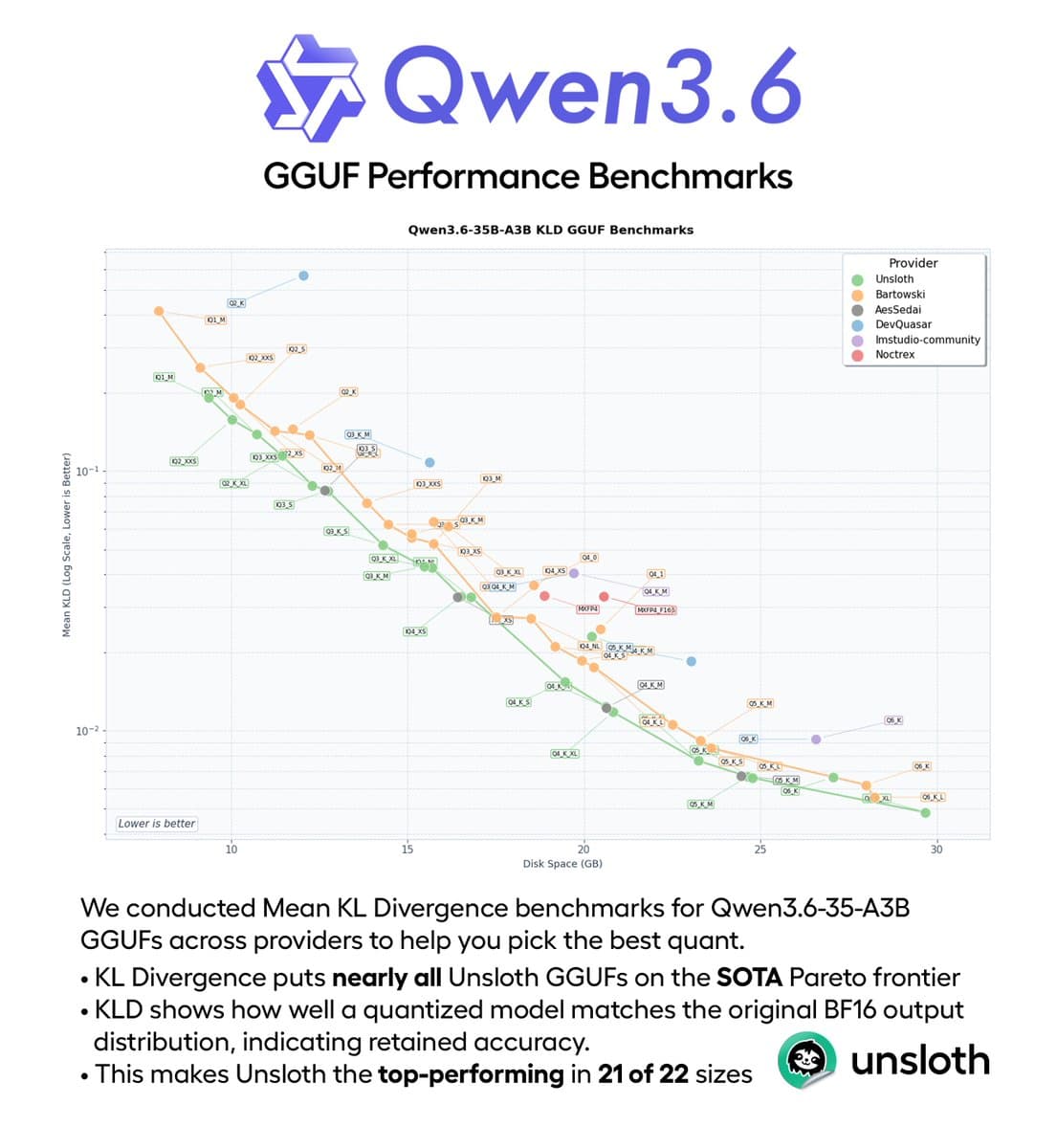
- UnslothAI's GGUF benchmark post said its Qwen3.6-35B-A3B builds ranked first on mean KL divergence in 21 of 22 tested sizes, with danielhanchen's follow-up adding that most of those quants also sat on the Pareto frontier for KLD versus disk space.
