Software product named Vals AI.
Recent stories
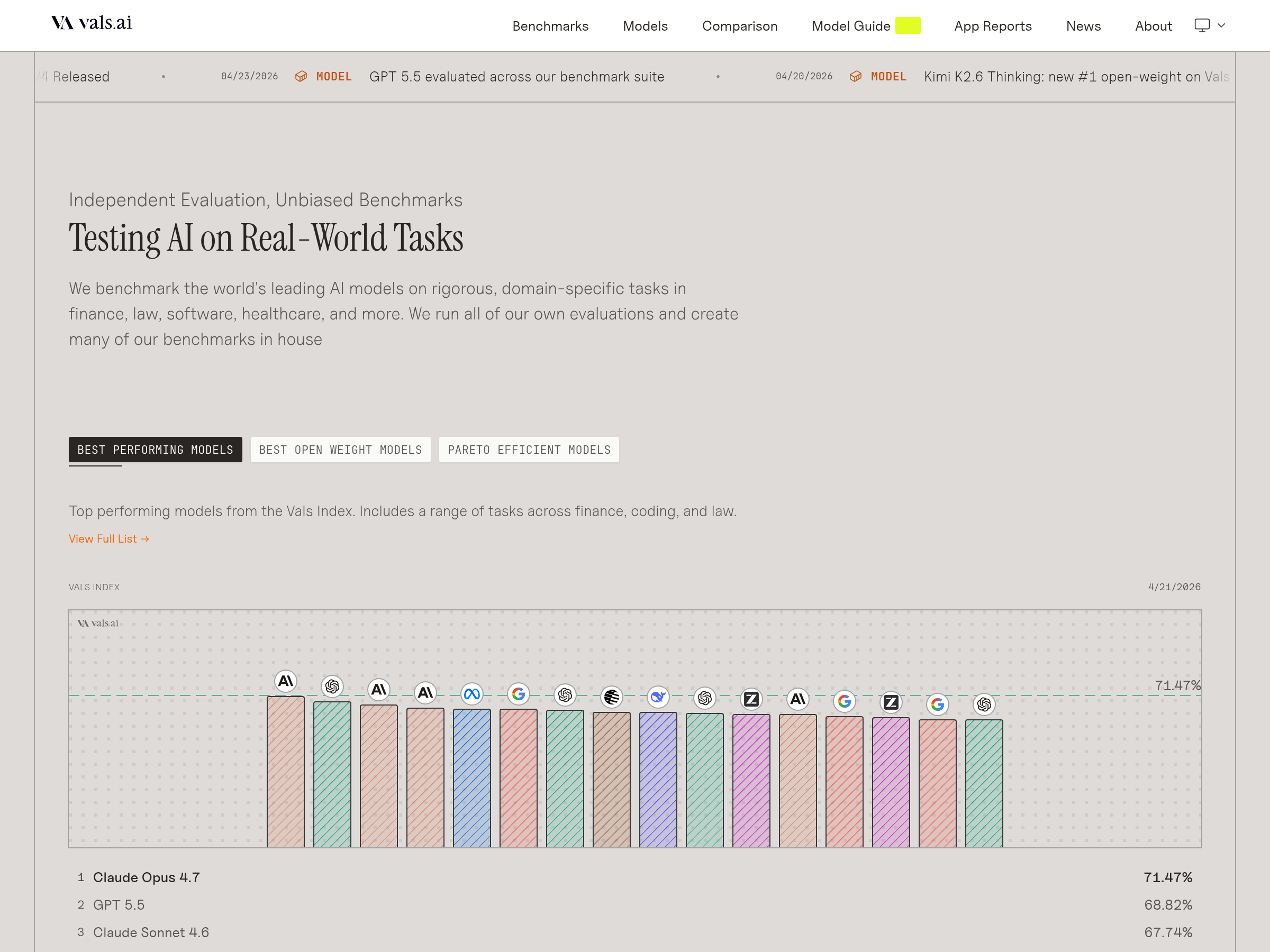
Vals AI launched SkillsBench, a public benchmark for measuring how reusable skills change coding-agent performance, and reported average accuracy rising from 35.5% to 52.5%. The results matter because they suggest some workflows can move to cheaper models when task-specific skills are available.
Two days after Qwen 3.7 Plus launched, Hyper, OpenCode, Kilo, and Vals shipped support or rankings around the 1M-context multimodal model. The rapid pickup shows Alibaba’s new model landing quickly in coding-agent tools and public eval stacks outside its own platform.
Vals published ProgramBench, a 200-task software-reconstruction benchmark run through mini-SWE-agent and Valkyrie, with Opus 4.8 becoming the first model to fully solve two tasks. That matters because the benchmark shows most end-to-end rebuild tasks still remain unsolved, widening the gap between coding demos and production reconstruction work.
ValsAI found that undocumented `tool_choice` behavior was skewing Terminal Bench 2 scores when no native tools were used, then reran the evals. The correction lifted GPT-5.5 by 11% to the top slot and showed how much harness settings can move coding-agent results.