Qwen3.6-35B-A3B releases Apache 2.0 sparse MoE with 3B active params
Alibaba open-sourced Qwen3.6-35B-A3B, a 35B multimodal sparse MoE with only 3B active parameters under Apache 2.0. Same-day support from vLLM, Ollama, SGLang, and GGUF builders makes it immediately usable for local and production coding workloads.
TL;DR
- Alibaba Qwen's launch post introduced Qwen3.6-35B-A3B as an Apache 2.0 open-weight sparse MoE with 35B total parameters, 3B active parameters, native multimodality, and thinking plus non-thinking modes.
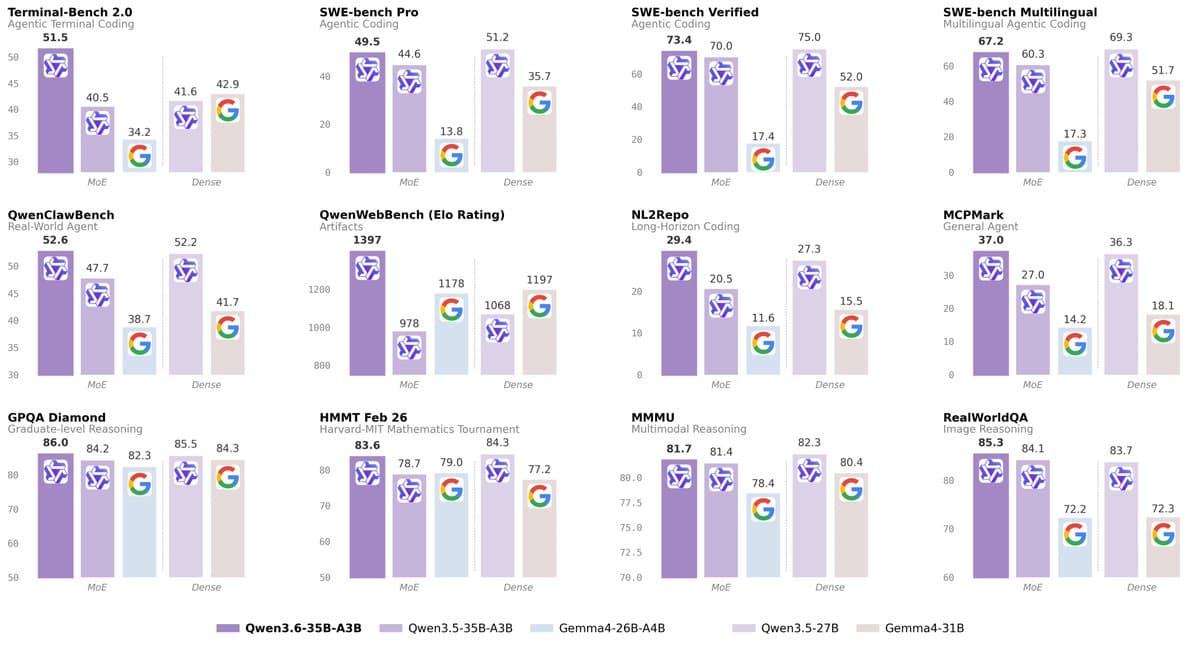
- According to Qwen's benchmark card and Official release notes, the pitch is agentic coding efficiency: 51.5 on Terminal-Bench 2.0, 73.4 on SWE-bench Verified, and 29.4 on NL2Repo.
- Qwen's VLM results positioned the model near Claude Sonnet 4.5 on several vision-language tasks, including 85.3 on RealWorldQA and 92.0 on RefCOCO.
- The launch landed with immediate serving support: vLLM said v0.19+ works day 0, SGLang published a launch command, and Ollama added a pull-and-run model page with Claude Code and OpenClaw launch hooks.
- Local inference is part of the story, not an afterthought: Unsloth published GGUFs for roughly 23 GB RAM, while the main HN thread quickly filled with LM Studio, llama.cpp, Ollama, and Continue reports.
You can read the official release, grab the weights on Hugging Face, and check the Ollama library page or Unsloth's local run guide. The funnier early datapoint came from Simon Willison's pelican benchmark, where a laptop-hosted Qwen quant beat Opus 4.7 on absurd SVG bird generation.
What shipped
The official package is narrow and practical. Official release notes describe Qwen3.6-35B-A3B as the first open-weight checkpoint in the Qwen3.6 line, released in BF16, with the same base architecture as Qwen3.5 and post-training focused on agentic coding plus "thinking preservation."
Qwen3.6-35B-A3B Release
Announces the release of Qwen3.6-35B-A3B, the first open-weight model in the Qwen3.6 series. It is a post-trained multimodal causal language model with 35B total parameters and 3B activated per token, available in BF16 on Hugging Face. Key improvements include agentic coding (frontend workflows, repository-level reasoning), thinking preservation to retain reasoning context, and compatibility with Transformers, vLLM, SGLang, etc. Built on community feedback for stability and utility.