- UnslothAI's local-run guide card and the linked Unsloth docs both put 4-bit local runs around 22 to 23 GB RAM, while 3-bit drops to roughly 17 GB and BF16 jumps to about 70 GB.
- According to fresh Hacker News discussion, early users are getting roughly 40 tok/s on an M3 Ultra, stable tool use past 100k tokens, and around 20 tok/s from low-bit offload setups on big-memory desktops.
- UnslothAI's repo bug-hunt demo and vicnaum's MLX benchmark card both point to the same pitch: a sparse 35B model that still acts like an agent locally, with multi-step tool use on one side and 51.1 tok/s decode plus 5/5 Terminal-Bench on the other.
- The caveat is already visible in a LocalLLaMA slowdown report and the HN discussion roundup: quant quality, offload strategy, and whether thinking is enabled can swing both speed and perceived intelligence.
Qwen's own release entry frames this as the first open-weight Qwen3.6 variant, with 35B total parameters and about 3B active per token. You can cross-check the local-running numbers in Unsloth's guide, skim the main HN thread, and, if you want the funniest side quest of the launch, Simon Willison's pelican benchmark writeup had the laptop GGUF beating Opus 4.7 at drawing birds on bicycles.
Qwen3.6-35B-A3B shipped as a sparse local-friendly coding model
Qwen3.6-35B-A3B
Qwen.ai blog post announcing the release of Qwen3.6-35B-A3B, a 35B parameter MoE model (3B active) showcasing superior perception and multimodal reasoning capabilities beyond expectations for its size. Available on Hugging Face as of April 15, 2026.
The official Qwen model card describes Qwen3.6-35B-A3B as a 35B MoE with about 3B active parameters, positioned for agentic coding and multimodal reasoning. UnslothAI's guide card adds the practical part engineers care about: 256K context, 201 languages, and a quant table that starts at 17 GB for 3-bit, 23 GB for 4-bit, 30 GB for 6-bit, 38 GB for 8-bit, and about 70 GB for BF16.
The linked Unsloth documentation also says its Qwen3.6 GGUFs use Dynamic 2.0 quantization, add developer role support for agentic coding tools like Codex and OpenCode, and improve nested-object tool parsing. That makes this wave more than a model upload, it is also a same-day packaging push for local agent harnesses.
Unsloth's KLD charts made GGUF selection much less guessy
Unsloth benchmarked Qwen3.6-35B-A3B GGUFs across providers using mean KL divergence, then published the scatterplot instead of a vague "best quant" claim. The two concrete findings from UnslothAI and danielhanchen were:
- Unsloth ranked first in 21 of 22 tested sizes on mean KLD.
- Most Unsloth quants sat on the Pareto frontier for mean, 90%, and 99.9% KLD versus disk space.
MXFP4_MOEshowed up as an outlier across providers.- More small quants were still coming.
That is useful because Qwen3.6's local story is not one model, it is a menu of quants. The official GGUF repository already exposes that spread, from UD-IQ1 and UD-IQ2 variants up through Q8 and BF16 files.
Local agent runs are the real reason this model caught on
Fresh discussion on Qwen3.6-35B-A3B: Agentic coding power, now open to all
Today’s new signal is mostly practical validation from users trying the model in live agentic workflows. One commenter reports running Qwen3.6-35B-A3B BF16 with omlx on an M3 Ultra Mac Studio at roughly 40 tokens/sec and says tool use stayed stable even over 100k tokens, calling it their smoothest local agent session so far. Another says it is the most capable local model they have tried at this size, especially for breaking tasks into steps and asking clarifying questions. The other fresh theme is real-world deployability: people ask what hardware it needs, whether it is available through aggregators, and how it compares with Opus-class models on a MacBook M3 Max. One reply suggests a low-bit quant with partial offload can fit on high-end consumer rigs and still run around 20 tps, while another points to quantization/fork issues as a bottleneck for local model users. There is also renewed skepticism that benchmark gains map to agentic usefulness, with a few commenters calling out “benchmaxxing.”
The strongest signal in the reaction was not a launch chart. It was people trying to use the model as an actual coding agent.
