Gemini 3.1 Flash TTS launches with Audio Tags, 70+ languages and API preview
Google released Gemini 3.1 Flash TTS with inline Audio Tags, multi-speaker control and 70+ languages, and opened preview access through the Gemini API and AI Studio with rollout to Vertex AI and Google Vids. Independent evals ranked it near the top of current speech leaderboards, but it runs slower and costs more than the leading system.
TL;DR
- Google DeepMind's launch thread says Gemini 3.1 Flash TTS adds inline Audio Tags for vocal style, delivery, and pace, while Official Google's announcement positions it as Google's most controllable TTS model yet.
- Availability is split across surfaces: Google DeepMind's rollout note puts developers on Gemini API and AI Studio preview, enterprise users on Vertex AI preview, and Workspace users on Google Vids, which matches the Gemini API docs.
- Feature-wise, Phil Schmid's breakdown lists 30 prebuilt voices, up to two speakers, inline non-verbal cues like
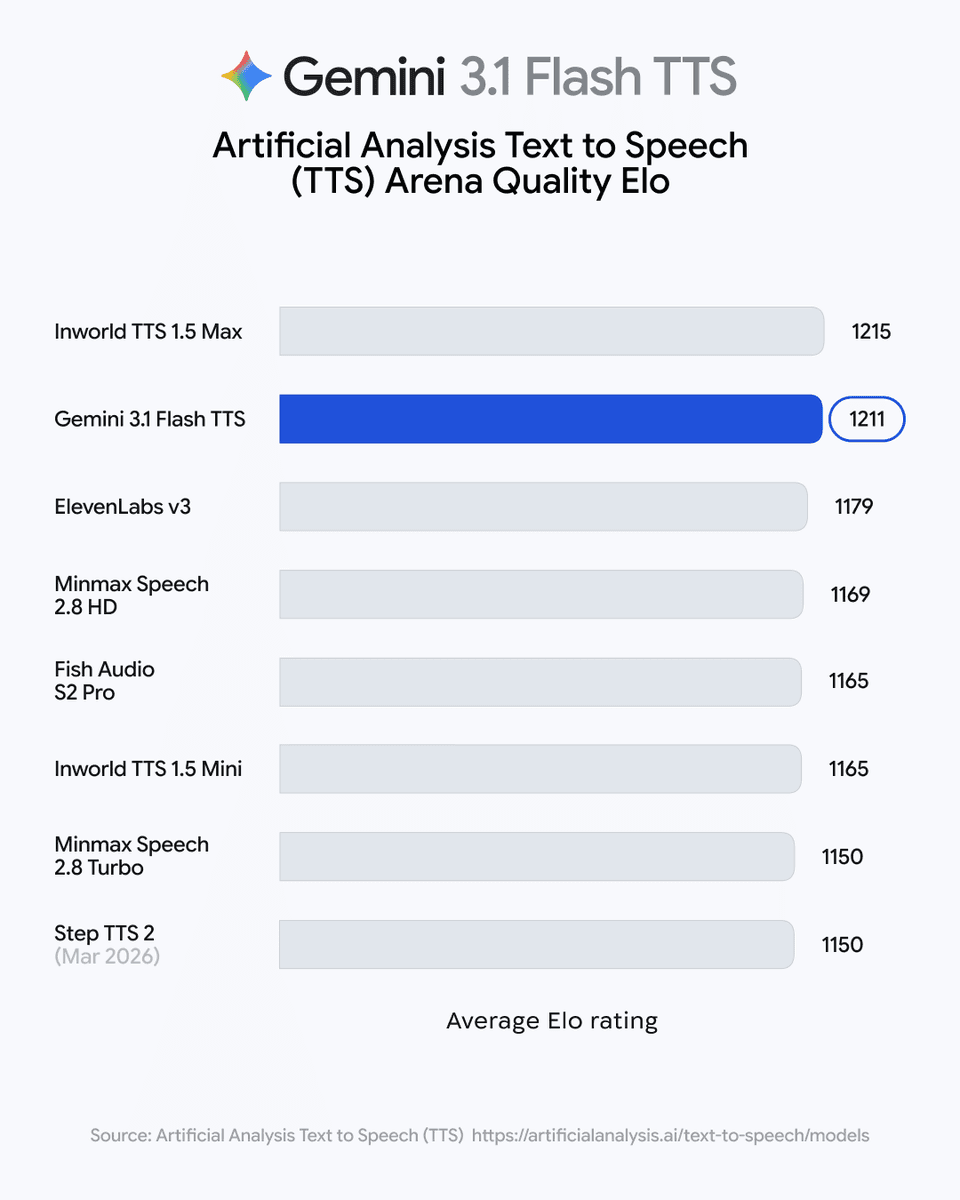
[sighs], and roughly $0.03 per 60 seconds of speech, while the model page confirms the preview model ID isgemini-3.1-flash-tts-preview. - On independent evals, Artificial Analysis ranked Gemini 3.1 Flash TTS at 1,211 Elo, four points behind Inworld TTS 1.5 Max and ahead of Eleven v3, while its follow-up numbers put it at $36.6 per million characters and 27.4 characters per second.
