Supertone opens Supertonic with ONNX on-device TTS
Supertone open-sourced Supertonic, a local TTS engine that runs faster than real time on phone CPUs with ONNX models and cross-language runtimes. Voice apps and audiobook workflows can use it to avoid per-character API billing and keep audio generation private.
TL;DR
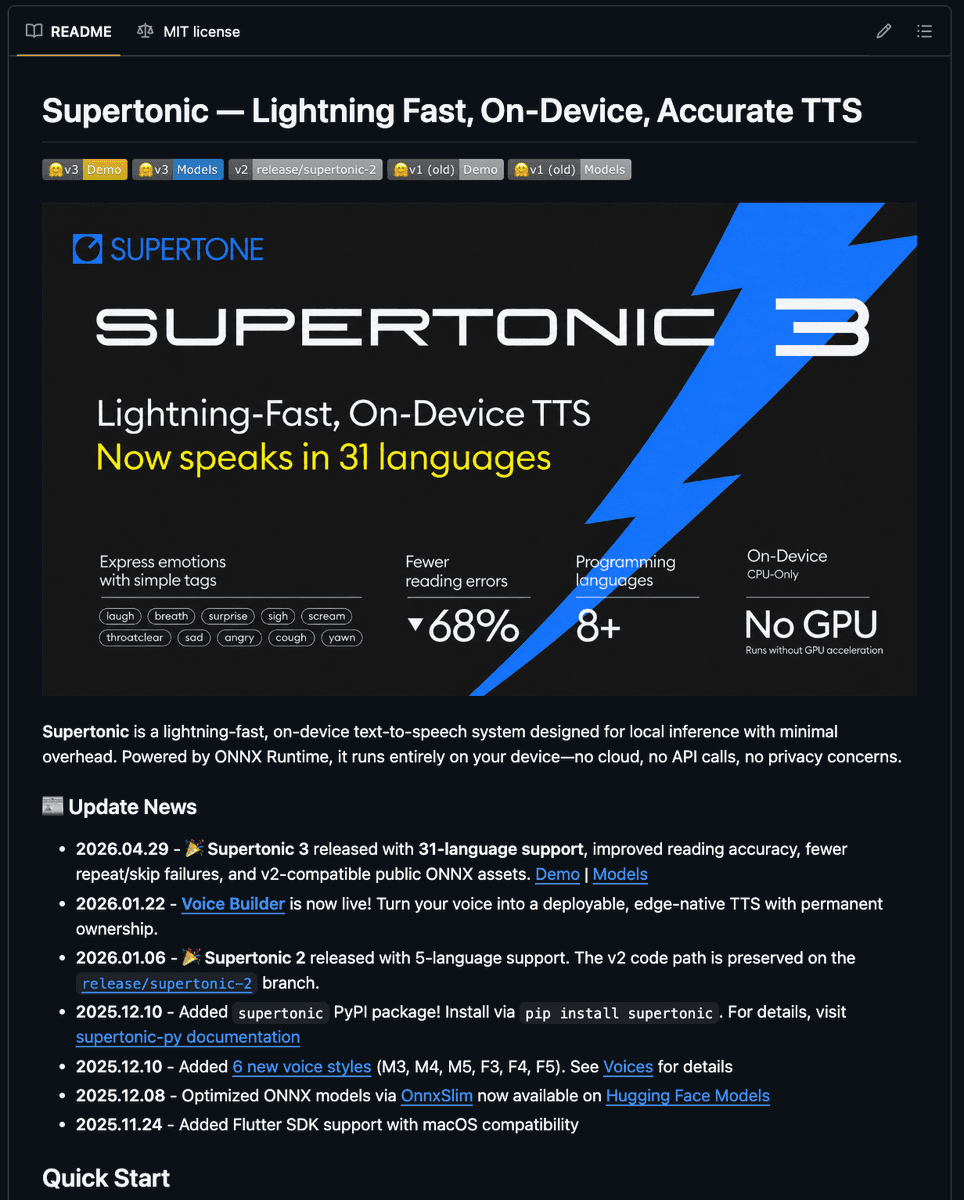
- Supertone has open-sourced Supertonic, an on-device TTS engine that hasantoxr's thread says runs faster than real time on phone CPUs with ONNX models, with the code available in the Supertonic GitHub repo.
- According to hasantoxr's feature list, Supertonic ships example runtimes for Swift, Kotlin, Rust, C++, Python, and JavaScript, which makes it unusually portable for local voice apps.
- The pitch in hasantoxr's post is economic as much as technical: local inference removes per-character API billing, server round-trips, and default cloud handling of user voice data.
- hasantoxr's Audiblez thread shows the adjacent workflow this enables: local tools can already turn EPUBs into M4B audiobooks on consumer hardware, and heyrimsha's reply frames that shift as a way around subscription lock-in.
You can browse the repo, check hasantoxr's summary of the runtime list, and compare it with the Audiblez example where a separate local TTS stack already turns ebooks into audiobooks on a laptop. heyrimsha adds the consumer angle, arguing that local TTS is starting to change how people listen to books by cutting out subscriptions and platform lock-in.
Supertonic
The core claim is simple: a local speech engine that runs in real time on phone CPUs, not a hosted API. In hasantoxr's thread, the package is framed around four concrete properties:
- ONNX models for real-time inference on phone CPUs
- native examples for Swift, Kotlin, Rust, C++, Python, and JavaScript
- zero network calls
- Apache 2.0 licensing with no usage caps
That combination matters because most creative voice workflows still split text generation, synthesis, and delivery across hosted services. Supertonic points in the other direction: ship the voice model with the app, keep synthesis on device, and treat privacy and offline support as defaults, not enterprise add-ons.
Where local TTS gets useful fast
The clearest adjacent use case in the evidence pool is audiobook generation. hasantoxr's Audiblez post describes a tool that converts EPUBs into M4B audiobooks locally, with a GUI, CUDA support, multiple languages, voice selection, and no cloud dependency.
The same post gives two speed anchors for today's local stack:
- Animal Farm in about 5 minutes on a Google Colab T4 GPU
- about 1 hour on an M2 MacBook Pro CPU
Those numbers are for Audiblez, not Supertonic, but they show the category shift. Local speech tools are moving from toy demos to long-form media workflows that people can run on ordinary hardware.
Books, subscriptions, and lock-in
According to heyrimsha's reply, local TTS tools are already changing book consumption by removing subscriptions and platform lock-in. That is a narrower claim than the broader privacy argument in hasantoxr's Supertonic thread, but it lands on a concrete creative outcome: readers can generate and keep their own audiobook files instead of renting access to a catalog.
hasantoxr's pricing comparison makes that trade explicit by stacking subscription, usage-based, and pro narration costs against a local open-source workflow. Supertonic does not arrive with the same end-user packaging as Audiblez, but the release pushes the same idea down the stack: voice generation can be software you ship, not a meter you keep feeding.