UnslothAI's demo claimed a 2-bit GGUF completed a repo bug hunt with evidence, repro steps, fixes, tests, a PR writeup, 30-plus tool calls, 20 site searches, and Python execution on 13 GB RAM. Separately, fresh HN discussion summarized a user report of BF16 Qwen3.6-35B-A3B on an M3 Ultra Mac Studio at roughly 40 tok/s, with tool use still holding together past 100k tokens.
The practitioner comments collected in the HN discussion roundup cluster around three behaviors:
- stable tool use in longer sessions
- better task decomposition than earlier local models
- more clarification questions instead of blindly charging ahead
That is Christmas-come-early material for local agent nerds, because those are workflow traits that benchmark charts usually blur away.
MLX numbers show the speed-quality trade is quant-dependent
Vicnaum's MLX run on Qwen3.6 Q3 is one of the cleaner early benchmark cards because it breaks out speed, coding, and recall separately. According to vicnaum's overnight results, Qwen3.6 Q3 MLX posted:
- 51.1 tok/s sustained decode
- 5/5 on Terminal-Bench, tied with REAP 21B
- 92% on HumanEval, tied with REAP in the first card
- 79% knowledge average, 1 point behind REAP
- 88.5% combined tool calling, 5.5 points behind REAP
Vicnaum's follow-up then reran with thinking disabled and got the sharper trade: Qwen stayed close on total quality, lost 3 points overall, but finished in 64.1 minutes versus 87.5 minutes for REAP, with 51.1 tok/s decode versus 29.8 tok/s.
That is a good reminder that "Qwen3.6 speed" is really shorthand for a stack of choices: quant level, backend, thinking mode, and what part of the workload you care about.
Hardware fit ranges from 13 GB demos to 120 GB offload rigs
Qwen3.6-35B-A3B GGUF from Unsloth is quite a bit slower?
0 comments
The memory floor got a lot of attention because it changes who can even try the model. UnslothAI's 23 GB RAM note said 4-bit runs fit on a Mac with 23 GB RAM, while UnslothAI's 2-bit bug-hunt demo pushed the headline lower to 13 GB RAM for a 2-bit agent run.
The ceiling is less cute. the HN discussion roundup included a report that UD_IQ2_M needed around 120 GB of RAM for one offloaded setup, albeit at about 20 tok/s. Meanwhile the LocalLLaMA slowdown report described a CPU-only Debian box where similarly sized Unsloth quants ran about 30% slower than another creator's files, with noticeably longer follow-up delays.
So the rough hardware map now looks like this:
- 13 GB class: 2-bit demos, with heavy quality tradeoffs and very specific tool-heavy showcases
- 22 to 23 GB class: the mainstream 4-bit laptop story from Unsloth docs
- 100 GB-plus class: low-bit offload experiments chasing better quality or longer contexts
Bench skepticism showed up almost immediately
Discussion around Qwen3.6-35B-A3B: Agentic coding power, now open to all
Thread discussion highlights: - qazplm17 on local agentic performance: "~40tk/s on a M3 Ultra Mac Studio" ... "the tool use consistency has been held up well" ... "This is by far my smoothest agentic session using a local model" - altruios on agentic capability: "This one is noticeably better as an agent" ... "breaking down tasks into small actionable steps" ... "asks for clarification" - Tamitami2000 on hardware and quantization: "UD_IQ2_M quants are quite strong" ... "around 120GB of RAM needed" ... "runs this quant offloaded at 20 tps"
The reaction was not pure victory-lap posting. the HN discussion roundup captured a familiar complaint from practitioners who said benchmark gains did not fully match their own sense of model quality, calling it "benchmaxxing."
That skepticism mattered more here because Qwen3.6 was getting two very different kinds of early praise. One bucket was formalized, with KLD plots and small benchmark tables. The other bucket was weird and practical, like simonw's flamingo follow-up and the linked pelican benchmark writeup, where a 20.9 GB laptop quant beat Opus 4.7 on SVG bird prompts.
Taken together, the early picture is less "the benchmark winner shipped" and more "the local coding-agent crowd found another model worth actually driving."