Z.ai releases GLM-5.2 open weights with 1M context and 46.2% DeepSWE
Z.ai released GLM-5.2 MIT-licensed open weights with 1M context and broad runtime support. Vendor and arena results put it near frontier closed models on long-horizon coding.
TL;DR
- Z.ai shipped Z.ai's launch thread with MIT-licensed open weights, a 1M context window, two reasoning settings called High and Max, and unchanged API pricing versus GLM-5.1.
- On coding and agent benchmarks, AiBattle's DeepSWE note highlighted a 46.2% DeepSWE result, while arena's Agent Arena thread placed GLM-5.2 Max at #10 overall and the top open model.
- Runtime support landed immediately across serving stacks and gateways: lmsysorg's SGLang post, vLLM's day-0 support post, OpenRouter's launch post, and Vercel's AI Gateway post all went live on day zero.
- The most concrete systems claim in the release is efficiency at 1M context: lmsysorg's summary and teortaxesTex quoting the paper both point to IndexShare cutting per-token FLOPs by 2.9x at 1M context, plus an improved MTP path for speculative decoding.
- Early hands-on reports were strong but not perfectly clean. dingyi's ZCode test said a refactor ran for five hours with little rework, while aibuilderclub's frontend test said GLM-5.2 still trails Fable 5 and Opus on one-shot polish and harder edge cases.
You can read the linked tech blog from Z.ai through the launch thread, skim Agent Arena's five-signal breakdown, and check how fast the ecosystem moved through Ollama's launch commands, Kilo Code's day-one support, and Venice's TEE/E2EE update. One of the more interesting buried details is that arena's breakdown shows a steerability drop even as task success rises, while bridgemindai's OpenRouter note says speed fell sharply once demand hit.
What shipped
The release packages four things together:
- MIT-licensed open weights, per Z.ai's launch thread
- A 1M context window, per Z.ai's launch thread
- Two reasoning effort levels, High and Max, per Z.ai's launch thread
- Same API pricing as GLM-5.1, per Z.ai's launch thread and AiBattle's pricing note
Z.ai also framed the model around long-horizon engineering work. In the launch thread, the company says GLM-5.2 was trained for large-scale implementation, automated research, performance optimization, and complex debugging. Earlier rollout posts from WesRoth's access note and WesRoth's follow-up suggest the model first appeared inside GLM Coding Plans before the broader API and open-weight rollout landed.
Benchmarks
The headline benchmark claims cluster around long-horizon coding and agent use, not general chat.
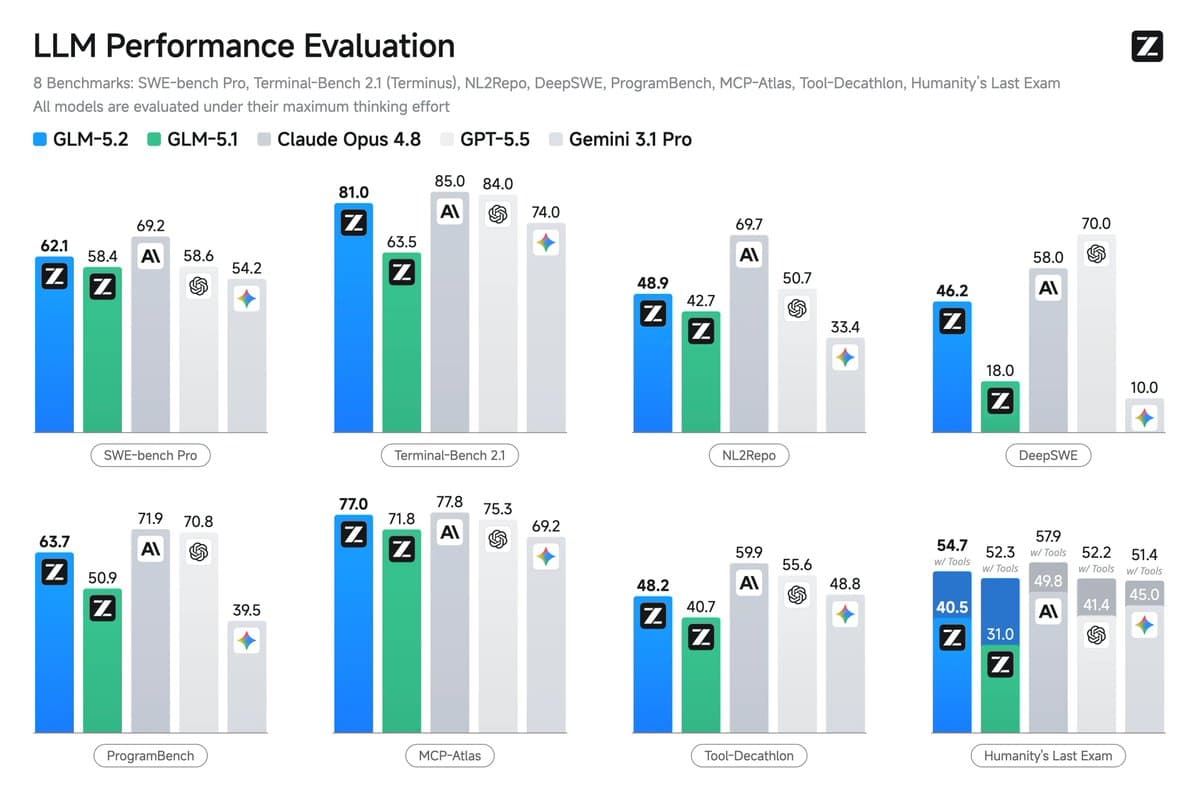
- DeepSWE: 46.2%, which AiBattle's benchmark post called the highest score reported for an open-source model.