- Safety is part of the launch pitch: Google DeepMind and the official blog post both say every output is watermarked with SynthID.
You can hear mid-sentence style shifts in Phil Schmid's demo, poke the signed-in AI Studio playground, and read Google's own prompting guide, which goes well past "add a tag" into scene setup, character voice, and director's notes. Simon Willison's post is also worth a look because it shows the actual prompt skeleton Google expects, and it is much more theatrical than a normal TTS prompt.
Audio Tags
The core launch feature is text-side control over performance. Google says Audio Tags let you steer style, pace, and delivery directly in the transcript, and Schmid's example shows the obvious version: [asmr], then [deep and loud], then back again, all in one utterance.
The official post fills in the broader structure. In Google's announcement, Audio Tags sit alongside higher-level controls for scene direction, speaker-specific audio profiles, and director's notes, with inline tags handling local changes mid-sentence.
Google and community examples surface the same pattern repeatedly:
- global setup for scene and speaker
- per-speaker notes for tone, accent, and pace
- inline tags for momentary delivery changes
- inline non-verbal cues such as
[sighs],[laughs],[gasp], and[cough]
That is the interesting part of this launch. It pushes TTS prompting closer to script direction than to old SSML-style markup.
Access and API surface
The rollout is broader than a normal API-only preview. According to Google DeepMind, developers get preview access through the Gemini API and Google AI Studio, enterprises get preview access on Vertex AI, and Google Vids gets the consumer-facing rollout for Workspace users.
The API docs add the implementation details missing from the tweet thread. In the speech generation guide, TTS is explicitly separate from the Live API: text in, audio out, optimized for exact recitation and controllable production tasks like podcasts and audiobooks. The model card page lists text-only input, audio-only output, an 8,192 input token limit, a 16,384 output token limit, Batch API support, and no function calling, search grounding, URL context, or Live API support.
Schmid's launch thread is a useful shorthand for what ships on day one:
- 30 prebuilt voices
- multi-speaker audio with up to 2 voices
- automatic handling across 70+ languages
- no SSML and no post-processing in the advertised flow
- price claim of about $0.03 per 60 seconds of speech
Google's Cloud post adds one more concrete number. Its enterprise write-up says the model exposes 200-plus audio tags.
Leaderboard and tradeoffs
Google leaned hard on quality, and the independent numbers back up the claim. Artificial Analysis placed Gemini 3.1 Flash TTS at 1,211 Elo, just behind Inworld TTS 1.5 Max and ahead of Eleven v3. The same ranking appears in Schmid's screenshot and in Google's own post.
The tradeoff is that the model does not top the table on speed or price. Artificial Analysis' follow-up says Gemini runs at 27.4 characters per second and costs $36.6 per million characters, compared with 138 characters per second and $10 per million for Inworld TTS 1.5 Max, and 38.8 characters per second with $171.88 per million for Eleven v3.
So the launch pitch is not cheapest and not fastest. It is near-frontier quality with a much richer control surface, plus Google's usual distribution advantage across AI Studio, Vertex AI, and Vids.
Prompt anatomy
The most revealing artifact around this release is the prompting style Google is encouraging. In Google's prompting guide, the model can work from a bare transcript, but the recommended structure layers in an audio profile, a scene description, and explicit director's notes.
[Src:10|Simon Willison's blog post] shows what that looks like in practice: a prompt block with AUDIO PROFILE, THE SCENE, DIRECTOR'S NOTES, SAMPLE CONTEXT, and TRANSCRIPT, including notes like vocal smile, projection, pace, and accent. He also swapped the accent line to generate London Estuary, Newcastle, and Exeter, Devon variants from the same base script in his write-up.
That structure explains why early demos sound more like directed performances than ordinary read-aloud output. It also suggests why Google keeps using the "director's chair" framing in the product copy: the prompt has started to look like production notes, not just text to be spoken.