NVIDIA launches Cosmos 3 open 16B and 64B omnimodels with datasets and SGLang support
NVIDIA released Cosmos 3 as an open omnimodel family with 16B and 64B variants, plus code, datasets, and a coalition around physical AI. The release matters because it ships with serving support and top open-weight image and video rankings, so teams can use it beyond a research teaser.
TL;DR
- NVIDIA shipped Cosmos 3 as an open physical AI model family with 16B Nano and 64B Super variants, and cedric_chee's repost of NVIDIAAI says the release includes weights and post-training recipes.
- According to TheTuringPost's explainer, Cosmos 3 folds scene understanding, future-state generation, and action generation into one system, while Hugging Face's launch post says earlier Cosmos releases split those jobs across separate models.
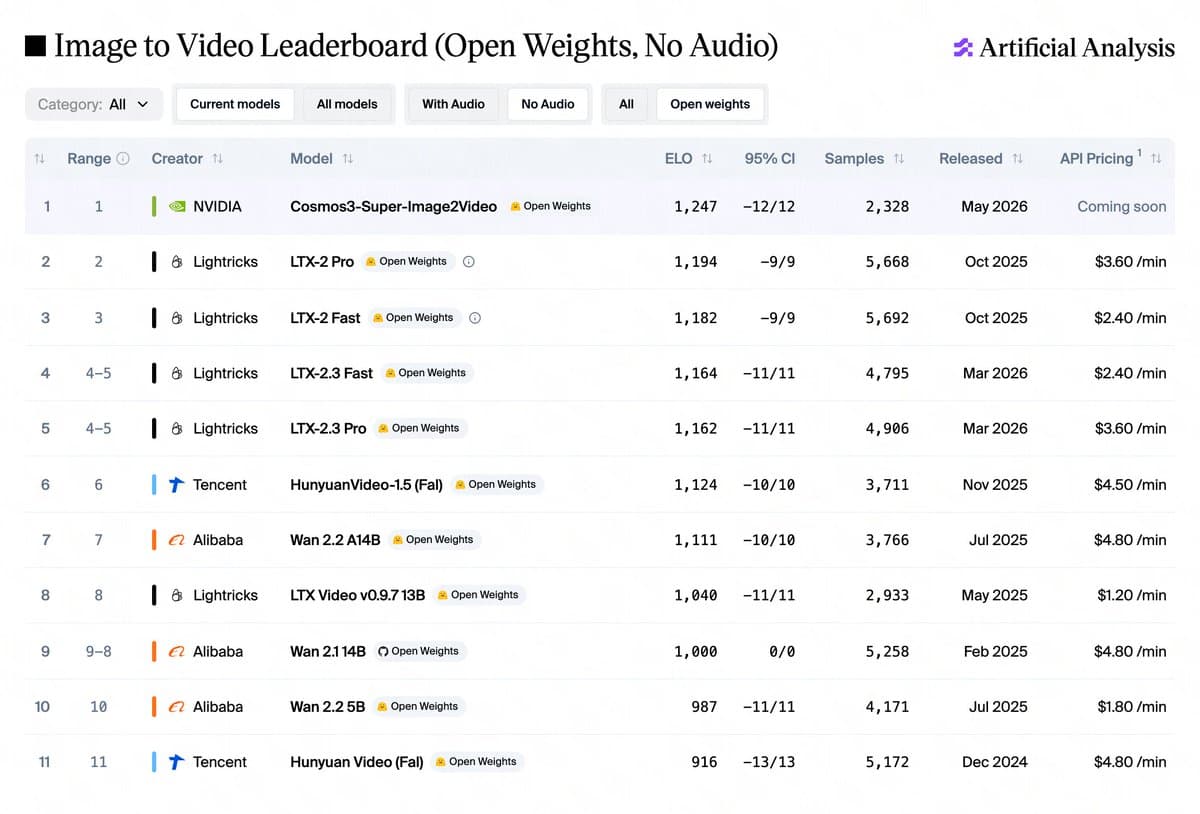
- ArtificialAnlys said Cosmos 3 took the top open-weights spots on its text-to-image and image-to-video leaderboards, and lmsysorg shipped day-one SGLang-Diffusion support for the generator checkpoints.
- mervenoyann's link roundup points to the Hugging Face collection and launch post, while NVIDIA's technical blog says the drop also includes open datasets, GitHub code, and NIM deployment paths.
- kimmonismus said NVIDIA paired the model release with a Cosmos Coalition that includes Runway, Black Forest Labs, Skild AI, Agile Robots, LTX, and Generalist.