- Agent Arena: #10 overall, up from #13 for GLM-5.1, according to arena's thread.
- Agent Arena sub-signals: arena's thread reports +9.4% on confirmed task success, +14.9% on praise vs. complaint, +1.9% on tool hallucination, +1.7% on bash recovery, and -6.0% on steerability.
- Code Arena: Frontend: #2 overall and best open model, according to arena's frontend leaderboard thread.
- Next.js evals: Vercel's eval post put GLM-5.2 at #5 overall, with 88% base and 96% with AGENTS.md.
- Terminal-Bench 2.1: lmsysorg's SGLang post cites 81.0 for GLM-5.2 versus 62.0 for GLM-5.1.
The regressions are part of the story. arena's thread says bash capabilities stayed roughly flat and steerability moved backward, which is a cleaner signal than the usual all-up-and-right launch chart.
Under the hood
The 1M window is backed by explicit systems work, not just a bigger number on the model card.
- IndexShare reuses one indexer across every four sparse attention layers, which teortaxesTex quoting the paper says reduces per-token FLOPs by 2.9x at 1M context.
- Z.ai also improved MTP, and lmsysorg's SGLang post says speculative decoding acceptance rises by up to 20%.
- Z.ai's launch thread says the long-context training focus was coding-agent reliability across implementation, research, optimization, and debugging.
Some of the sharper commentary focused on what this does and does not prove. teortaxesTex's follow-up argues the release squeezes a lot out of sparse-attention engineering, while nrehiew's architecture note points out that serving an effective 1M context is still expensive and speculates the training description may imply a fresh mid-training run rather than a small continuation from 5.1. nrehiew's PPO note also flags Z.ai's reported return to PPO for longer-horizon tasks as one of the more interesting training choices.
Where it shows up
This shipped into the tooling stack unusually fast.
- Serving and inference: SGLang, vLLM, Modular Cloud, and OpenRouter all announced support immediately.
- Gateways and hosted endpoints: Vercel AI Gateway, Baseten, Venice, and Baseten's Notion post put it on managed surfaces.
- Local and agent shells: Ollama exposed launch commands for Claude Code, Codex App, Hermes Agent, and chat; Kilo Code added day-one support; Teknium added Hermes Agent support.
- Coding tools: Cline's support post said GLM-5.2 was the first open-weights model to cross 80% on Terminal-Bench and made it available in Cline.
One useful detail is privacy positioning. Venice's launch post offered GLM-5.2 to Pro users as a private option, then Venice's follow-up added TEE/E2EE mode for cryptographically verifiable privacy.
Vibe Check
The strongest early hands-on report came from ZCode. In dingyi's ZCode test, a developer said GLM-5.2 felt better than Codex, stayed responsive, needed little rework, and still had plenty of quota left after a five-hour refactor.
Frontend and design impressions were more mixed. aibuilderclub's frontend test said the same prompt and reference image produced a solid 3D dashboard demo, but not Fable 5 level visual precision or one-shot polish, while Ethan Mollick's poem test said GLM-5.2 got the task right but lacked the thematic finesse Fable showed.
Other small tests pushed in the same direction. rohanpaul_ai's physics demo comparison said GLM-5.2 beat Kimi K2.7 Code on browser physics demos by spending more tokens on fuller simulation logic, and yacineMTB's kernel anecdote found an odd refusal pattern around CUDA kernels for B300 while the model was happy to optimize for Huawei Ascend.
The capacity story was less smooth under load. bridgemindai's OpenRouter note said launch speeds fell well below an early 300 tokens per second once demand spiked, and peakcooper's identity bug post caught one classic agent-era failure mode: GLM-5.2 insisting it was Claude until it checked the local config.
Access quirks
The post-launch experiments are already stretching past benchmark screenshots.
Venice walkthrough building a retro game with GLM-5.2 and OpenCode
Venice's prompt template reply turned that demo into a reusable single-file HTML game prompt, which is more useful than a generic "try it now" launch post. And HCSolakoglu's Linux download note found ZCode 3.1.0 Linux builds sitting on Zhipu's CDN behind a still-misaligned website flow, with direct .deb and AppImage downloads already available.