Vals AI releases SkillsBench with a 17-point coding-agent gain and MiniMax-M3 at +25.4
Vals AI launched SkillsBench, a public benchmark for measuring how reusable skills change coding-agent performance, and reported average accuracy rising from 35.5% to 52.5%. The results matter because they suggest some workflows can move to cheaper models when task-specific skills are available.
TL;DR
- Vals AI says its new SkillsBench benchmark tests the same coding agents twice, once without reusable skills and once with them, and measures the delta those skills add Vals AI's SkillsBench announcement.
- Across the models Vals tested, average accuracy rose from 35.5% to 52.5%, a 17.0 point gain, according to Vals AI's results thread.
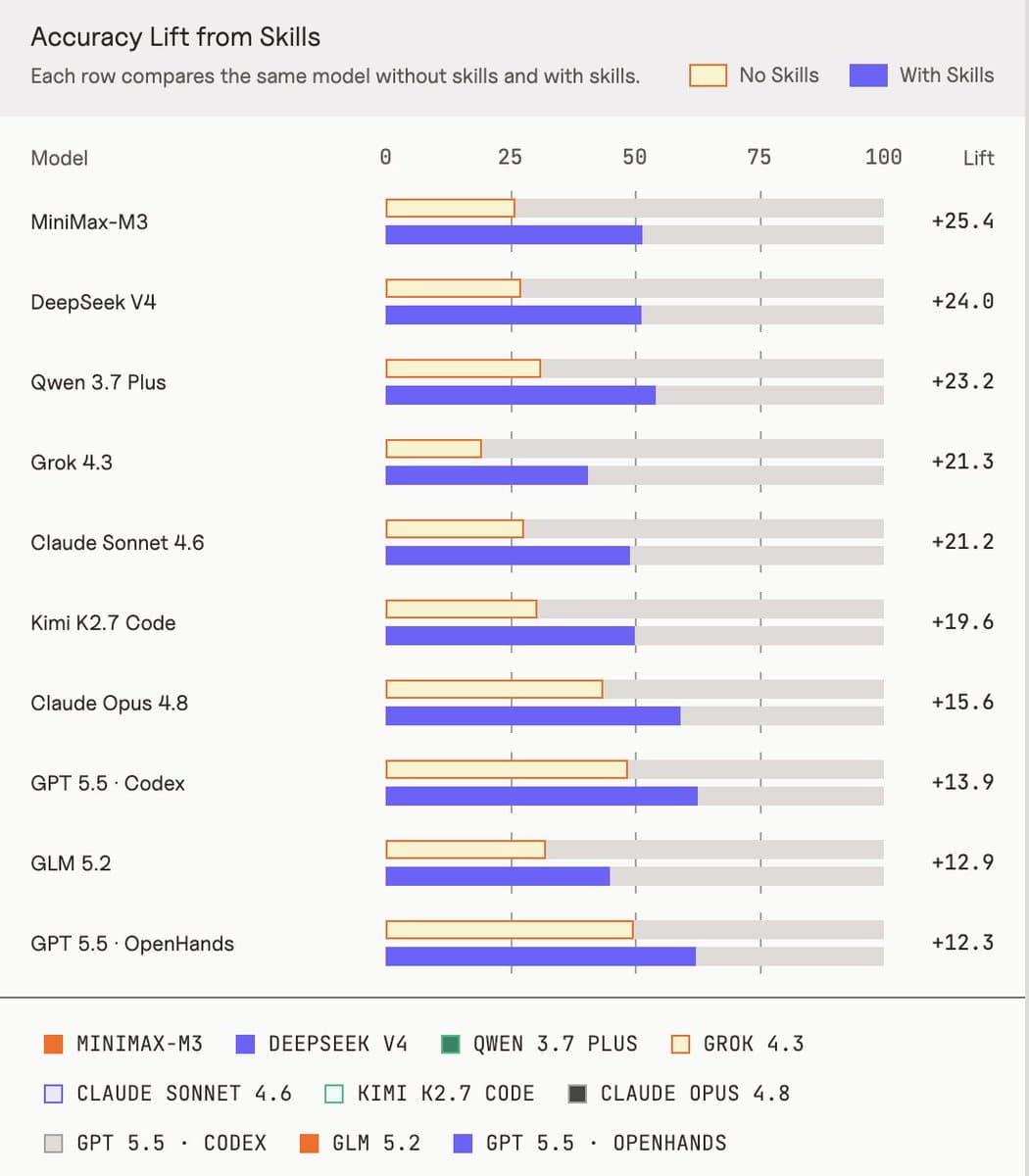
- The biggest jumps came from mid-tier models: Vals AI's ranking post says MiniMax-M3 gained +25.4 points, while Qwen 3.7 Plus reached 54.3% at $0.14 per task.
- Skill usage frequency did not predict the gain: Vals AI's usage analysis says GPT 5.5 referenced skills about 4.8 times per task, while Sonnet 4.6 used them least and still posted one of the largest lifts.
- The benchmark is also the first entry in Vals AI's public Valkyrie registry, where Vals AI's registry post says the tasks and run protocol are open.
You can see the benchmark framing in Vals AI's launch post, the leaderboard and lift chart in teortaxesTex's screenshot, and the open-registry angle in Vals AI's registry post. The oddest detail is that more tool use did not mean better tool use, a pattern Vals called out in its usage thread.
SkillsBench
Vals frames SkillsBench as a narrow question: do coding agents improve when you give them reusable, task-specific skills. Each model-agent pair runs once without skills and once with them, so the benchmark is measuring the lift from the harness addition rather than raw model quality alone.
The first headline number is broad: every tested model improved, and the average score moved from 35.5% to 52.5%.
Mid-pack gains
The ranking twist is that the largest gains came from the middle, not the frontier leaders.
- MiniMax-M3 posted the biggest lift, +25.4 points Vals AI's ranking post.
- Qwen 3.7 Plus moved to third with a 54.3% score and $0.14 cost per task, per Vals AI's ranking post.
- GPT 5.5 still led overall, with 62.6% on Codex and 62.2% on OpenHands, according to Vals AI's results thread.
- In teortaxesTex's commentary, DeepSeek V4 and MiniMax-M3 were the strongest open models once skills were enabled.
Skill usage frequency
Vals says reaching for skills more often did not translate into bigger gains. GPT 5.5 on Codex referenced skills about 4.8 times per task, while Sonnet 4.6 referenced them the least and still showed one of the larger deltas.
That turns skill invocation into a quality question, not just a quantity question, and it is one of the more useful details in the whole release.
Valkyrie registry
Vals says it built the benchmark with Benchflow AI and published it as the first benchmark in Valkyrie's new public registry. The concrete new bit there is openness: Vals says the tasks and run protocol are public, which makes this more than a leaderboard screenshot.