You can browse the Hugging Face collection, read NVIDIA's main launch post and technical blog, check the SGLang cookbook, and hit live endpoints on fal text-to-image or fal image-to-video. The weirdly useful detail is that Cosmos 3's generators expect structured JSON-style prompting, so both ArtificialAnlys and fal's docs route ordinary prompts through an upsampling harness first.
One model, two towers
The core pitch is simple: Cosmos 3 merges three stages that physical AI stacks usually split apart.
- Reasoning over the current scene
- Generating plausible future world states
- Generating actions for a robot or agent
According to Hugging Face's architecture writeup, the model uses a Mixture-of-Transformers backbone with modality-specific encoders feeding a shared representation. The same post says Cosmos 3 runs two subsequences inside one architecture, an autoregressive path for reasoning and understanding, and a diffusion path for generation.
NVIDIA's main launch post frames this as a model that can move from interpreting a scene to producing synthetic video or robot trajectories without swapping systems. TheTuringPost's summary describes the same split as a Reasoner Tower plus a Generator Tower.
Open stack, not just weights
The release is broader than a checkpoint dump. NVIDIA's technical blog says Cosmos 3 ships with:
- Nano and Super checkpoints on Hugging Face
- GitHub code and post-training scripts
- Open synthetic data generation datasets for robotics and autonomous driving
- NIM microservices for deployment on NVIDIA GPUs
Model sizing is split cleanly. Hugging Face's launch post says Nano is a 16B model with an 8B reasoner and 8B generator, designed for workstation-class hardware like RTX PRO 6000, while Super is a 64B model with 32B reasoner and 32B generator, aimed at Hopper and Blackwell deployments.
The same NVIDIA technical post says six synthetic data generation datasets are part of the release. cedric_chee's repost of NVIDIAAI adds that NVIDIA is treating the post-training recipes as open too, which is the part most model releases quietly skip.
Leaderboards and serving support
The most immediately usable part of the launch is that Cosmos 3 already has serving support outside NVIDIA's own stack. lmsysorg announced SGLang-Diffusion support the same day, and the SGLang cookbook lists four supported generator checkpoints:
nvidia/Cosmos3-Nanonvidia/Cosmos3-Supernvidia/Cosmos3-Super-Text2Imagenvidia/Cosmos3-Super-Image2Video
That same cookbook also draws a line around what is not there yet. SGLang says video with sound, video-to-video conditioning, and action generation are unsupported today, and the Cosmos3-Nano-Policy-DROID action model is planned separately. For the 64B checkpoint, the doc recommends multi-GPU serving.
On quality claims, ArtificialAnlys said the specialized Super checkpoints ranked first among open-weights models on its text-to-image and image-to-video leaderboards. The post also notes that the listed text-to-image result uses an agentic prompt-upsampling harness, not plain raw prompting.
Coalition and license
NVIDIA paired the model drop with ecosystem scaffolding. kimmonismus said the new Cosmos Coalition includes Black Forest Labs, Runway, Skild AI, Agile Robots, LTX, and Generalist, and c_valenzuelab confirmed Black Forest Labs is participating.
The licensing move matters too. WesRoth noted that NVIDIA is adopting the Linux Foundation's OpenMDW framework across its open model families, and NVIDIA's launch post says OpenMDW 1.1 is meant to cover weights, architecture, documentation, and evaluation artifacts under one model-centric license.
That combination, coalition on one side and a standardized license on the other, makes this look more like platform-building than a one-off research release. ClementDelangue put the broader backdrop bluntly, calling NVIDIA the "King of American Open-source AI" after the company crossed 1,000 public Hugging Face repositories.
APIs and pricing
Cosmos 3 showed up on inference surfaces fast. fal put Cosmos3-Super live less than a day after launch, and fal's follow-up linked public text-to-image and image-to-video endpoints.
Fal's model pages expose a few practical details NVIDIA's launch materials do not. The text-to-image endpoint is priced at $0.04 per generated image, plus $0.02 per request when prompt expansion is enabled. The image-to-video endpoint is priced at $0.05 per second, and both pages say agentic generation bills for every candidate output, not just the final one.
Those pages also make the harness visible. Fal says prompt expansion rewrites user text into the dense structured JSON format Cosmos 3 was trained on, and the image-to-video endpoint uses the Cosmos3-Nano Reasoner to do it by default. That matches ArtificialAnlys, which said prompt upsampling is needed to reproduce its leaderboard results.