The architecture details surfaced consistently across the launch materials and ecosystem posts:
- 35B total parameters, 3B active per token Qwen launch
- sparse MoE under Apache 2.0 Qwen launch
- same hybrid architecture as Qwen3.5, according to vLLM and SGLang
- 262K native context, extensible to 1M, according to SGLang
- native multimodality, with text and image support already exposed on the Ollama model page
The unusually good part for infra teams is how little translation work the launch seems to require. vLLM's day-0 note explicitly said serving teams can upgrade in place because the architecture matches Qwen3.5.
Agentic coding scores
Qwen's own chart is blunt about where the training went. The biggest jumps are in coding-agent and repo-scale tasks, not in broad knowledge benchmarks.
According to Qwen's chart and the fuller table in the benchmark breakdown, the headline deltas versus Qwen3.5-35B-A3B are:
- Terminal-Bench 2.0: 40.5 to 51.5
- SWE-bench Verified: 70.0 to 73.4
- SWE-bench Multilingual: 60.3 to 67.2
- NL2Repo: 20.5 to 29.4
- MCPMark: 27.0 to 37.0
- QwenWebBench Elo: 978 to 1397
There is one useful wrinkle in those same tables. Qwen3.6-35B-A3B often beats the older 35B-A3B checkpoint by a wide margin, but it does not uniformly beat dense Qwen3.5-27B. In Qwen's published table, Qwen3.5-27B still leads on SWE-bench Verified, SWE-bench Pro, TAU3-Bench, Tool Decathlon, several knowledge metrics, and some math sets. The release is a specialization story with a stronger coding-agent profile, not a clean sweep.
Multimodal and spatial benchmarks
The second half of the launch is vision. Qwen's multimodal benchmark post compared the open model directly with Claude Sonnet 4.5 and Gemma 4 variants across VQA, OCR, spatial, and video tasks.
On the published numbers, the strongest claims cluster around spatial and document-heavy tasks:
- RealWorldQA: 85.3 for Qwen3.6, 70.3 for Claude Sonnet 4.5, according to Qwen's table
- OmniDocBench1.5: 89.9 for Qwen3.6, 85.8 for Claude Sonnet 4.5, according to the detailed VLM table
- CC-OCR: 81.9 for Qwen3.6, 68.1 for Claude Sonnet 4.5, according to the detailed VLM table
- RefCOCO: 92.0 for Qwen3.6, up from 89.2 for Qwen3.5-35B-A3B, according to Qwen's spatial benchmarks
- ODInW13: 50.8 for Qwen3.6, up from 42.6 for Qwen3.5-35B-A3B, according to Qwen's spatial benchmarks
Qwen's own comparisons are selective, but they are selective in an interesting direction. The open-weight release is being framed less as a chat model with image support, more as a coding model that also handles diagrams, screenshots, OCR, and spatial tasks well enough to matter.
Day-0 deployment stack
The ecosystem moved almost immediately. vLLM published a serve command with --reasoning-parser qwen3, SGLang added --tool-call-parser qwen3_coder plus speculative decoding flags, and Ollama exposed one-command local usage plus app launchers.
The shipping surfaces that showed up on day 0:
- vLLM v0.19+, with thinking, tool calling, MTP speculative decoding, and text-only mode, according to vLLM
- SGLang, with reasoning parser support, tool-call parsing, and EAGLE speculative decoding, according to SGLang
- Ollama, with
ollama run qwen3.6and launch integrations for Claude Code, Codex, OpenCode, and OpenClaw, according to Ollama - Unsloth GGUFs, which Unsloth and Unsloth's docs pitched as runnable on roughly 22 to 23 GB RAM
That combination makes the release feel less like a model card drop and more like a pre-wired open stack. By the time the benchmark screenshots were circulating, the serving recipes were already attached.
Local hardware signal
The fastest reality check came from people running quants, not from benchmark threads. The main HN discussion quickly turned into a pile of LM Studio, llama.cpp, Ollama, and Continue reports, including complaints about fill-in-the-middle artifacts in VS Code and separate speed anecdotes from laptop and 3060 users.
A few concrete datapoints stood out:
- Unsloth's guide card listed 17 GB for 3-bit, 23 GB for 4-bit, 30 GB for 6-bit, and 38 GB for 8-bit inference
- HN commenters reported running the 20.9 GB GGUF in LM Studio, 22.3 GB
q4_K_Mbuilds in Ollama, and llama.cpp setups with 150K context plus quantized KV cache - one reposted benchmark claimed 180 tok/s generation on an RTX 4090
- another reposted run claimed a 2-bit variant could do a repo bug hunt in 13 GB RAM
- an MLX benchmark run measured 51.1 tok/s sustained decode on an M4 Air and tied REAP 21B on a small Terminal-Bench slice, while trailing on MMLU and tool-calling accuracy
The charming datapoint is still Simon Willison's write-up. A 21 GB local quant beating Opus 4.7 on pelicans and flamingos does not settle anything important, but it does capture the vibe of this release: the open model people can actually run is getting weirdly capable.